I run into some trouble with the format of DataSet.
The following runs without errors and trains fairly:
addressData = ResourceData["State of the Union Addresses"];
addressEssensialData = addressData[All, {"Date", "Text", "Age"}];
{training, testing} = TakeDrop[addressEssensialData, 200];
Note that at this point:
In[16]:= training // Head
Out[16]= Dataset
Next, I can successfully use variable training in the following way
p = Predict[training -> "Age"]
Further, I am OK with getting predictions and actual data "by hand":
predictionsOnTesting = p[testing]
actualsOnTesting = testing[[All, 3]] // Normal
And further I can plot their comparison plot (also "by hand")
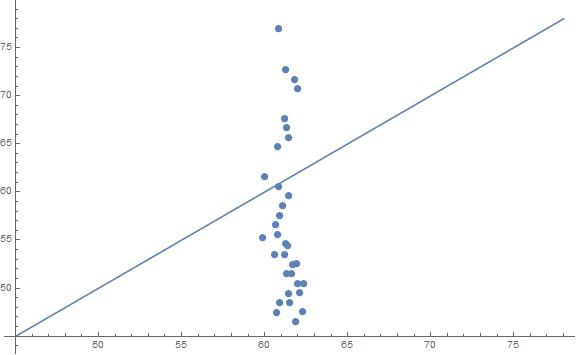
However, if I try feeding testing into PredictorMeasurements[..]
pm = PredictorMeasurements[p, testing]
or similarly as it worked earlier with Predict[..]
pm = PredictorMeasurements[p, testing->"Age"]
It runs with the following error
PredictorMeasurements::bdfmt: Argument Dataset [<<33>>] should be a rule or a list of rules.
And usually crashes Mathematica if I try doing anything further. Though one time I somehow managed:
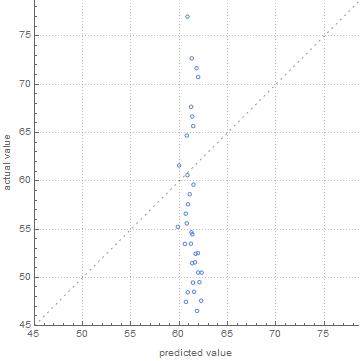
I am a bit at a loss how to properly figure out PredictorMeasurements[...] with DataSet variable for the training set... (I also tried turning DataSets into Lists but this seems wrong and I didn't have much success with it either)
 Attachments:
Attachments:


