It looks like you are satisfied with the answers so far. I continued to work on the problem though to come up with the best possible (non-machine-learning) solution. The first line takes a list of words or just run as is.
wds = RandomWord[10];
ipaVs = ipaVowels = {"a?", "a?", "e?", "??", "o?", "?", "?", "?", "?", "?", "?", "?", "?", "?", "?", "?", "?", "?","?", "?", "?", "?", "?", "?", "?", "a", "æ", "e", "i", "o", "", "ø", "u", "y"};
dip = {"ai", "au", "ay", "ea", "ee", "ei", "eu", "ey", "ie", "io", "oa", "oe", "oi", "oo", "ou", "oy", "ua", "ue", "ui", "uy"};
vow = {"a", "e", "i", "o", "u", "y"};
hyp[wd_] := (h = WordData[wd, "Hyphenation"] /. Missing[_] -> {}; {h, Length[h]});
ipa[wd_] := (p = WordData[wd, "PhoneticForm"] /. Missing[_] -> "X"; {p, StringCount[p, ipaVs]});
reg[wd_] := {wd,
Total@StringCases[wd,
{"e" ~~ EndOfString -> Nothing, "-" -> Nothing, "qu" -> 0, "eness" -> 1, "ement" -> 1,
{"p", "b", "c", "d", "f", "g", "k", "s", "t", "z"} ~~ "le" ~~EndOfString -> 1,
{"d", "t"} ~~ "ed" ~~ EndOfString -> 1, "ed" ~~ EndOfString -> 0, dip -> 1,
vow -> 1, Except[vow] .. -> 0}]};
calcScr[cts_] := (
If[cts[[1]] == cts[[2]] > 0, Return[{cts[[1]], "very high"}]];
If[cts[[1]] == 1 && cts[[2]] == 2, Return[{2, "high"}]];
If[cts[[1]] == 0 && cts[[2]] == cts[[3]], Return[{cts[[2]], "very high"}]];
If[cts[[1]] > 0 && cts[[2]] != cts[[1]], Return[{cts[[1]], "high"}]];
If[cts[[1]] == 0 && cts[[2]] == 0, Return[{cts[[3]], "medium"}]];
Return[{cts[[2]], "high"}]);
cts = {#, hyp[#][[2]], ipa[#][[2]], reg[#][[2]]} & /@ ToLowerCase[wds];
scr = ({#[[1]], calcScr[#[[2 ;; 4]]]} &) /@ cts;
dts = Dataset[
Association[#[[1]] -> <|"syllables" -> #[[2, 1]], "confidence" -> #[[2, 2]]|> & /@ scr]]
Output is in the form of a dataset, but you can change that to your needs:
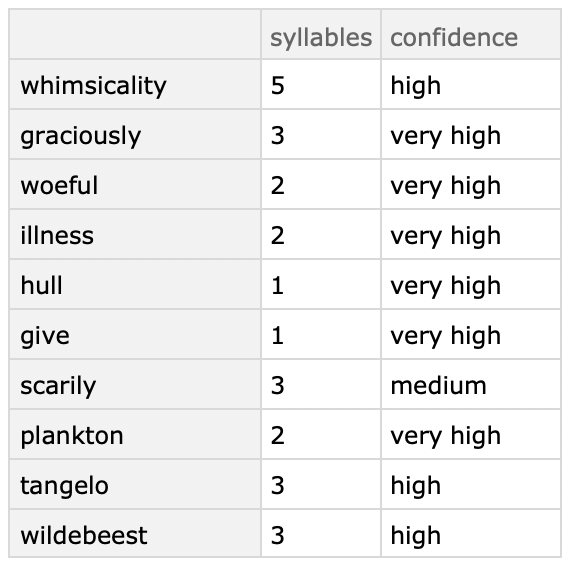
I have tested this on about 500 random words and only found 3 wrongly assessed words: nationalism, socialism, and nth. Though I think it is probably overkill for your question, it was a fun side project. Thanks. : )


