Recommendation: If you like this post, be sure to also check out this, even better, post!
The new gold or blue internet debate is about a new audio clip which sounds like Yanny to some people and Laurel to others. Various explanations have been given such as the audio quality of your headset or speakers and the age of the person listening (with the hypothesis that older people have trouble hearing the higher frequencies of the recording and therefore hear something else than younger people).
So let's take a listen to the audio in question. Here it is: yanny-laurel.mp4
When I play this on my desktop computer with my headset, I hear Yanny. However, listening to the same audio on my phone speaker I hear Laurel, so the audio characteristics of the rendering device do play a role.
Now let's experiment in the Wolfram Language with this audio file. This will Import the file:
audio = Import["yanny-laurel.mp4"]
The output is an interactive audio control, which lets you play the sound:
You can take a look at the Spectrogram of the audio, to see the frequency distribution over time:
Spectrogram[audio]
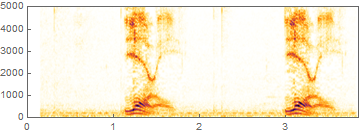
This makes it visually clear that the utterance (Yanny or Laurel) is repeated once in the file.
You can change the pitch of the audio with AudioPitchShift, which either compresses or stretches the frequencies by a factor 'r':
audios = Table[AudioPitchShift[audio, r], {r, 0.5, 1.5, .1}]
If you listen to the compressed audio, you end up hearing Yanni, but the stretched audio sounds like Laurel.
We can join the audio snippets together with AudioJoin, so we can listen to them in sequence (forward or in reverse):
a1 = AudioJoin[audios];
a2 = AudioJoin[Reverse[audios]];
Here are the two files: a1.wav and a2.wav
Interestingly enough, if you listen to a1.wav (compressed to stretched) it starts out sounding like Yanni almost to the end, but if you listen to a2.wav (stretched to compressed) it starts out sounds like Laurel almost to the end! The human brain seems to want to cling to what it heard just previously, so the context of what you hear matters (a lot)!!!
 Attachments:
Attachments:


