
Goal
There are many ways to generate music and one of them is algorithmic, where music is generated with the help of a list of handcrafted rules.
The approach in this project is different - I build a neural network that knows nothing about music but learns it from thousands of songs given in MIDI format.
Apart from just generating a meaningful sequence of notes I also wanted to add dynamics in loudness and humanlike mistakes in timing with no restrictions for note durations.
Why dynamics and timing?
There is no human who is able to play on a musical instrument with precisely the same loudness and strictly in time with a metronome(at least I can't). People do mistakes, but in the case of music, they are helping in creating what we call more alive music. It is a fact that dynamic music with slight time shifts sounds more interesting, so even when you write music in a program you supposed to add these "mistakes" by yourself.
Why performances?
The dataset that I use for the project contains performances of Yamaha e-piano competition participants. This gives us a possibility to learn the dynamics and mistakes in timings.
Here's an example generated by the model.
All the code, data and trained models can be found on GitHub.
The examples will be attached to this post as files just in case.
Inspiration
This is not an original work and mostly it's an attempt to recreate the work of Magenta team from their blog post.
Nevertheless, in this post, I will try to add more details to the preprocessing steps and how you can build a similar neural network model in Wolfram Language.
Data
I've used a site that has the Yamaha e-piano performances but also contains a set of classic and jazz compositions.
In the original work Magenta team has used only the Yamaha dataset but with a heavy augmentation on top of that: Time-stretching (making each performance up to 5% faster or slower), Transposition (raising or lowering the pitch of each performance by up to a major third).
Also, you can create your own list of MIDI files and build a dataset with the help of the code provided below in the post.
Here are links to find a lot of free MIDI songs: The Lakh MIDI Dataset(very well prepared a dataset for ML projects), MidiWorld and FreeMidi
MIDI
MIDI is short for Musical Instrument Digital Interface. Its a language that allows computers, musical instruments, and other hardware to communicate. MIDI carries event messages that specify musical notation, pitch, velocity, vibrato, panning, and clock signals (which set tempo).
For the project, we need only events that denote where is every note starts/ends and with what are velocity and pitch.
Preprocessing The Data
Even though MIDI is already a digital representation of music, we can't just take raw bytes of a file and feed it to an ML model as in the case of the models working with images. First of all, images and music are conceptually different tasks: the first is a single event(data) per item(an image), the second is a sequence of events per item(a song). Another reason is that raw MIDI representation and a single MIDI event itself contain a lot of irrelevant information to our task.
Thus we need a special data representation, a MIDI-like stream of musical events. Specifically, I use the following set of events:
- 88 note-on events, one for each of the 88 MIDI pitches of piano range. These events start a new note.
- 88 note-off events, one for each of the 88 MIDI pitches of piano range. These events release a note.
- 100 time-shift events in increments of 10 ms up to 1 second. These events move forward in time to the next note event.
- 34 velocity events, corresponding to MIDI velocities quantized into 32 bins. These events change the velocity applied to subsequent notes.
The neural network operates on a one-hot encoding over these 310 different events. This is the very same representation as in the original work but the number of note-on/note-off is fewer, I encode 88 notes in piano range instead of 127 notes in MIDI pitch range to reduce one-hot encoding vector size and make the process of learning easier.
For example, if you want to encode 4 notes from C major with durations of a half second and with different velocities your sequence of events would be somewhat like this(for clarity I use only indices instead of the whole one-hot encoding):
{288, 60, 226, 148, 277, 62, 226, 150, 300, 64, 226, 152, 310, 67, 226, 155} 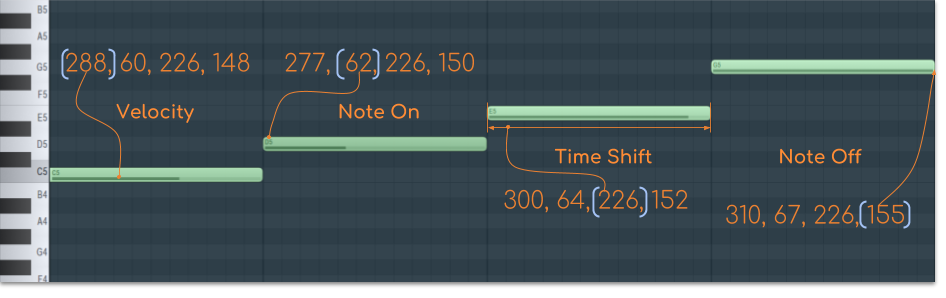
In this particular example:
- 60, 62, 64, 67 are note on events(C5, D5, E5, G5). Values in a range from 1 to 88.
- 148, 150, 152, 155 are note off events. Values in a range from 89 to 176.
- 226 is a half second time shift event. Values in a range from 177 = 10 ms to 276 = 1 sec.
- 288, 277, 300, 310 are velocity events. Values in a range from 277 to 310.
In this way, you can encode music that is expressive in dynamics and timing.
Now, let's take a look on another example with a chord from the same notes but with different durations:
{300, 60, 62, 64, 67, 226, 152, 155, 226, 150, 226, 148} 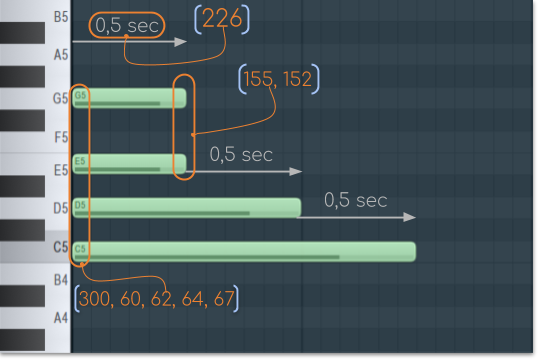
As you can see, if you want to play more than one note at once you just need to put them in a single bunch of note-on events(60, 62, 64, 67).
Then you add time shift and note-off events as you needed. If you need a duration longer than 1 sec you can stack together more than one time-shift events({310, 310} = 2 sec time-shift).
WL and MIDI
Wolfram Language has a built-in support of MIDI files what is really simplifying initial work.
To get data from MIDI file you need to import it with specific elements: 
In the code below I also extract and calculate needed information related to a tempo of a song.
{raw, header} = Import[path, #]& /@ {"RawData", "Header"};
tempos = Cases[Flatten[raw], HoldPattern["SetTempo" -> tempo_] :> tempo];
microsecondsPerBeat = If[Length@tempos > 0, First[tempos], 500000]; (* If there is no explicit tempo we use default 120 bpm *)
timeDivision = First@Cases[header, HoldPattern["TimeDivision" -> division_] :> division];
(* Convert timeDivision value to base of 2 *)
timeDivisionBits = IntegerDigits[timeDivision, 2];
(* Pad zeros at the beginning if the value takes less then 16 bits *)
timeDivisionBits = If[Length@timeDivisionBits < 16, PadLeft[timeDivisionBits, 16], timeDivisionBits];
(* The top bit responsible for the type of TimeDivision *)
timeDivisionType = timeDivisionBits[[1]];
framesPerSecond = timeDivisionBits[[2 ;; 8]];
ticksPerFrame = timeDivisionBits[[9 ;; 16]];
ticksPerBeat = If[timeDivisionType == 0, timeDivision, 10^6 /(framesPerSecond * ticksPerFrame)];
secondsPerTick = (microsecondsPerBeat / ticksPerBeat) * 10^-6.;
An example of raw data and header info from MIDI file in Wolfram Language:
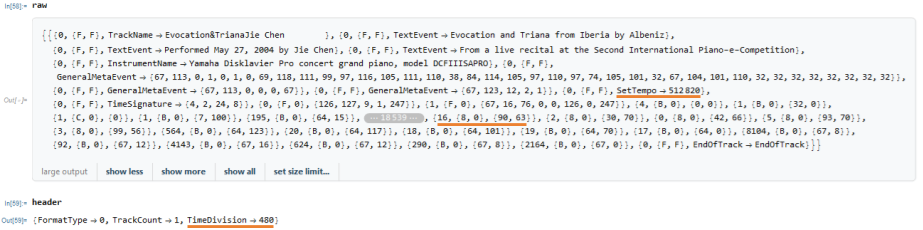
SetTempo is a number of microseconds per beat(microseconds per quarter note).
Time Division has two type of interpreting. If the top bit is 0 then the type is "ticks per beat" (or pulses per quarter note) otherwise, the type is "frames per second". We need those two values to calculate time per one MIDI tick that used in MIDI events as a time measurement.
One MIDI event in WL representation looks like this
{56, {9, 0}, {46, 83}}
- 56 is a number of MIDI ticks that means the total amount of time that must pass from the previous MIDI event.
It represents our time-shift event by simple multiplication of this number with secondsPerTick.
- 9 is a status byte of MIDI events(9,8 are note-on, note-off respectively).
- 0 is MIDI channel(irrelevant for us).
- 46 indicates what is a pitch of this note(related to note-on/note-off events).
- 83 is a number we encode in a velocity event.
If you want to understand how a real raw MIDI data structured, this blog is specifically useful.
Now, what we need is to parse a sequence of MIDI events and filter them only for events that are note-on, note-off and all the events that have the number of MIDI ticks greater than 0. Some of the meta-messages have irrelevant MIDI ticks thus we need to exclude them from final sequence - we just skip the events with value F(Meta message) in the MIDI status byte.
After filtering MIDI data you get a sequence that is ready to be encoded to the final representation and will be fed to the model. 
To encode the sequence of MIDI events to the final representation I use the code below:
EncodeMidi[track_, secondsPerTick_] := Block[{lastVelocity = 0},
ClearAll[list];
Flatten[
Map[
Block[{list = {}},
(* Add time shifts when needed *)
If[TimeShiftByte[#, secondsPerTick] > 0, list = Join[list, EncodeTimeShift[TimeShiftByte[#, secondsPerTick]]]];
(* Proceed with logic only if it's a note event *)
If[StatusByte[#] == NoteOnByte || StatusByte[#] == NoteOffByte,
(* Add velocity if it's different from the last seen *)
If[lastVelocity != QuantizedVelocity[VelocityByte[#]] && StatusByte[#] == NoteOnByte,
lastVelocity = QuantizedVelocity[VelocityByte[#]];
list = Join[list, List[EncodeVelocity[VelocityByte[#]]]];
];
(* Add note event *)
list = Join[list, List[EncodeNote[NoteByte[#], StatusByte[#] == NoteOnByte]]];
];
(* Return encoded list*)
list
]&,
track]
, 1]];
This code has a lot of functions that I've written during the summer school but they are mostly utility short functions. You can check them and complete implementation on GitHub.
When the code for the preprocessing is ready it's time to build a dataset.
Building Dataset
I've made a notebook that takes care of preprocessing of MIDI files and encode them into the final representation.
(* Take all files names in Midi folder *)
files = FileNames["*", NotebookDirectory[] <> "Midi"];
dataset = Flatten[EncodeTrack /@ files, 1];
During the encoding, each track is partitioning into smaller segments:
encodings = Partition[EncodeMidi[GetMidiEvents[raw, secondsPerTick], secondsPerTick], 500];
In the original work, Magenta team split each song into 30-second segments to keep each example of manageable size. The problem is that partition by equal time doesn't give you the equal size of examples. Even though you can use varying input size in sequence models I wanted to use a static size of examples to speed up the training process. I was told that internally in WL(or maybe everywhere) it's more efficient to have the same size of every example for a model.
However, I believe this kind of partition has a drawback, in a way that an equal number of encoded events could have a different duration in time thus adding inconsistency in the dataset.
In my case, I've divided each song into segments of 500 encoded events. 
To reduce the size of the final dataset I use only indices for one-hot encodings.
As the result, the final dimension of my dataset was {99285, 500}
If you want to try partition by the time you need to edit EncodeTrack function in Midi.m.
With this code, you will find positions of where to split a sequence on equal time segments:
GetTimePositions[track_, seconds_, secondsPerTick_] :=
Block[{positions = {}, time = 0},
Do[
time = time + track[[i]][[1]] * secondsPerTick;
If[time > seconds, positions = Append[positions, i]; time = 0;],
{i, Length@track}];
positions
]
Where parameter track is a sequence of MIDI events. Then you split the same track with the positions you've got from the function.
segments = FoldPairList[TakeDrop, track, positions];
After that, you need to encode segments with the help of EncodeMidi function. If you do that there is one thing left - rework the model to accept varying input size but the next part will cover how to build a model with a static size of example.
Building a Model
Because music data is a sequence of events we need an architecture that knows how to remember, and predicts what is the next event based on all previous. This is exactly what Recurrent Neural Networks try to do - RNNs can use their internal state (memory) to process sequences of inputs. If you want to check more details I would recommend to watch this introduction video.
On the abstract level, RNN learns the probabilities of events that follow after each other. Take for example this language model from Wolfram Neural Repository, it predicts the next character of a given sequence.
NetModel["Wolfram English Character-Level Language Model V1"]["hello worl"]
The output is d.
You can get top 5 probabilities if you want.
NetModel["Wolfram English Character-Level Language Model V1"]["hello worl", {"TopProbabilities", 5}]
You will get:
{"d" -> 0.980898, "e" -> 0.00808785, "h" -> 0.0045687, " " -> 0.00143807, "l" -> 0.000681855}
In my work, I needed similar behavior but instead of characters, I wanted to predict encoded MIDI events. That is why the basis of the model I build is Wolfram English Character-Level Language Model V1. Also, after reading a guide about sequence learning with neural networks in WL I've decided to improve the training process with "teacher forcing" technique.
Teacher Forcing
In a simple language model, a model takes the last prediction from an input sequence and compute the class of it. But for "teacher forcing" we need to get classes of all predictions.

Comparatively to the language model I've removed one GatedReccurentLayer and Dropoutlayer due to the not so big dataset(as precautions to avoid overfitting). Another benefit of using "teacher forcing" is that you don't need to separately create labels for every example. To compute the loss we make out of an input example two sequences:
- Everything but the last element(SequenceMostLayer)
- Everything but the first element(SequenceRestLayer)
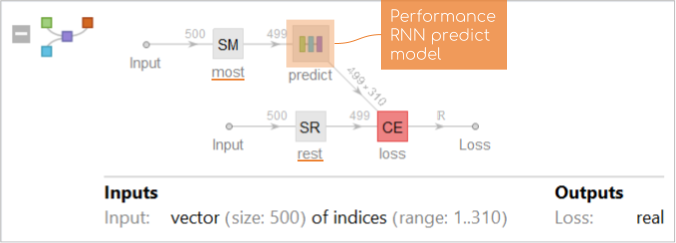
As you can notice the input is only one vector of indices with size 500 and labels for computing the loss are generating inside of a NetGraph. Here is a visualized example of the flow with simple input:
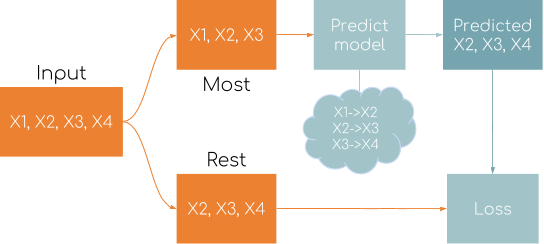
You can find the code for creating the model in this PerfrormanceRnnModel notebook. After all the data is ready and the model is finalized we can start training.
NetTrain[teacherForcingNet,
<|"Input" -> dataTrain|>,
All,
TrainingProgressCheckpointing -> {"File", checkPointDir, "Interval" -> Quantity[5, "Minutes"]},
BatchSize -> 64,
MaxTrainingRounds -> 10,
TargetDevice -> "GPU", (* Use CPU if you don't have Nvidia GPU *)
ValidationSet -> <|"Input" -> dataValidate|>
]
A friendly advice - it's better to use "Checkpoining" during the training. This will keep your mental health safe and will work as assurance that all training progress is saved.
I was training the model 30 rounds and it took around 4-5 hours on AWS' GPUs. First 10-15 rounds weren't showing any sight of problems but later training clearly started to overfit. 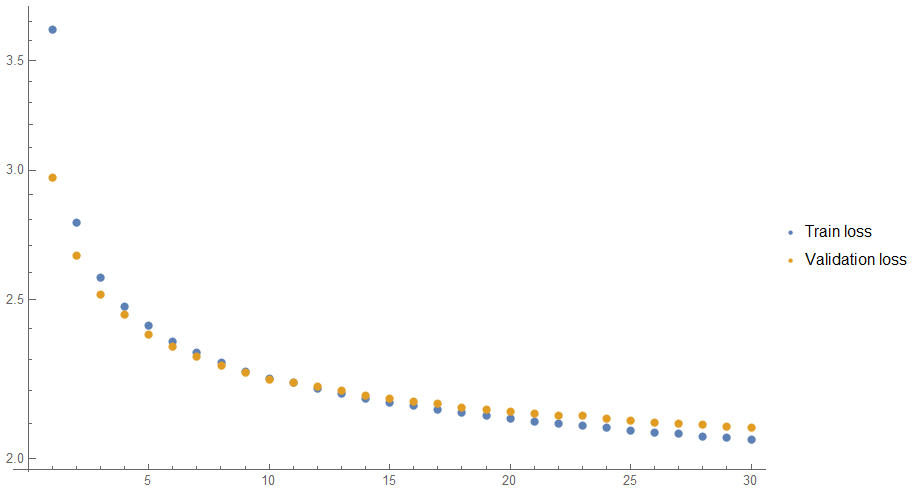
Unfortunately, I haven't had time to fix this problem because of the limited time but to overcome this problem I might reduce the size of GRUs from 512 to 256 and return Dropout layer.
Generate Music
To generate music we need a model that predicts the next event in a sequence as it was in the language model. To do that I take the trained model and extract out of it "PerformanceRNN Predict Model" part.
predictNet = NetExtract[trainedNet, "predict"];
Next step is to convert this predictNet to a model that takes varying input size and return the class of the next event.
generateModel = NetJoin[NetTake[predictNet, 3], {
SequenceLastLayer[],
NetExtract[predictNet, {4, "Net"}],
SoftmaxLayer[]},
"Input" -> Automatic,
"Output" -> NetDecoder[{"Class", Range[310]}]
]
The resulting architecture is pretty the same as the language model from which I've started - it takes a sequence with varying size of encoded MIDI events {177, 60, 90} and predicts what could be next event {177, 60, 90, ?}.

Now, let's the fun begin!
generateDemo[net_, start_, len_] := Block[{obj = NetStateObject[net]},
Join@NestList[{obj[#, "RandomSample"]} &, start, len]
]
This small function is all we need to generate a sequence of the desired length.
NetStateObject helps to keep track of all sequences that were applied to the network, meaning every next prediction is the result of all previous events not only the recent one.
start should be a sequence of encoded MIDI events. It also can be a single item sequence, say you want to start from a pause or a particular note. This is a possibility to some extent put the generation process in a particular direction.
Okay, two lines of code left and you can hear play with generating of music:
generatedSequence = Flatten[generateDemo[generateModel, {60, 216, 148, 62, 200, 150, 64, 236, 152, 67, 198, 155}, 500]];
ToSound[generatedSequence]
These are other examples: 2, 3.
You can generate your own demos if download repository and open PerformanceRNN notebook.
Further Work
That was a very fun and challenging task for me. I can't say that I'm satisfied with the results but this a good start and I have a direction now. What I want to explore is Variational Autoencoder, especially MusicVAE that is made by the same Magenta team.
However, I'll start with improving the existing model by changing the architecture and cleaning the dataset to have only performances from the Yamaha dataset.
Thank you for reading the post, and feel free to ask any questions.

 Attachments:
Attachments:


