((RELEASE 3, Complete Charts and Data Analysis))
In this new Release 3 I compiled 26 more numbers with the workbook 2.0 (3.0 is coming
):
-a few more notable numbers.
-more numbers generated from the series of interactions between Pi and E.
-some exotic numbers from C(10) and C(10)!
EXPLAINING: C, S, T, A
(C): Deviation of the arithmetic mean.
Given the raw sum of all the digits divided by the total amount of digits: M
If M>4.5, C = M/4.5-1
If M<4.5, C = 4.5/M-1
If M=4.5, C = 0
(S): Deviation of the digit Count.
Given the average number of digits optimal for each digit being equal to the Total digits divided by 10, because there are 10 digits different from 0 to 9.
N = Total of digits/10
So the number of digits lagged for each is given by Dk:
Dk=abs(N-k)/N , k= Total digits for each type: 0.1, 2... etc.
Then I do the arithmetic mean: D0+D1+D2+D3...+D9 = DM, and divide by 10 to do the mean and decrease the scale:
S = DM/10
(T): tendency in a coin toss.
If the digit is 0, 1, 2, 3, 4 is given the value "1". The sum of all "1" = X1
If the digit is 5, 6, 7, 8, 9 is given the value "2". The sum of all "2" = X2
The ratio is made between X1 and X2:
If X1>X2, T = X1/X2-1
If X2>X1, T = X2/X1-1
If X1=X2, T = 0
(A): Reason of repeated numbers appear.
Take the sum of all the numbers that repeat or are part of repeated numbers as in the example: 00,111,222222,55555555, etc. Then it divides by the total digits in the Interval. It's a simple reason.
All the numbers analyzed have 10000 digits and each graph a resolution of 200 points with a pass of 50 digits. Here are the charts:
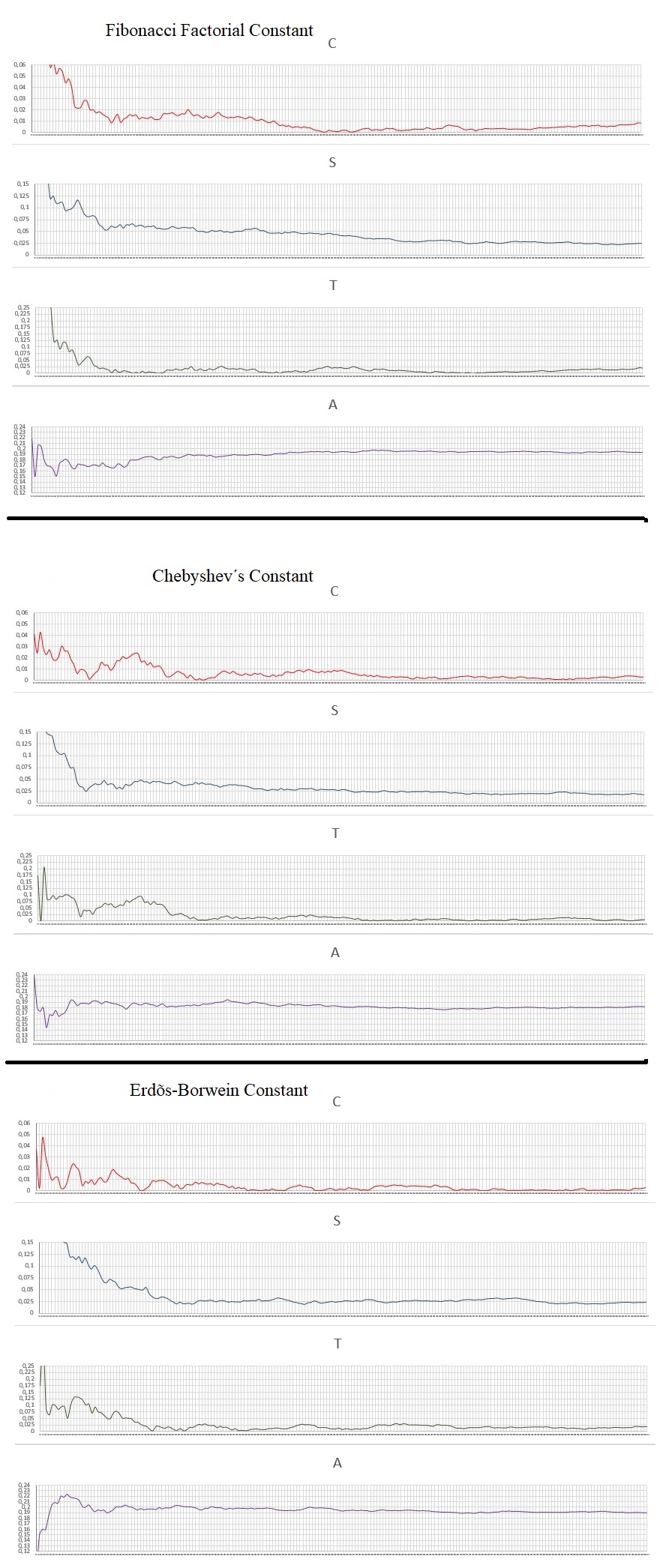
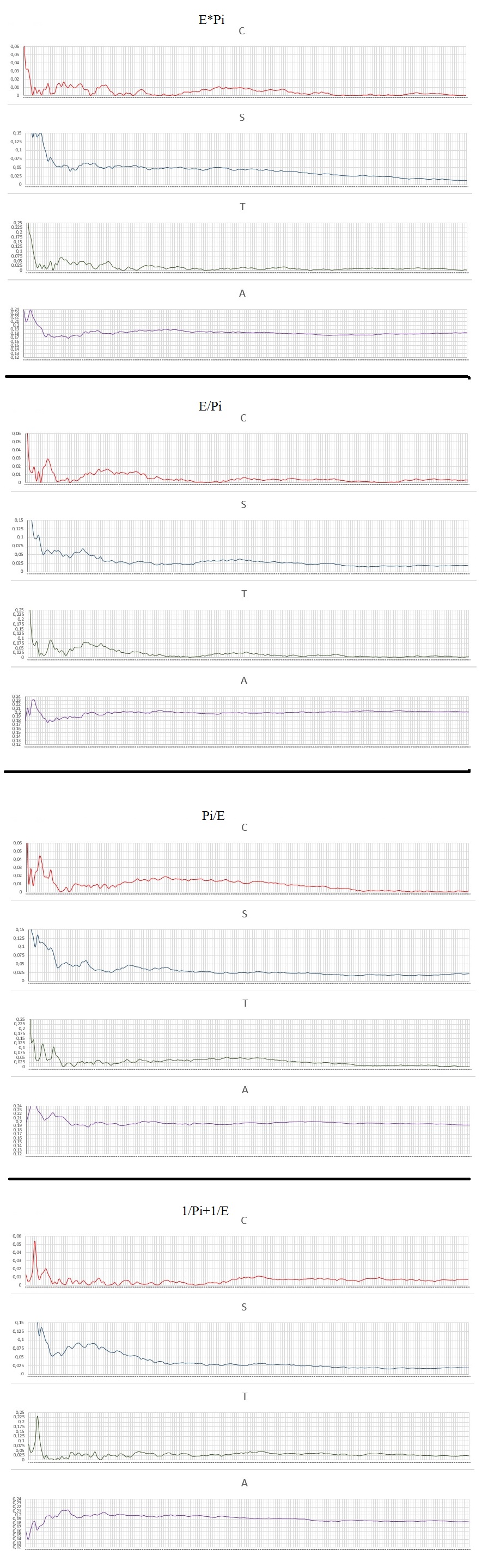
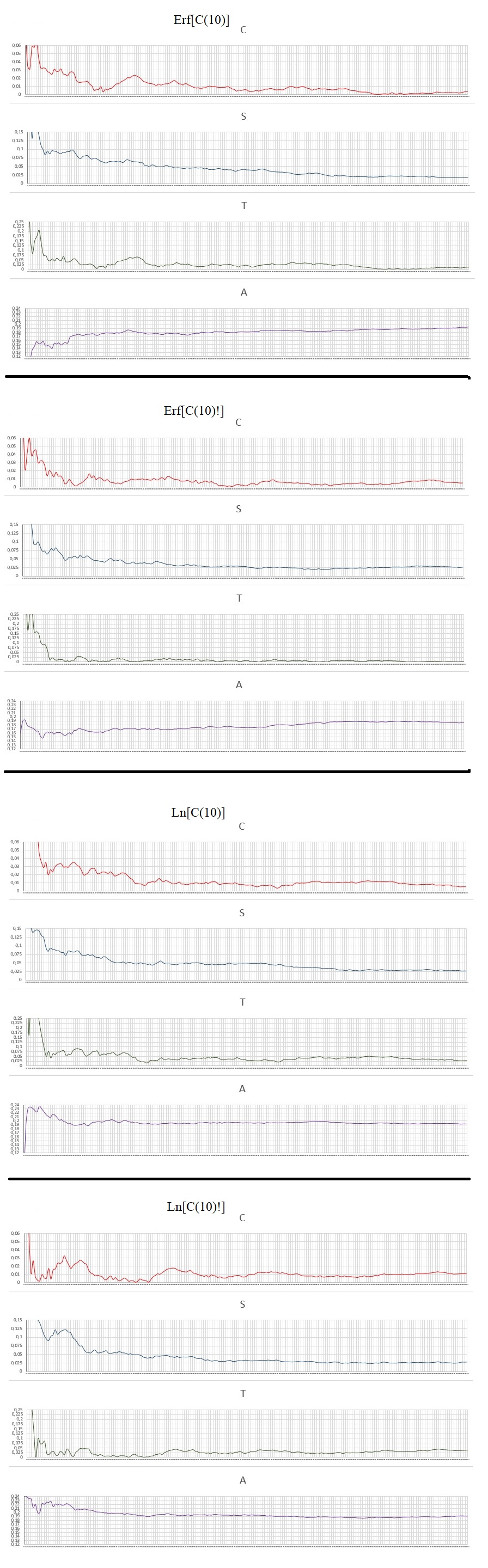
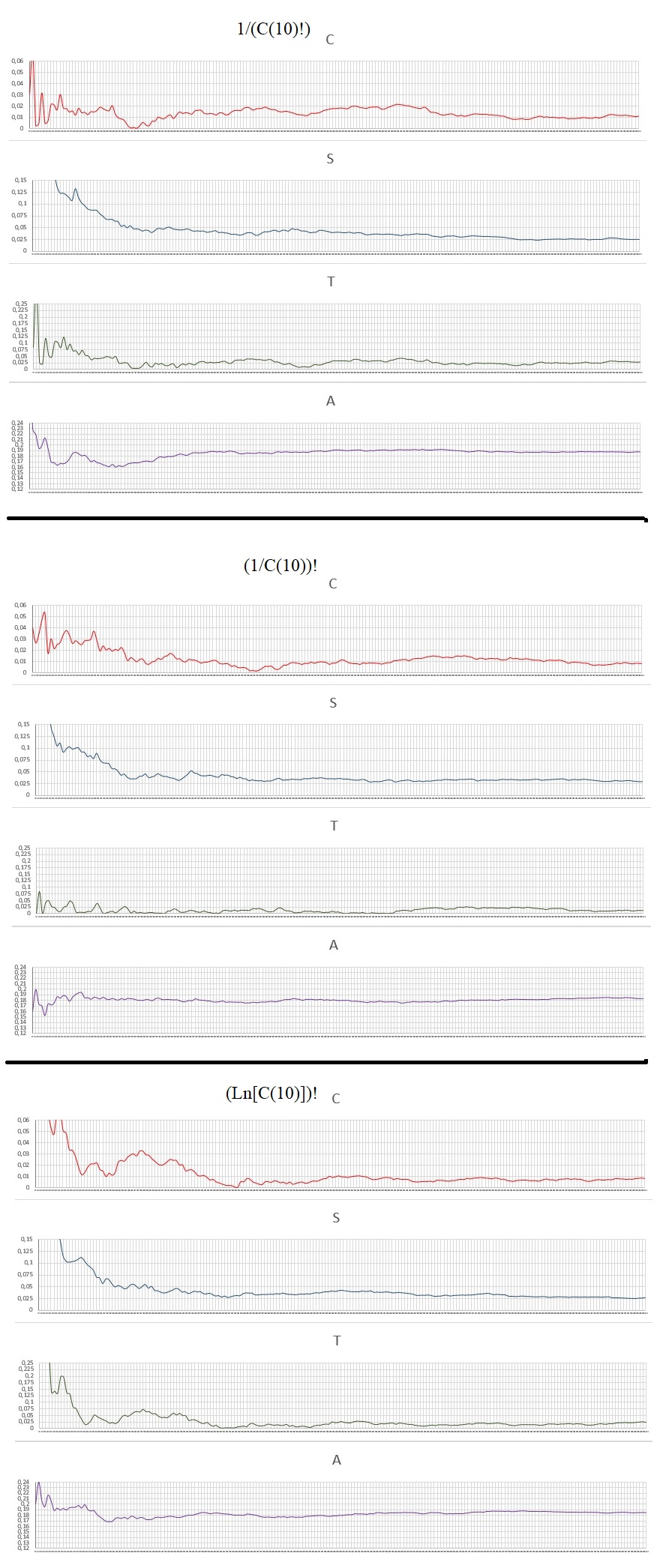
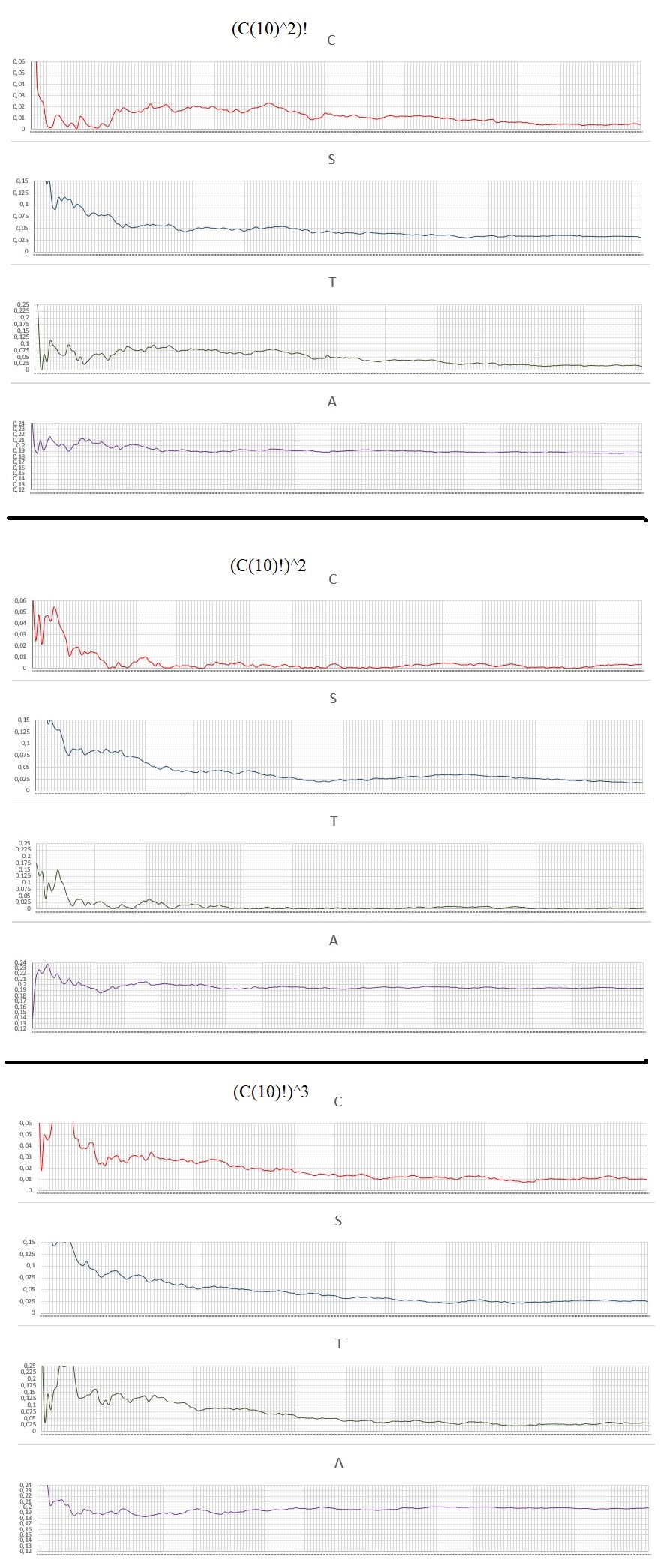
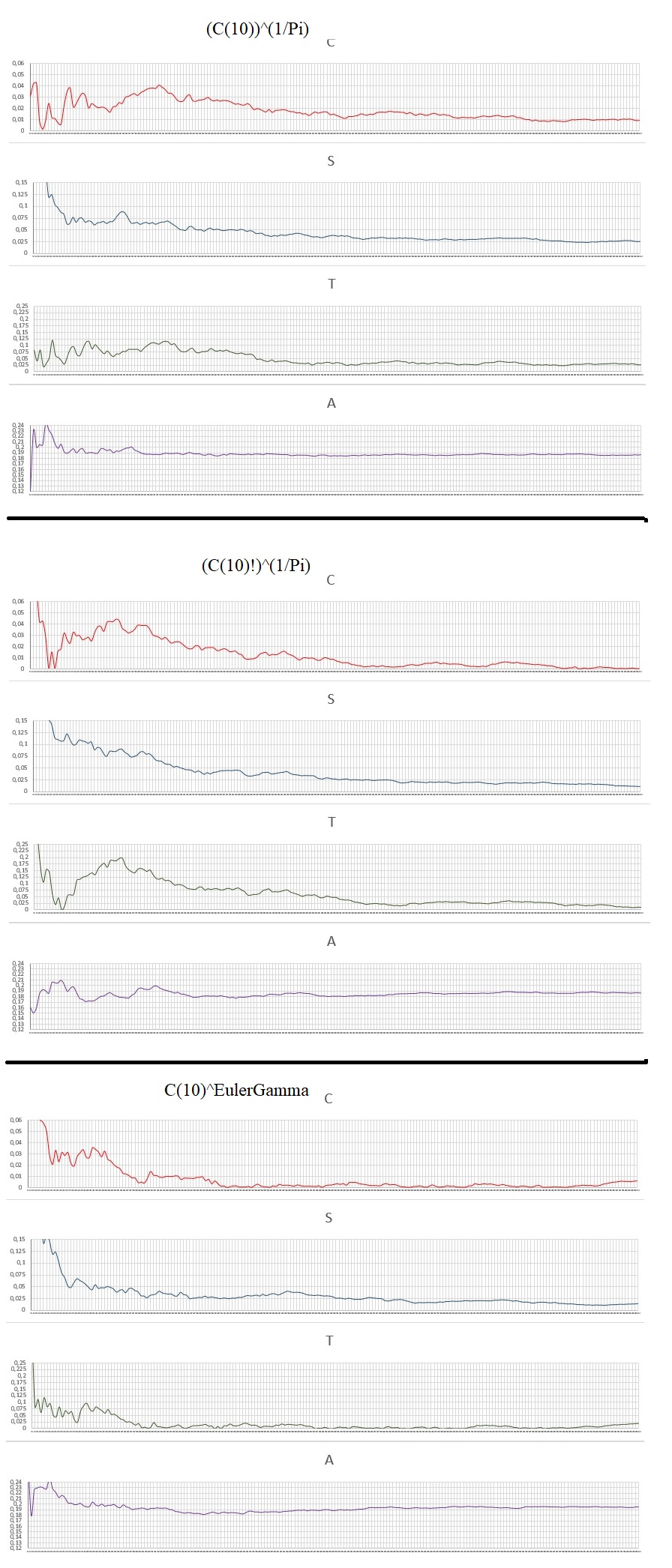
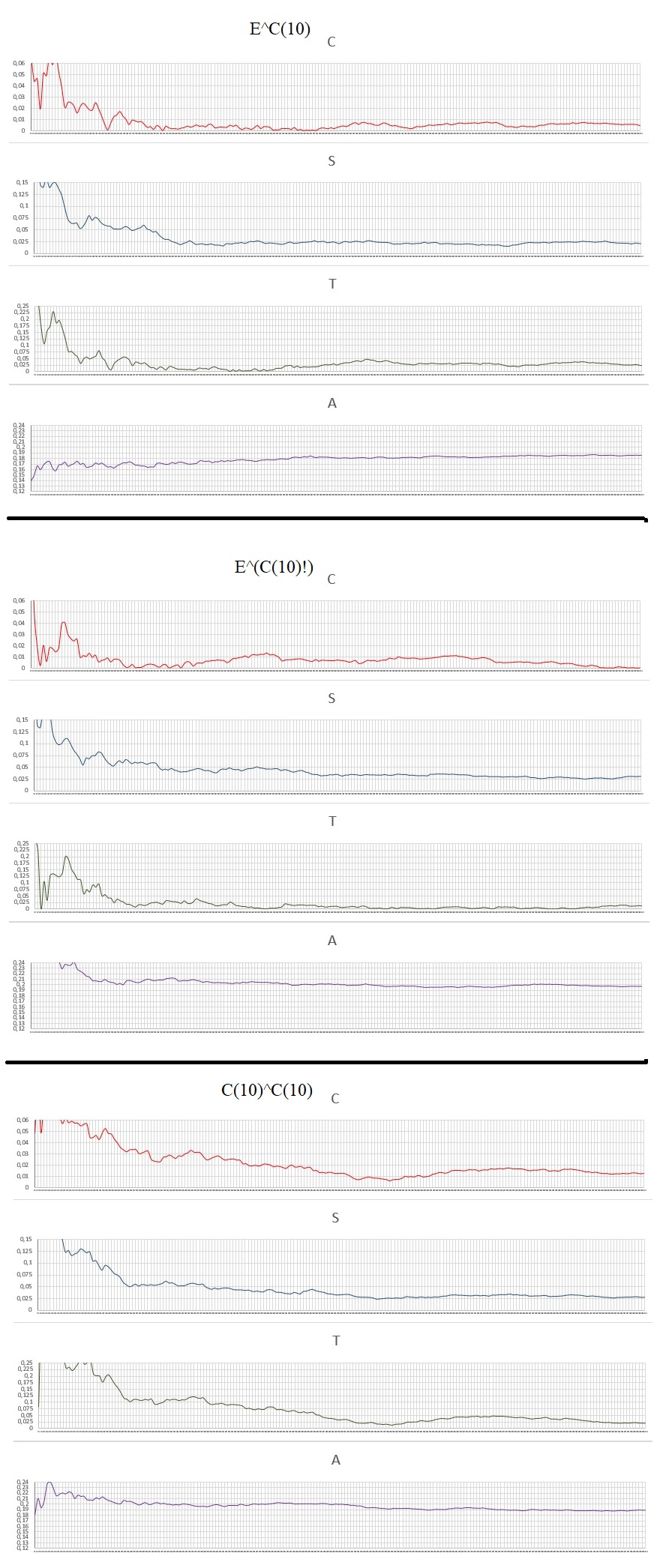
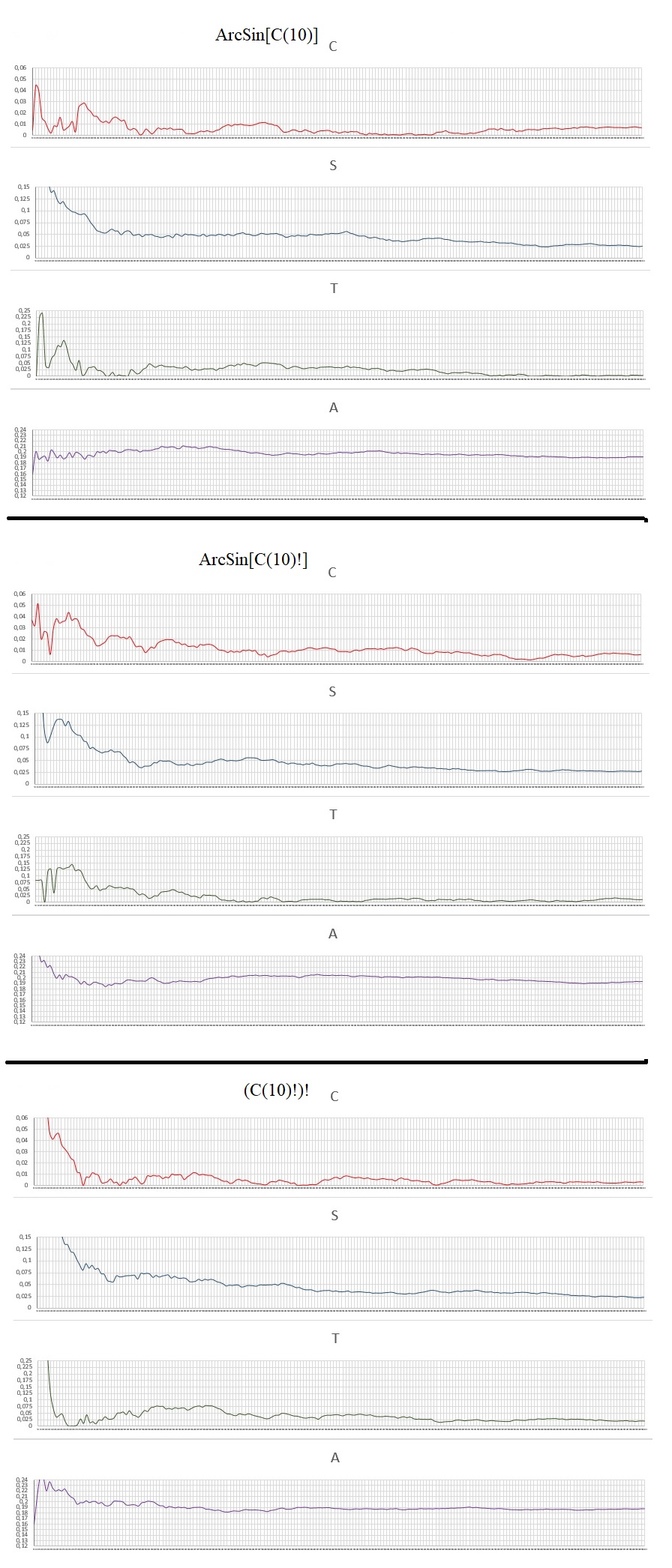
Data Analysis:
Random test of remarkable and exotic numbers.
Number of Numbers: 68
Values: calculated area of the chart, the lower the value, the better for random use.
The result with the values and rankings in each category analyzed:
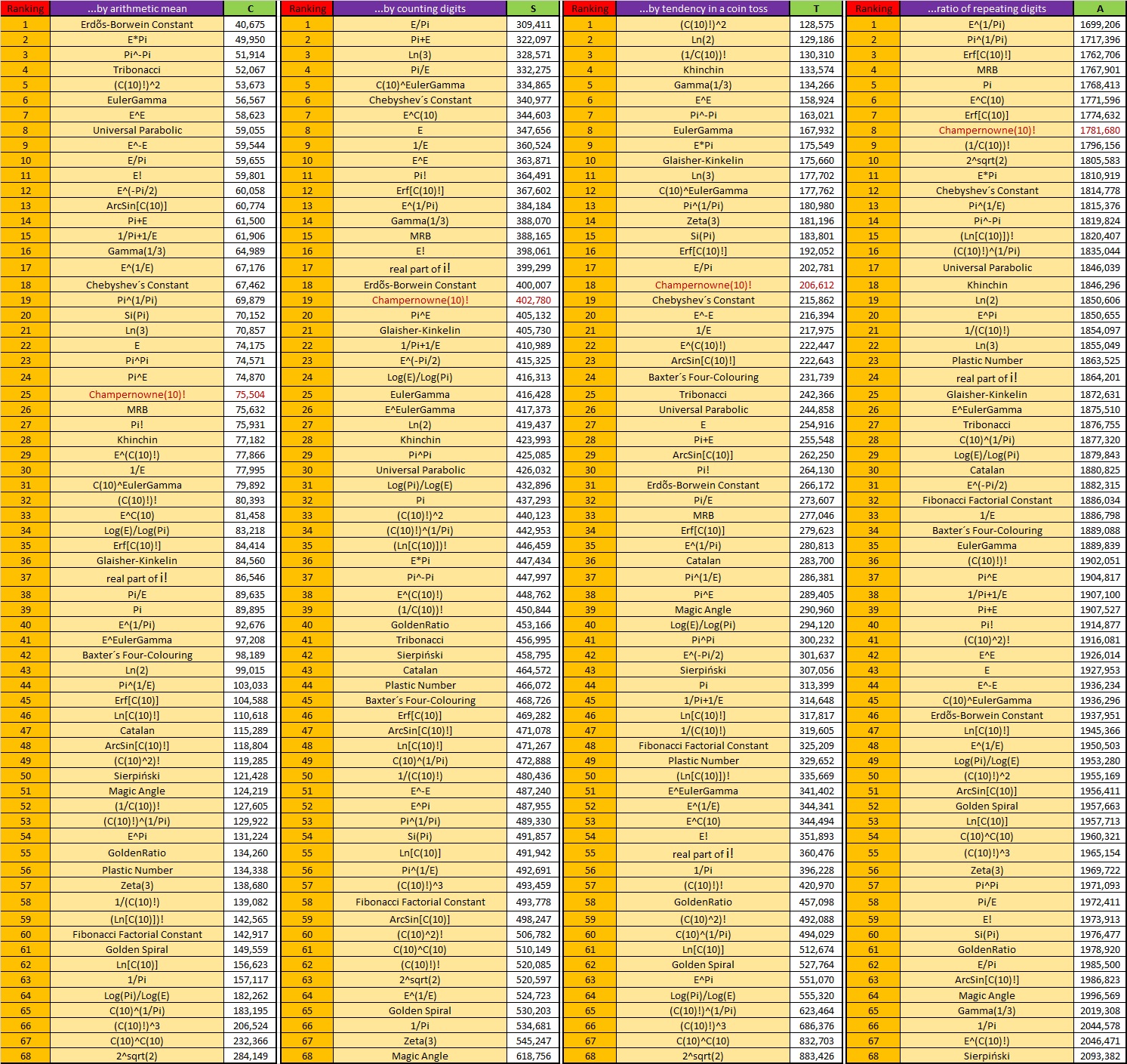
The complete table with the rankings and values of all the numbers analyzed so far (alphabetical order):
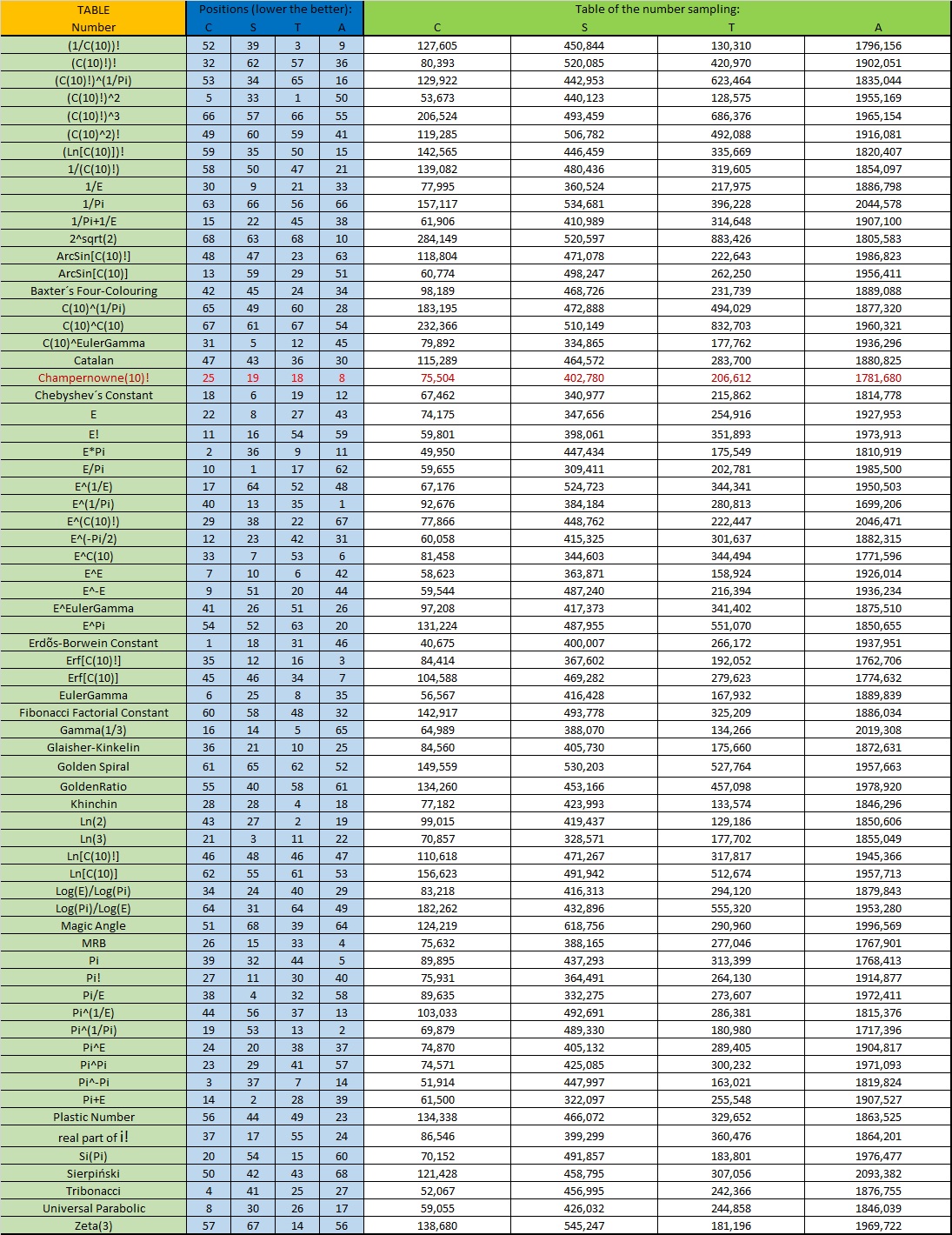
Doing an analysis of the numbers with the characteristic A with values close to Pi:
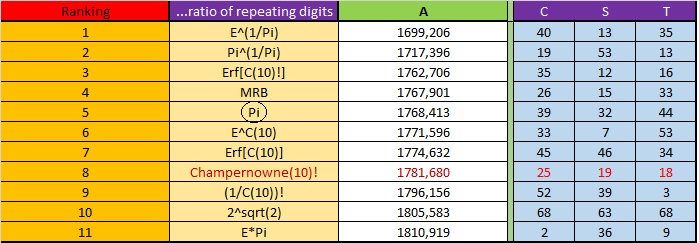
Note that of these numbers above, the most balanced-efficient is still the C (10)! At least for now it is still the best for generic random uses.
In these tests I completed almost completely the simple interactions of Pi and E so that it is possible to analyze how the random behavior changes with each Operation. I was also able to explore exotic numbers in the search for the perfect candidate for use with Randomness.
If anyone has a number or type of number for which I test and sort let me know by posting here. There´s a lot of data here for anyone to use.
Anyone here in the Community knows how I find or generate the Thue-Morse Constant (decimal form) with 10000 digits please??? I know that more than 3 million digits have already been calculated but I can´t find anywhere.....


