
Hi! My name is Jacob. My WSC18 project, you can see, is of no practical value, so I hope it instead stands as a hilarious and intuitive icebreaker of an introduction to what one can do with machine learning, as it was for me.
Why does Paolo have an odd gray blob on his head?
The question that started all this funny business: can a neural network predict what kind of hair someone has based on their facial features?
The initial thesis was that, even considering the infinity of things that make someone's hair at any moment, there must be a correlation between face and hair -- however slight -- and that we'd be able to answer the above question with enough data. A neural network is no way to support this, though, and we found it easier to pitch the idea as predictor of someone's hair based on what other people who look like them have.
So: the reason why Paolo has an odd gray blob on his head is that we're trying to peer-pressure him into styling his hair the way the wisdom of the crowd says he ought to... using a generative neural network trained on tens of thousands of faces. That kind of peer-pressure.
Overview
To have a neural network to predict a hairstyle from a face (hereafter referred to as "HairPredNet"), we need input and output training data: faces and hair, respectively. The problem is that there exists no massive database of faces and their corresponding hairstyles; I had to generate my own input and output.
Hundreds of millions of photos containing both face and hair have been made accessible on the internet, and my job was to find a way to separate them. This required training a segmentation network (hereafter referred to as "HairSegNet"), which was made infinitely easier by my finding a quality database of images of hair and their corresponding segmentations under Figaro1k.
In short, I was able to generate an unlimited amount of training data for HairPredNet by using HairSegNet, trained on Figaro1k, on any headshot image I could find.
Code
HairSegNet
The process of acquiring raw training data was a matter of downloading Figaro1k. I cropped each image -- input photo and output hair mask -- to 512x512 to keep my data consistently scaled.
Crop[b_] := ImageCrop[ImageResize[b, {512}], {512, 512}]
I imported the neural net architecture "Pix2pix Photo-to-Street-Map Translation" uninitialized for building HairSegNet on. This was done at the suggestion of mentor Rick, who explained that it's an architecture suited for generating output images from elements extracted from input images.
HairSegNet1 =
NetTrain[pix2pixTrain, <|"Input" -> FigaroIn,
"Output" -> FigaroOut|>, MaxTrainingRounds -> 3]
HairSegNet, after being trained on all of 1,050 Figaro1k data, returned useful results and could safely be described as decent, but not as being at an acceptable level for generating thousands of HairPredNet training data from. The reliability of the prediction would depend on the segmentation.
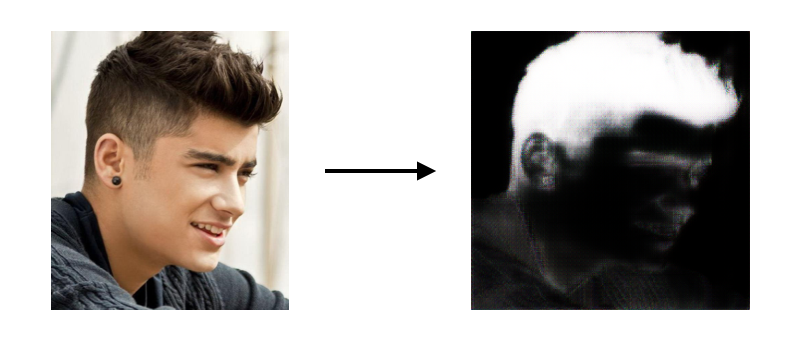
Data augmentation was in order. My methods were horizontal flips, gaussian fuzz, and a combination of the two.
FigaroInFlip = (ImageReflect[#, Left]) & /@ FigaroIn;
FigaroInFuzz= (ImageEffect[#, {"GaussianNoise", 0.25}] &) /@ FigaroIn;
FigaroInFuzzFlip = (ImageEffect[#, {"GaussianNoise", 0.25}] &) /@
FigaroInFlip;
I manually added ~50 images of completely bald heads to the initial dataset of 1050. It was no problem to generate output data: ~50 completely black squares, as these images have no hair to segment. This was augmented as well.
HairSegNet2 =
NetTrain[pix2pixTrain, <|"Input" -> MassiveIn,
"Output" -> MassiveOut|>, MaxTrainingRounds -> 3]

Applying DeleteSmallComponents[Binarize[]] I was able to clean up segmentations.

HairPredNet
We saw earlier that training a network to predict hairstyle would entail finding input faces and their corresponding hairs. We can take hairs from any portrait now with HairSegNet; we now need a way to take faces. Wolfram has an in-built function called FindFaces that, upon being applied to an image containing a face, returns the coordinates of a rectangle containing the face. Using this, I wrote a function to crop a portrait image to one containing only the bounds of that face-rectangle.
FaceTake[image_] :=
Module[{croppedimage, facebox, chinfacebox, rectangleareas,
rectanglenumber},
croppedimage = Crop[image];
rectangleareas = Area /@ FindFaces[croppedimage];
rectanglenumber = Position[rectangleareas, Max[rectangleareas]];
facebox =
List @@ FindFaces[croppedimage][[rectanglenumber[[1, 1]]]];
chinfacebox =
ReplacePart[
facebox, {{2, 2} -> facebox[[2, 2]] - 25, {1, 2} ->
facebox[[1, 2]] - 25}];
Crop[ImageTrim[croppedimage, chinfacebox]]
]
![Demonstration of FaceTake[]](http://community.wolfram.com//c/portal/getImageAttachment?filename=ScreenShot2018-07-13at4.54.12PM.png&userId=1372129)
I collected face data using function WebImageSearch[] on both Google and Bing, which returned ~1000 images of dubitable quality. My main source of data was Labeled Faces in the Wild, a collection of 13000 faces, most of which contain all of the subject's hair.
I called HairSegNet[] and FaceTake[] on the 13000 images to use as input and output, respectively. I took "Pix2pix Photo-to-Street-Map Translation " again as my architecture.
NetTrain[pix2pixinitialized,<|"Input" -> lfwFaces,"Output" -> lfwHair|>,TargetDevice -> "GPU",MaxTrainingRounds -> 3]

Manipulated predictions are somewhat sharper.

Looking forward
A better suited architecture for the task than Pix2pix (in all its excellence) surely would have returned sharper results for either of the segmentation or prediction.
Many thanks to Michael Kaminsky for guiding me through this. It's cool!


