This is a follow-up of
the thread about obtaining the XML data file from the W|A server. This discussion shows the detailed implementation of the
API documentation with Python.
Use
the following code (just need this part from the code through the link) to load the sample XML (a developer ID/appid is required to obtain the xml file. The XML file is not provided within this thread). You can run this code line by line from the python interactive interface (I use python 2.7)
>>> import urllib
>>> import urllib2
>>> base_url = 'http://api.wolframalpha.com/v2/query?'
>>> headers = {'User - Agent' : None}
>>> data = 'input=GOOG&appid=Q7****'
>>> req = urllib2.Request (base_url, data, headers)
>>> xml = urllib2.urlopen (req).read ()
The result should be similar to the below. You can simply highlight and copy the print from <?xml ... > to </queryresult> (end of the xml data) in terminal and paste it into your own file "~/test.xml" (create it by "$ nano ~/test.xml").
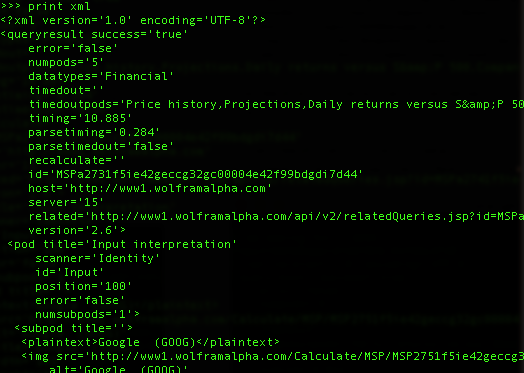
To analyze the infomation in this xml file in any other Python session, you will need to import it from the "test.xml" (if you want to use it directly within the session you can use the
ElementTree.fromstring method). Use the
parse() method to create a tree-like data struction in python, which you can manipuate later.
>>> import xml.etree.ElementTree as ET
>>> tree = ET.parse ('test.xml')
>>> print tree
< xml.etree.ElementTree.ElementTree object at 0 x...... >
To check what is in the root object, you can use the tag method to get the first level children of the root: ("ele" means element)
>>> root = tree.getroot()
>>> print root
<Element 'queryresult' at 0x......>
>>> for ele in root : print ele.tag, ele.attrib
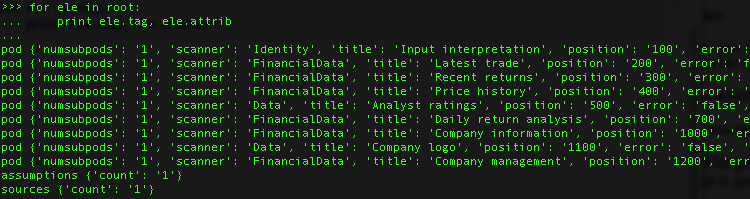
Each list represents the attribution list of this pair: <pod attrib > </pod> . For instance:
< ?xml version='1.0' encoding='UTF-8'?>
...
< pod title = ' Latest trade'
scanner = ' FinancialData'
id = ' Quote'
position = ' 200'
error = ' false'
numsubpods = ' 1'
primary = ' true' >
...
Use the
dictionary key to find the title of a particular node/pod:
>>> root[1].attrib['title']
' Latest trade'
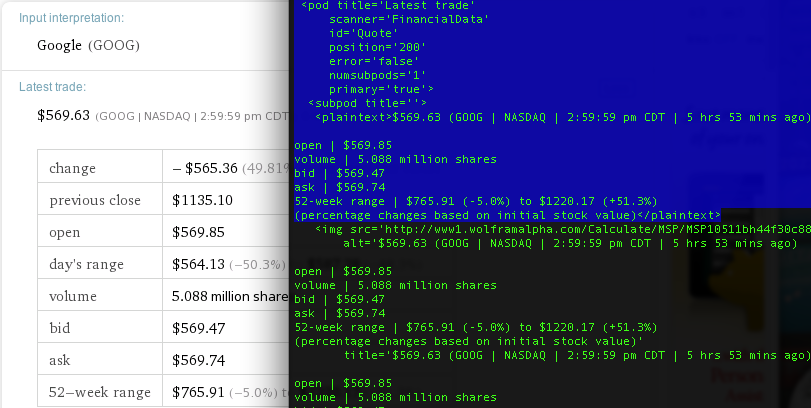
The ouput result of this pod is hidden in the <plaintext> wrapper, which is under a <subpod> wrapper. Therefore we <plaintext> is just the grandson of the <pod>, root[1]
< subpod title = '' >
< plaintext > $1127 .74 (GOOG | NASDAQ | 1 min ago) < /plaintext >
...
I suggest the subrouting to extract the information of a child node in case of duplication:
>>> latestTrade = [ele for ele in root.findall ('pod') if ele.attrib['title'] == 'Latest trade']
>>> len(latestTrade) # rarely, more than one pods have the same title
1
then use the "latestTrade" as root for the subTree. Go down two levels to reach <plaintext>
>>> latestTrade = [ele for ele in latestTrade[0].findall ('subpod')]
>>> latestTrade = [ele for ele in latestTrade[0].findall ('plaintext')]
>>> latestTrade[0].text
' $1127 .74 (GOOG | NASDAQ | 1 min ago)'
Notice that I append [0] to "latestTrade" token because each "[ele ... ]" returns a
list object in python and index variable is to dereference the first item.
Python offers a better flow control to the demonstrative code via
nested iterable object. Here is a simple implementation:
>>> result = [[[(pod.get ('title'), node.text) for node in subp.iter ('plaintext')] \
for subp in pod.iter('subpod') ] for pod in root.iter ('pod')]
Each element in the "res" is a 2D array of 'title' and 'value' pair. I prefer to use the dictionary object to save result if no duplicated pod title. Otherwise make a list as the value to the given key.
>>> result[0]
[[('Input interpretation', 'Google (GOOG)')]]
>>> result = dict([result[ele][0][0] for ele in range(len(result))])
It is very simple to get the value of any given title/key:
>>> result['Latest trade']
'$1127.74 (GOOG | NASDAQ | 1 min ago)'
>>> print res['Recent returns']
day | month | YTD | year | 5 year
-0.91% | +0.2% | +6.1% | +43.67% |
The Wolfram Alpha engine provides not only a rich pool of data but also
an elegant set of controls to customize the ouput. For instance, the hightlight parts below including
"Assumption" and More/Less toggle. You are able to switch to a different representation or knowledge domain via the API as well.
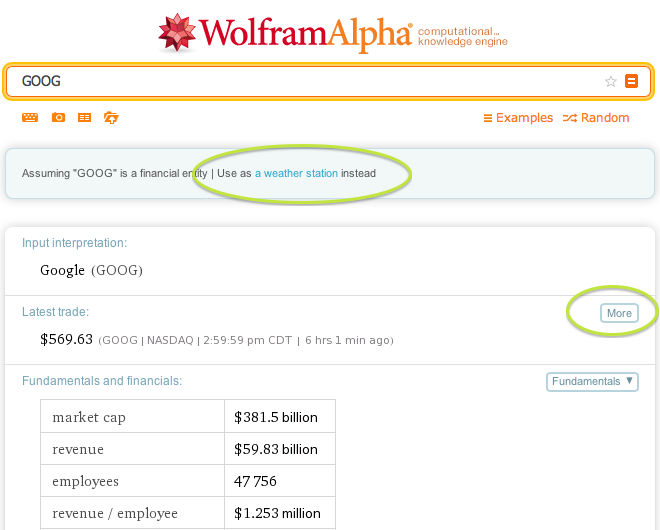
Take the More/Less toggle as an example.
First, you will need to find the pod state of this entry from the XML file. This piece of information usually hides in the <state> wrapper, a child node of <pod> and a sister node of <subpod>. Use a similar subroutine to that for <plaintext>, you can extract all but every states, not limited to our example:
>>> resStates = [[[(pod.get('title'),node.attrib['input']) for node in st.iter('state')] for st in pod.iter('states') ] for pod in root.iter('pod')]
>>> myStates = [ele[0] for ele in resStates if ele!=[]] # remove the empty list
>>> for ele in myStates:
... for pairs in ele:
... print pairs[0],'\t', pairs[1]
...
Latest trade Quote__More
Price history PriceHistory__Last year
Price history PriceHistory__Last week
Price history PriceHistory__Last month
Price history PriceHistory__Last 2 years
Price history PriceHistory__Last 5 years
Price history PriceHistory__Last 10 years
Price history PriceHistory__Last 30 years
Price history PriceHistory__All data
........
Once you print out the list of status, you can just pick up one and use "urllib.urlencode" function to create a valid query:
>>> url_params = {'input':'GOOG', 'appid':'appid', 'podstate':'Quote__More'}
>>> data = urllib.urlencode(url_params)
>>> data
'input=GOOG&podstate=Quote__More&appid=appid'
If you want to specify more than one pod state, you may not directly put them into "url_params" list above in the dictionary form. Because the dictionary object does not allow duplicated key, items with the same key are discarded but the last one. Instead you can use iteration with string manipuation to append the pod states to the target. For instance:
>>> url_params = {'input':'GOOG', 'appid':'appid'}
>>> data = urllib.urlencode(url_params)
>>> data
'input=ip&appid=appid'
>>> for ele in {'Quote__more','PriceHistory__All data'}:
... data+='&'
... data+=f(ele)
...
>>> data
'input=GOOG&appid=appid&podstate=PriceHistory__All+data&podstate=Quote__more'
where the function
f is defined as
>>> def f(podSt):
... return urllib.urlencode({'podstate':podSt})
You should be able to handshake with the WA server and obtain a new piece of XML data containing more detailed data for GOOG stock in terms of the 'Latest trade' and 'Price history'
base_url = 'http : // api.wolframalpha.com/v2/query?'
headers = {'User - Agent' : None}
req = urllib2.Request (base_url, data, headers)
xml = urllib2.urlopen (req).read ()
Result comparison
1. < plaintext > in the new xml has one more "open" price
2. <states> has the attribute <count = 2> instead of 1 in the old xml file. This action creates a dynamic update of the controls on the web interface as well: after you click the more button in the "Latest trade" pod, the button splits into two more buttons.
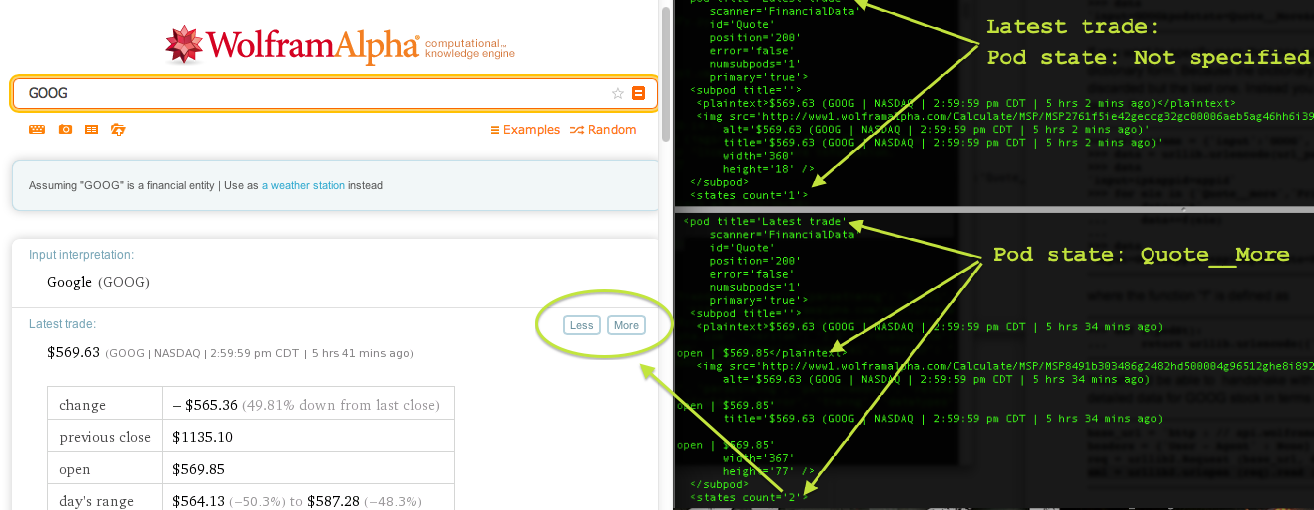
Sometimes not all data are available through API. In this paticular pod, you can see another "More" button after you click it for the first time. To get the second level of expansion, you can
put a "n@" in front of the "Quote__more" option. Reload the urlopen you will have more entries such as rows for ask and bid.
>>> dataNew = 'input=GOOG&appid=appid&podstate=PriceHistory__All+data&podstate=2@Quote__more'
I will leave the assumption part as your practice problem if you want to command more for query techniques using Python. If you have any idea and want to comment, feel free to write it down below.
 Attachments:
Attachments:


