I have the following xlsx dataset: 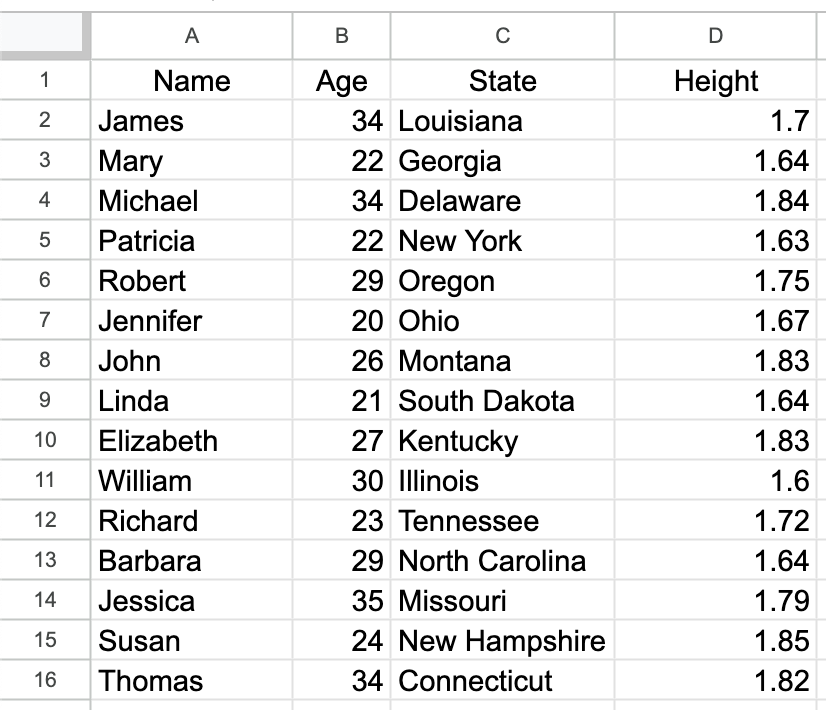
- I want to import only the
"Age" and "State" columns into my notebook. Can I use "SkipLines" to achieve it?
What I do now is
Import["example-dataset.xlsx",
{"Dataset",(*Import as a dataset*)
1,(*Import only the 1st sheet*)
All,(*Import all rows*)
{1, 2, 4}},(*Import only the 1st, 2nd and 4th columns*)
"HeaderLines" -> {1, 1} (*1st row and 1st column are headers*)
]
I tried Import["example-dataset.xlsx",{"Dataset", 1}, "HeaderLines" -> {1, 1}, "SkipLines" -> {0, {2, 4}}] but it doesn't work.
- I prepared this spreadsheet in Google sheets. For some reason, the sheet is 1000 rows long, so there are a lot of empty rows below the last meaningful row:
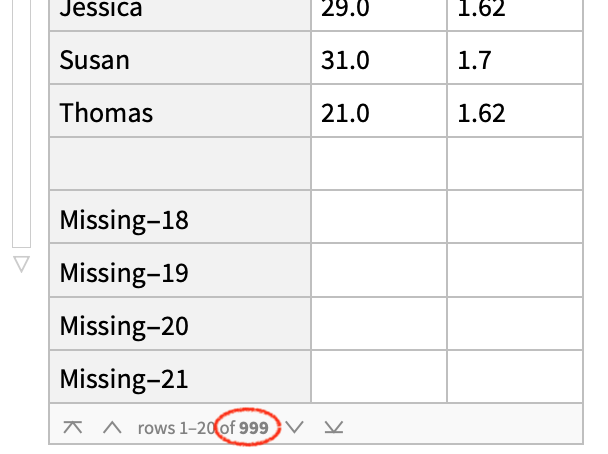
How can I tell Wolfram not to import those ~1000 empty rows into the dataset? I tried "EmptyField" -> None and "EmptyField" -> Null but it doesn't help. Maybe I should use SkipLines->17;; to skip all lines but it doesn't work either.
 Attachments:
Attachments:


