How well does an LLM do on the original televised Jeopardy that Watson did? My guess is that the LLM will pretty much nail it but the way it's doing it, is very different. Even though the effect will be somewhat the same. But that's a thought on that. I mean it's a very different, these approaches are very different from what we're doing with Wolfram Alpha or Wolfram Language where we're actually computing answers. In the text retrieval cases you're literally pulling out those pieces of text. In the LLM case you're pulling out that statistical pattern that you learned from the pattern of a piece of text..Wolfram Language is a useful tool for humans, it's also become a useful tool for AIs. Presumably there's a human at the end of the chain who's asking the AI to do something, and then the AI's asking our technology to do something..but the dynamic is that the LLM is providing this linguistic interface to this computation so it's sort of a hierarchy of things, from the pure text retrieval to the statistical ground up thing to the actual computation side of things.
model101 =
NetInitialize[
NetChain[{ConvolutionLayer[64, {3, 3}, "Stride" -> 2], Ramp,
ConvolutionLayer[128, {3, 3}, "Stride" -> 2], Ramp,
ConvolutionLayer[256, {3, 3}, "Stride" -> 2], Ramp,
ElementwiseLayer[0.5*Sin[0.5*Pi #] &],
DeconvolutionLayer[256, {3, 3}, "Stride" -> 2], Ramp,
DeconvolutionLayer[128, {3, 3}, "Stride" -> 2], Ramp,
DeconvolutionLayer[64, {3, 3}, "Stride" -> 2], Ramp,
DeconvolutionLayer[3, {3, 3}, "Stride" -> 1], LogisticSigmoid},
"Input" ->
NetEncoder[{"Image", ImageSize -> 64, ColorSpace -> "RGB"}],
"Output" -> NetDecoder["Image"]]];
data1 = ResourceData["CIFAR-100"];
trainingdata101 = data1[[1 ;; 500]];
trainedmodel101 =
NetTrain[model101,
trainingdata101[[All, 1]] -> trainingdata101[[All, 1]],
MaxTrainingRounds -> 5];
modified01 =
NetChain[{trainedmodel101, ElementwiseLayer[Sin[Pi #] &],
ElementwiseLayer[# + 0.1*Sin[20 #] &] },
"Input" ->
NetEncoder[{"Image", ImageSize -> 64, ColorSpace -> "RGB"}],
"Output" -> NetDecoder["Image"]];
searchQuery = "Abstract Art";
scapes = WebImageSearch[searchQuery, MaxItems -> 8];
webImages = scapes;
originalProcessed = trainedmodel101 /@ webImages;
modifiedProcessed = modified01 /@ webImages;
comparisonGrid =
Grid[{{Style["Original Web Images", Bold, 14],
Style["Autoencoder Output", Bold, 14],
Style["Artistic Output", Bold, 14]}, {ImageCollage[webImages,
ImageSize -> Medium],
ImageCollage[originalProcessed, ImageSize -> Medium],
ImageCollage[modifiedProcessed, ImageSize -> Medium]}},
Frame -> All, Spacings -> {2, 2},
Background -> {{LightBlue}, None}];
comparisonGrid
@Fizra Khan designed an autoencoder with a straightforward convolution-deconvolution architecture; sinusoidal elementwise layers introduced emulations to modify the visual phenomena observed during migraine aura. Here, skip connections (or residual connections) help the network retain high-resolution details by assessing LLMs, like ChatGPT I think had about 400 layers in the neural net. And you're sending that data through those layers and it takes a certain amount of time and it has to go through all those layers for every token it produces. Now, can one distill the neural net so that it has fewer layers? Can it have faster hardware to run it on? Those are all things one expects to be possible. It'll speed up, can one win the Jeopardy given that, given the timing information? That is how skip connections ameliorate gradient flow during training but also stabilize feature propagation, leading to higher-quality reconstructions.

The architecture now starts with a series of convolutional layers that gradually reduce the spatial dimensions while increasing the depth of the learned representations. Back in my undergrad I did a lot of philosophy, did some karate lessons and practiced the Socratic method which I think is going to show how I had already incorporated a modified non-linearity via a sinusoidal function after the furthest-most convolutional layer. These days in our extended design, we propose to add skip connections between corresponding encoding and decoding layers. For instance, feature maps from the first convolution layer can be concatenated with those from the last deconvolution layer; low-level details (such as edges & textures) we preserve through the reconstruction process.
model = NetInitialize@
NetChain[{ConvolutionLayer[64, 3], Ramp, ConvolutionLayer[128, 3],
Ramp, ConvolutionLayer[256, 3], Ramp, DeconvolutionLayer[256, 5],
Ramp, DeconvolutionLayer[128, 3], Ramp,
DeconvolutionLayer[32, 3, PaddingSize -> 1], Ramp,
DeconvolutionLayer[3, 3, PaddingSize -> 1]},
"Input" -> NetEncoder[{"Image", ImageSize -> 32}],
"Output" -> NetDecoder["Image"]];
data = ResourceData["CIFAR-100"];
trainingData = data[[1 ;; 200]];
trainedModel =
NetTrain[model, trainingData[[All, 1]] -> trainingData[[All, 1]],
MaxTrainingRounds -> 2, BatchSize -> 8];
enhancedModel = trainedModel;
Do[enhancedModel =
NetInsert[enhancedModel,
ElementwiseLayer[
0.5 Sin[(0.25 + 0.25*k) Pi #] &], {2, 4, 6, 8, 10, 12}[[
k]] + (k - 1)], {k, 6}];
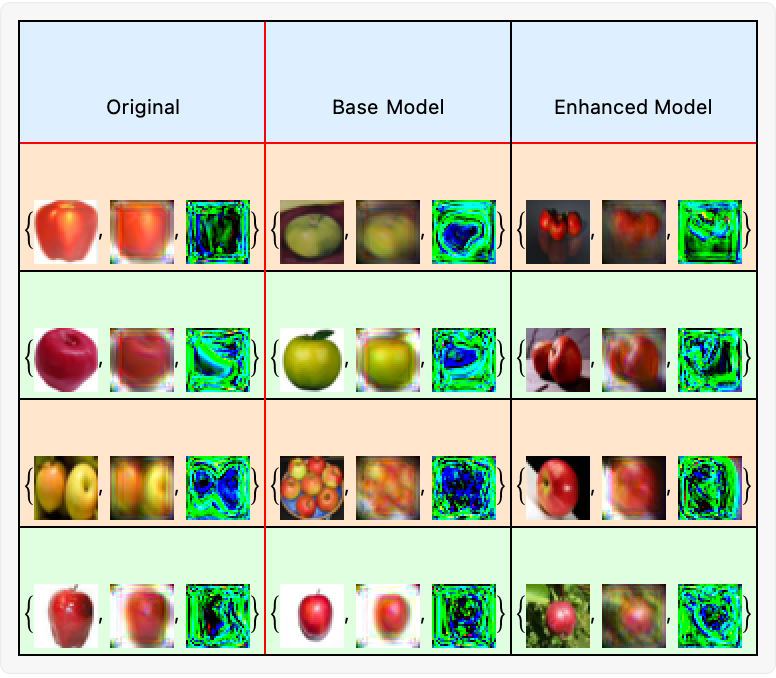
comparisonSet = Table[original = trainingData[[t, 1]];
baseOutput = trainedModel[original];
enhancedOutput = enhancedModel[original];
{original, baseOutput, enhancedOutput}, {t, 12}];
Grid[{{"Original", "Base Model", "Enhanced Model"},
Sequence @@ Partition[comparisonSet, 3]}, Frame -> All,
Dividers -> {{2 -> Red}, {2 -> Red}},
Background -> {None, {LightBlue, {LightOrange, LightGreen}}},
ItemSize -> {Automatic, 6}] // Panel
Skip connections, it's like Reebok..is it possible that one day we will predict the weather years in advance? I think that the answer is no, one is the sort of computational irreducibility in that turbulence and all those things but in the end, you need to know precisely the way the world is set up and what tree is growing on what hill and how much plankton is there in this piece of the ocean that causes this or that thing? To know, predicting the weather far in advance, how much traffic is gonna be on the road and predict this in that way? What level of general prediction can you make? This is one of the challenges of climate work; will it be raining in this place or that it's really hard to predict! Things about clouds, how clouds form and et cetera et cetera et cetera. It's very challenging, because are there things you can say in generality and approximately versus things you can say about weather prediction. The transition between those statements is really tricky! Because you can't simulate every single blade of grass or whatnot..the ten kilometers on a side or something like that is the grid of what you can do very long-term climate prediction from, A very coarse grid, so anything that matters about this particular cliff that has this particular air flow, you're out of luck it's just a ten kilometer square grid section. It's super hard to know what will happen, and there's one thing to do is a computer simulation. Another thing to do is given this effect, increasing water retention in the atmosphere, can we make a kind of physics-understandable, human-understandable argument..one is kind of reason it through natural philosophy style and two is run the computer simulation and hope you got all the "answers" parameters right and then if you agree and not cheat then it's really hard. The closer you get to actually doing climate modeling on the ground with computer systems, it's like showing your hamster, your restructured Syrian hamster how to restructure its nest into a form that "remembers' the intermediate representations. In Wolfram Language, this is often achieved by using the NetGraph construct rather than a simple NetChain. A Schematic version of such an architecture might look something like a 1x1 convolutional transformational layer. One might twirl around and practice checking that yes, the spatial dimensions and the number of channels of the feature maps are compatible when merging.
trainingdata101 = data1[[1 ;; 200]];
To train this extended autoencoder, the CIFAR-100 dataset is again used for its diversity in image content. For instance, selecting a subset of images for expedited training can be done by calculating data1 = ResourceData["CIFAR-10"], by updating the weights in both the convolutional & deconvolutional layers, including those the skip connections affect. The added paths, open doors to additional gradient routes, potentially finding a pathway for the network to converge faster and generalize better. Hi @Fizra Khan I try to read all of these lines of code that are submitted but I can't verify that I have read every single line of code but I have read almost all of everything that is submitted.
model01 = Import["/Users/deangladish/Downloads/WSS22-project-main/trainedmodel101.wlnet"]

You know how in physics something similar happens in Wigner's friend scenario where we can model the convolution layers. Luckily a lot of the stuff that you've written @Fizra Khan aims to use these convolutional neural networks whether it's a migraine headache, flashing lights, zigzag lines, blind spots, and we can understand the underlying mechanisms, of the migraine aura.
modified01 =
NetInsert[model01, ElementwiseLayer[0.5 Sin[0.5 Pi #] &], 13]

I guess the idea of incorporating sine waves demonstrates the adaptability and agility that simulates the visual patterns with varying frequencies.
images =
Table[{model01[trainingdata101[[t, 1]]],
modified01[trainingdata101[[t, 1]]]}, {t, 195, 200}];
ImageAssemble[images, ImageSize -> 150]

net = NetModel[
"Enhanced Super-Resolution GAN Trained on DIV2K, Flickr2K and OST \
Data"];
searchQuery = "Beach";
scape = WebImageSearch[SearchQueryString[searchQuery], "Thumbnails",
MaxItems -> 15];
images = ImageResize[#, {50, 50}] & /@ scape;
net01 = NetReplacePart[net,
"Input" -> NetEncoder[{"Image", ImageSize -> 50}]];
alteredImages = {};
Do[fn = If[i <= 5, Ramp,
If[i <= 10, Tanh,
LogisticSigmoid]];
alteredImage =
NetInsert[net01, "alteration" -> ElementwiseLayer[fn], "conv2"][
images[[i]]];
AppendTo[alteredImages, alteredImage],
{i, 1, 15}
];
grid = Grid[Partition[alteredImages, 5]]

@Fizra Khan That was so fire, designing the filter weights in the encoder by manipulating them, generating the visual disturbances associated with migraine aura and occipital epilepsy overall.
Row[
Table[
altered01 = net01;
layer01 = "conv1";
weights01 = Normal[altered01[[layer01, "Weights"]]];
weights01[[filter]] *= 10;
altered01[[layer01, "Weights"]] = weights01;
altered01[images[[2]]],
{filter, {60, 45, 26, 14}}
]
]

This is an extreme impression, the sine-blobs and the individual weights that make the zigzag lines and scotoma-type visuals. It would be fair to employ mathematical models like reaction-diffusion equations for cortical spreading and depression (CSD).


