
Source Code: Github Repositories
Coding simple cases on complicated frameworks often offers important insights on the prototyping abilities of our tools. In this post, I will try to code a simple neural network problem on three different programming languages/libraries, namely Wolfram Language, TensorFlow (Python)1 and Numpy (Python)2.
Let's take a simple hypothetical problem in the life insurance industry as an example. An actuary would study the historical claim patterns of insurance policies and would do valuation work by making predictions of future claims.
In this toy example, lets look at a pool of insured persons of the same age (e.g. age 35) of a medical insurance product. We have four existing insured persons, A, B, C, D, of different gender, smoker status, country class and claim history in their first policy year. We would like to know whether an insured person, E, would make claims in his/her first policy year. Below is a summary table:
The problem
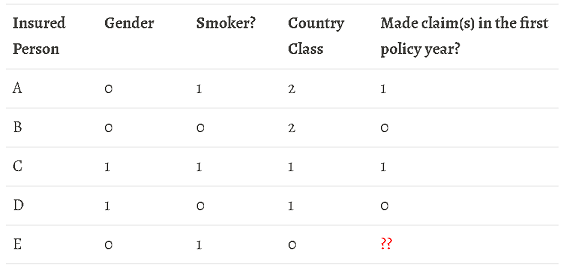
We would construct a simple neural network with a linear layer and a sigmoid layer, and then train the network by using full batch gradient descent method (with mean-square-error $E = \frac{1}{2} \sum_{k} (y_k - t_k)^{2}$ as the loss function and a learning rate of $\lambda = 0.5$). We would go through $10,000$ epochs for the training. After the network is trained, we would make prediction for Insured person E based on the trained network.
Image 1: A simple neural network of two layers: a linear layer and a sigmoid layer.
We would focus on the coding style/ prototyping abilities of the programming languages/ libraries, instead of the theoretical background. For the explanation of the theoretical background for the forward/backward propagation of linear layer and sigmoid layer, please refer to this article3.
Let's see how the codes of the three programming languages/libraries look like:
Summary
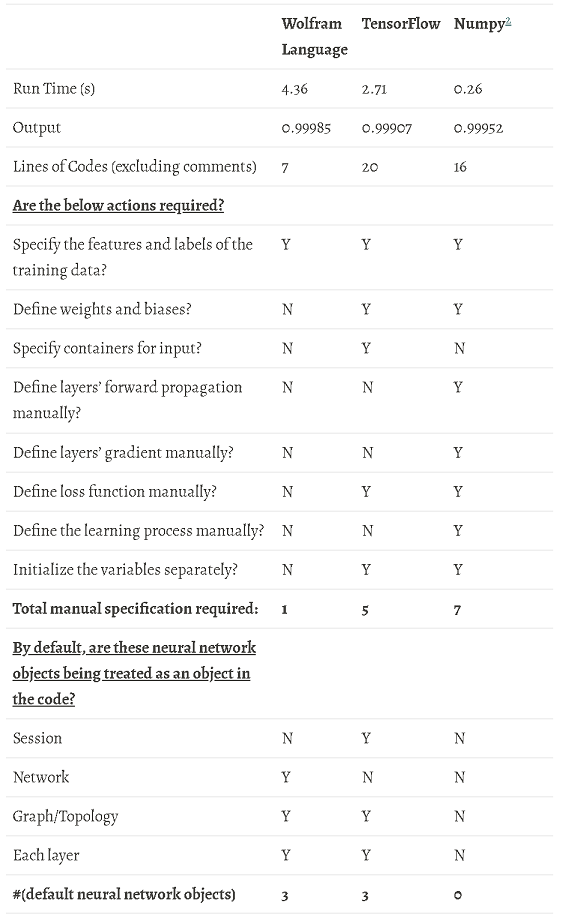
As we can see, Numpy has the shortest run-time. It is still within expectation as Numpy is a lower-level to-the-metal language/library, while TensorFlow and Wolfram Language are) much more to-the-human. Although run-time differences seem huge, we should not forget that this toy example is simple (i.e. with one linear layer and one sigmoid layer only), which means many high-level objects of TensorFlow and Wolfram Language designed for neural network have not been fully utilized.
Numpy is also using fewer lines of codes than TensorFlow. But again, we need to note the simplicity of layering in this case, which involves basic forward/backward propagations, allowing Numpy to be less wordy than TensorFlow. If the structure of the neural network becomes more complicated, the difficulty and complicity of coding in Numpy would increase much more significantly than TensorFlow.
It is worth to point out that Wolfram Language uses only seven lines, which indicates that it has robust prototyping abilities in neural network. In fact, Wolfram Language is designed to perform abstract computation, such that many concepts in the neural network can be categorized as a single object, which is also reflected in the above comparison table. In this particular example, in fact, we can even further reduce the lines of code to four4, each refers to the concept of 1. importing training data, 2. constructing network, 3. training network and 4. making predictions.
Below are the codes being used:-
Wolfram Language
trainingSetInput = {{0, 1, 2}, {0, 0, 2}, {1, 1, 1}, {1, 0, 1}};
trainingSetOutput = {1, 0, 1, 0};
n = Length@trainingSetInput;
asso = Thread[trainingSetInput -> trainingSetOutput];
net = NetChain[{LinearLayer[], ElementwiseLayer["Sigmoid"]}];
trained = NetTrain[net, asso, MaxTrainingRounds -> 10000, LossFunction -> MeanSquaredLossLayer[], Method -> {"SGD", "LearningRate" -> 0.5}, BatchSize -> n];
trained[{0, 1, 0}]
TensorFlow (Python)
import tensorflow as tf
import numpy as np
# training data
training_set_inputs =np.array([[0,1,2],[0,0,2],[1,1,1],[1,0,1]])
training_set_outputs =np.array([[1],[0],[1],[0]])
# containers and operations
x = tf.placeholder(tf.float32, [None, 3])
W = tf.Variable(tf.zeros([3, 1]))
B = tf.Variable(tf.zeros([1]))
yHat = tf.nn.sigmoid(tf.matmul(x, W) + B)
yLb = tf.placeholder(tf.float32, [None, 1])
learning_rate = 0.5
mean_square_loss = tf.reduce_mean(tf.square(yLb - yHat))
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(mean_square_loss)
# use session to execute graphs
sess = tf.Session()
init=tf.global_variables_initializer()
sess.run(init)
# start training
for i in range(10000):
sess.run(train_step, feed_dict={x: training_set_inputs, yLb: training_set_outputs})
# do prediction
x0=np.float32(np.array([[0.,1.,0.]]))
y0=tf.nn.sigmoid(tf.matmul(x0,W) + B)
print('%.15f' % sess.run(y0))
Numpy (Python)
import numpy as np
from numpy import exp, array, random, dot
training_set_inputs = array([[0, 1, 2], [0, 0, 2], [1, 1, 1], [1, 0, 1]])
training_set_outputs = array([[1, 0, 1, 0]]).T
random.seed(1)
#Initialization
W = random.random((3, 1))
B = random.random((1, 1))
for iteration in range(10000):
# Sigmoid function
yHat = 1 / (1 + exp(-(dot(training_set_inputs, W)+B)))
# gradient of mean square loss: grad0 = (yHat-training_set_outputs)
# gradient of Sigmoid: grad = grad0 * yHat * (1 - yHat);
# full batch gradient descent
grad=(yHat-training_set_outputs) * yHat * (1 - yHat)
# gradient of linear layer
d_W=dot(training_set_inputs.T, grad)
# just sum up grad to form d_B
d_B=np.sum(grad,axis=0)
LearnRate=0.5
# gradient descent method
W -= LearnRate*d_W
B -= LearnRate*d_B
print(1 / (1 + exp(-(dot(array([0, 1, 0]), W)+B))))
Footnotes
- TensorFlow means coding in Python using TensorFlow library as the main tool for constructing neural network (but without Keras), while using Numpy for certain basic calculations.
- Numpy means coding in Python using the Numpy library to construct neural network without involving TensorFlow.
- There are some discrepancies between the network used in the reference article and that in this post. For example, the affine layer in the referenced neural network does not have a bias term for the sake of simplicity, while we do. The referenced neural network codes the learning process in the format of adding the minus gradient instead of lessing the gradient. But the basic ideas are the same, and in fact, this article is inspired by that article.
- By putting all numerical data in
asso without defining trainingSetInput and trainingSetOutput, and putting n in NetTrain.


