Abstract
The objective of this project was to create a program that can determine whether an unknown text is a work of fiction or non-fiction using machine learning. I utilized various datasets of speeches, ebooks, poems, scientific papers, and more texts from Project Gutenberg and the Wolfram Example Data to train and test a Markov Chain machine learning model. I deployed a microsite with my final product that returns a probability of fictionality based on input from the user with 95% accuracy.
Introduction
The majority of literature and texts can be classified into fiction and non-fiction. Fiction is defined as the class of literature comprising works of imaginative narration, especially in prose form, while non-fiction is defined as all content discussing real events and facts. Although most of the time the class of a work is fairly obvious due to fantastical elements and writing style, there are many cases where the class is unclear because of the various types of fiction and non-fiction and the complexities of the boundaries between them. The goal of this project was to create a classifier that can accurately understand those boundaries in order to classify an unknown work.
Obtaining and Processing Data
I imported 300 full .txt files of various speeches, ebooks, poems, essays, scientific papers, and more texts from the public dataset for Project Gutenberg. However, this data was not tagged and sorted into Fiction and Non-Fiction so I had to manually assign classes to each of the files based on research on the works. I made a dataset containing the name, class, and full text of each file.
datasetGutFull =
Dataset[Table[<|"FileName" -> filenames[[n]],
"Nonfiction" -> classGut[[n]],
"FullText" -> DataGutAll[[n]]|>, {n, 1, Length[filenames}]];
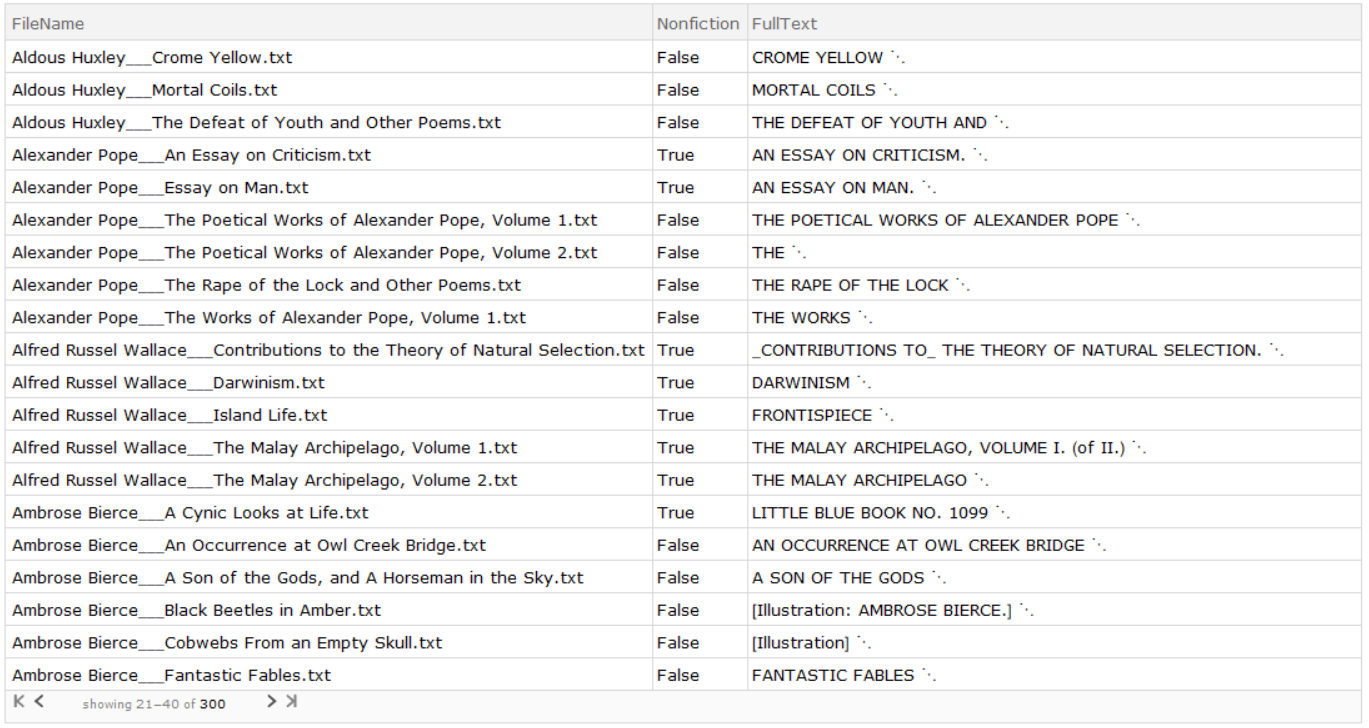 I also added various texts from the Example Data function to my data. In order to do this, I manually classified the texts and filtered out all the Example Data texts that were religious or not in English.
I also added various texts from the Example Data function to my data. In order to do this, I manually classified the texts and filtered out all the Example Data texts that were religious or not in English.
Partitioning
In order to increase the efficiency of processing and prepare for training, I made a function to partition each text into sections of 5000 characters each and associate the sections with their corresponding class.
partition[text_, class_] :=
With[{a = StringPartition[text, 5000]},
Thread[a -> Table[class, {Length[a]}]]
];
datasetGutPart =
Flatten[Table[
partition[datasetGutFull[n, "FullText"],
datasetGutFull[n, "Nonfiction"]], {n, 1, Length[datasetGutFull]}]]
dataExamplePart =
Flatten[Table[
partition[textsEx[[n]], classEx[[n]]], {n, 1, Length[textsEx]}]];
datasetGutAndEx = Join[datasetGutPart, dataExamplePart];
textsEx = Table[ExampleData[{"Text", filenamesExEng[[n]]}], {n, 1, Length[filenamesExEng]}];
Training the Machine Learning Model
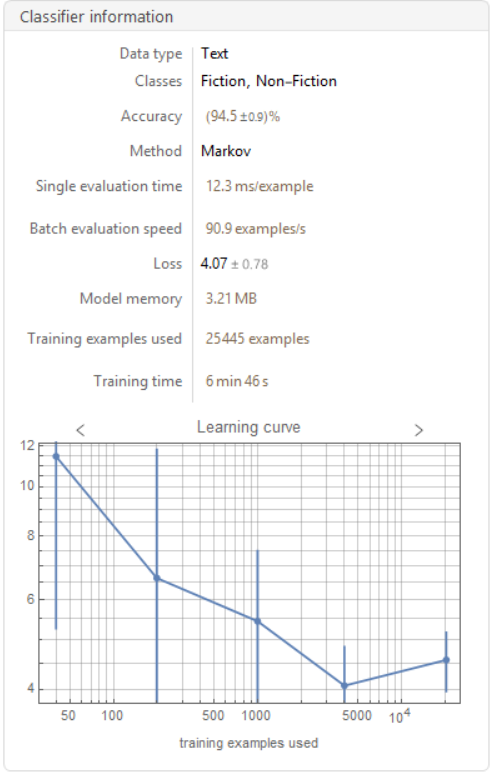
After much experimentation with various types of machine learning such as Neural Networks, Random Forest Models, and Linear Regression Models, I found that the Markov Method of machine learning yielded the highest accuracy of approximately 95%.
classifyMarkov300Gut =
Classify[Table[
datasetGutAndEx[[n]], {n, 1, Length[datasetGutAndEx]}],
Method -> "Markov"]
Deploying the Model
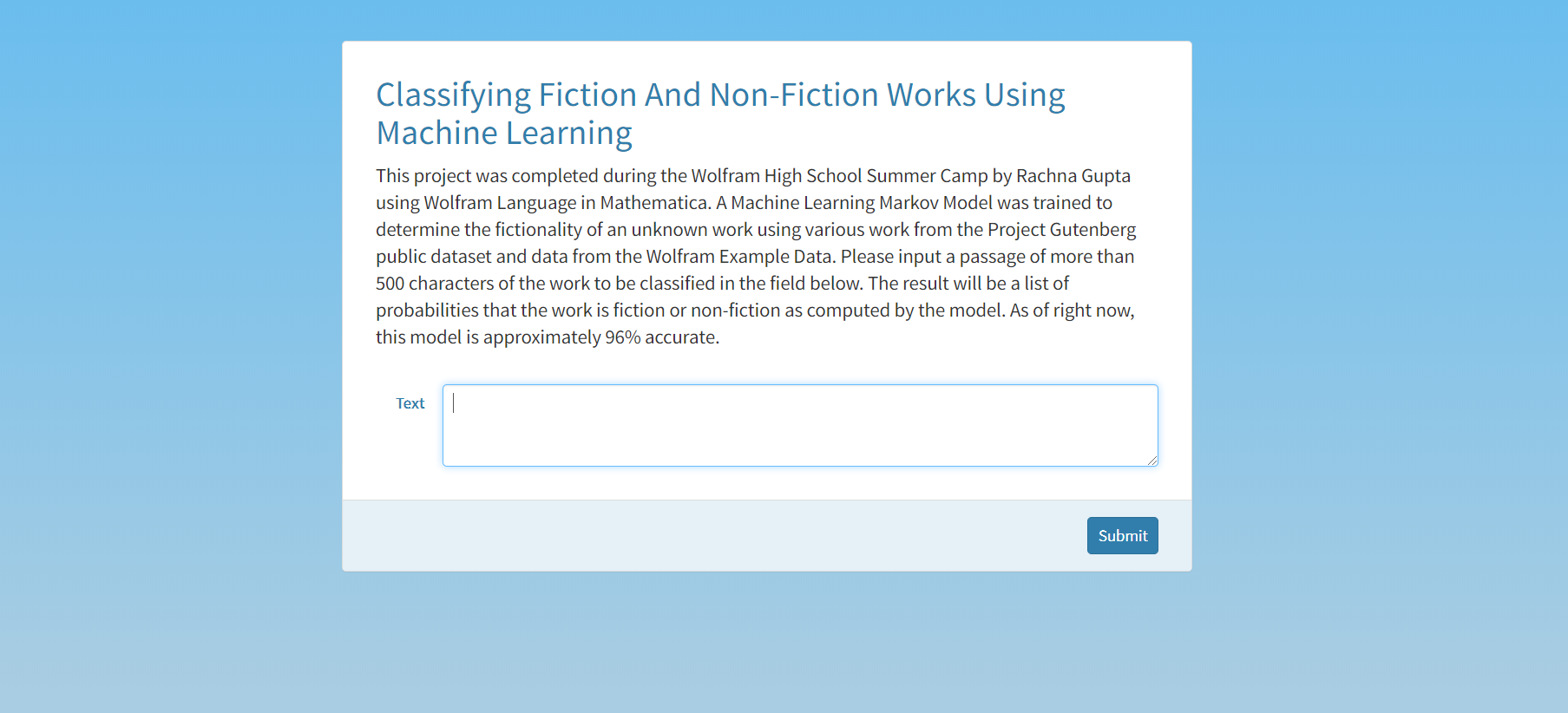
I made a function called finalClass that averaged the probabilities for Fiction and Non-Fiction for each section of a given text and returns a final probability and class. Then, I used CloudDeploy to create a microsite that takes a text from the user and returns the probability that it is Fiction. This site can be accessed at https://www.wolframcloud.com/obj/rachgupta200/FictionvsNonFiction.
finalClass[text_String] :=
Mean[classifyMarkov300Gut[StringPartition[text, 500],
"Probabilities"]]*100
CloudDeploy[
FormFunction[{"Text" -> "TextArea"}, finalClass[#Text] &,
AppearanceRules -> <|
"Title" ->
"Classifying Fiction And Non-Fiction Works Using Machine \
Learning",
"Description" ->
"This project was completed during the Wolfram High School \
Summer Camp by Rachna Gupta using Wolfram Language in Mathematica. A \
Machine Learning Markov Model was trained to determine the \
fictionality of an unknown work using various work from the Project \
Gutenberg public dataset and data from the Wolfram Example Data. \
Please input a passage of more than 500 characters of the work to be \
classified in the field below. The result will be a list of \
probabilities that the work is fiction or non-fiction as computed by \
the model. As of right now, this model is approximately 95% \
accurate."|>, PageTheme -> "Blue"], "FictionvsNonFiction",
Permissions -> "Public"]
Conclusion and Future Work
Through this project, I successfully created a model that can accurately classify fiction and non-fiction texts. The classifier takes an input of any English text greater than 500 characters and gives an output of the probability that the given work is fiction or non-fiction. The working project can be found at this link https://www.wolframcloud.com/obj/rachgupta200/FictionvsNonFiction. In the future, I would like to explore the possibility of using more data from the Wolfram Data Repository to train the model and increase the accuracy. I would also like to explore making the classifier more specific, such as identifying the genre of the work and mapping the "fictionality" of the work on a scale. For example, historical fiction would be closer to non-fiction on the scale than fantasy or magical realism.
Acknowledgements
I would like to thank my wonderful mentor, Sylvia Haas, as well as all the other mentors from the Wolfram Summer Camp, for guiding me and helping me with this project.
Github Link: https://github.com/rachgupta/WSS-Template


