For importing pdf documents, Version 13 introduced a larger variety of importable elements such as embedded images, etc. These can be very useful.
I am wondering if anybody has worked out how to do the following: Extract equations from a pdf of a journal article.
For example, 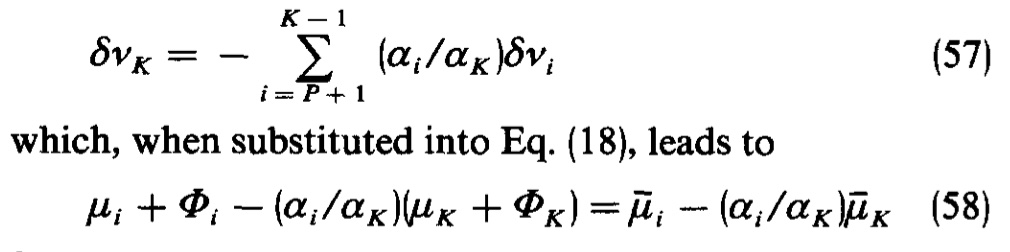 it would be useful to construct a way to have thumbnails of the equations.
it would be useful to construct a way to have thumbnails of the equations.
Why? When I read pdfs of papers on my laptop or tablet, its a PITA to scroll back to equation 18 to figure out what the author is doing. If I had a document open with just the equations--that document being programmatically created by WL--reading papers on screens would be simplified.... I think.


