Introduction
Hello Wolfram community! My name is Ryan Heo and I am a student at the Wolfram high school summer camp where over the past two weeks I was able to work on and complete a project called "Voice Sentiment classification". The goal of this project was to be able to take an input of an audio speech file and be able to classify that into one of the 8 different categories of emotion using machine learning. Down below is are the steps and the procedure I followed in the completion of my project.
Dataset
For this project I used the Ryerson Audio-Visual Database of Emotional Speech which consisted of varying tones or emotion of speech recordings from voice actors.Down below is the importation of the speech audio files that I have downloaded
folders = Select[FileNames["*", NotebookDirectory[]],
DirectoryQ[#] && StringContainsQ[#, "Actor"] &];
fileNames = FileNames["*.wav", #] & /@ folders // Flatten;
audio = Import /@ fileNames;
Encoding the data
After I have imported all the data files I took extracted the number section of the file name that matches the different emotion categories. I then separated these numbers into eight sections which corresponded with the emotional category of these files. Additionally, I threaded these sections to their corresponding emotion and after flattening the list and random sampling the data I inserted the data into the net encoder. I converted the data into a mel-frequency cepstrum which is based on the log power spectrum and does a better job modeling the human auditory system than the a normal cepstrum. In the net encoder I set my sampling rate and the number of filters I had to a high number in order to create more data points and to be able to extract more features respectively.
enc = NetEncoder[{"AudioMelSpectrogram", "WindowSize" -> 4096,
"Offset" -> 1024, "SampleRate" -> 44100, "MinimumFrequency" -> 1,
"MaximumFrequency" -> 22050, "NumberOfFilters" -> 128}] ;
After encoding the data I separated it into sections consisting of length 41 and reshaped the array to be inputted into neural net for training. Down below is a representation of the mel spectrogram represented by a matrix plot 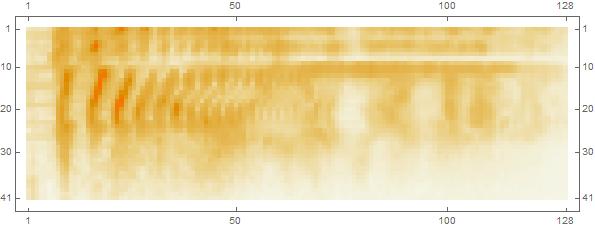
Neural Networks
I used a combination of a convolutional neural network and a recurrent network for classification. Down below is the convolutional neural network architecture that I used
convNet = NetChain[
{
conv[32],
conv[32],
PoolingLayer[{3, 3}, "Stride" -> 3, "Function" -> Max],
BatchNormalizationLayer[],
Ramp,
conv[64],
conv[64],
PoolingLayer[{3, 3}, "Stride" -> 3, "Function" -> Max],
BatchNormalizationLayer[],
Ramp,
conv[128],
conv[128],
PoolingLayer[{3, 3}, "Stride" -> 3, "Function" -> Max],
BatchNormalizationLayer[],
Ramp,
conv[256],
conv[256],
PoolingLayer[{3, 3}, "Stride" -> 3, "Function" -> Max],
BatchNormalizationLayer[],
Ramp,
LinearLayer[1024],
Ramp,
DropoutLayer[0.5],
LinearLayer[8],
SoftmaxLayer[]
},
"Input" -> {1, 41, 128},
"Output" -> NetDecoder[{"Class", newClasses}]
]
This is the architecture for the recurrent network with LSTM layers
recurrentNet = NetChain[{
LongShortTermMemoryLayer[128, "Dropout" -> 0.3],
LongShortTermMemoryLayer[128, "Dropout" -> 0.3],
SequenceLastLayer[],
LinearLayer[Length@newClasses],
SoftmaxLayer[]
},
"Input" -> {"Varying", 8},
"Output" -> NetDecoder[{"Class", newClasses}]
]
I then combined these two nets
netCombined = NetChain[{
NetMapOperator[cnnTrainedNet],
lstmTrained
}]
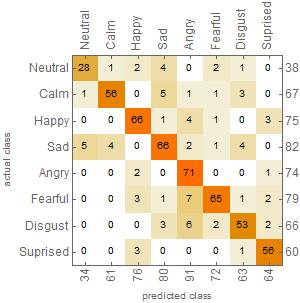
I inputted the section of the dataset files I reserved for testing and validation and inputted these files into the combined neural net achieving an accuracy of 85 percent.Down below would be a good representation of how accurate my net was in in classifying these files into their respective emotional categories.
For example in the neutral category out of the 38 samples of the randomly distributed data it was able to correctly match these files into neutral 28 times. As shown below the net seems to confuse the neutral emotion with the sadness emotion as seen by guessing sad 4 times out of 38 files.
Deploying the Microsite
MicroFunc[aud_Audio] := Module[{net, enc},
net = Import[CloudObject[
"https://www.wolframcloud.com/objects/ryanheo2001/CombinedNet.\
wlNet"], "WLNET"];
enc = NetEncoder[{"AudioMelSpectrogram", "WindowSize" -> 4096,
"Offset" -> 1024, "SampleRate" -> 44100, "MinimumFrequency" -> 1,
"MaximumFrequency" -> 22050, "NumberOfFilters" -> 128}];
net[Transpose[{Partition[enc[aud], 41]}, {2, 1, 3, 4}]]
]
CloudDeploy[
FormPage[{"Audio" -> "CachedFile" -> "", "URL" -> "URL" -> ""}, Which[
#Audio =!= "", MicroFunc[Audio[#Audio]],
#URL =!= "", MicroFunc[Import[#URL, "Audio"]],
True, ""] &, PageTheme -> "Red",
AppearanceRules -> <|"Title" -> "Voice Sentiment Classifier"|>],
"VoiceSentiment", Permissions -> "Public"]
The final microsite can be found here at: https://www.wolframcloud.com/objects/ryanheo2001/VoiceSentiment
Lastly, I want to thank my mentor Michael and all the instructors and staff at the wolfram summer camp. They have been very helpful and I have learned valuable lessons from them these past two weeks.


