Dear Jim,
thank you very much for your reply. It was very useful. Your suggestion to use
data[[All, 4]] = -data[[All, 4]];
had already come to mind, but I use
data[[2 ;;]] /. {a_, b_, c_, d_} /; d == 1 -> {a, b, c, "zz1"}
instead, as it gives more flexibility as to which variable to use as a base. The idea, however, is the same as yours: using the fact that Mathematica lexicographical ordering and then just "renaming" the variables. My complete GLM then looks like this:
GeneralizedLinearModelFit[Reverse /@ (data[[2 ;;]] /. {a_, b_, c_, d_} /; d == 1 -> {a, b, c, "zz1"}), {x, y, z}, {x, y, z}, ExponentialFamily -> "Binomial",NominalVariables -> x]["ParameterTable"]
In this case I obtain the exact same result as shown on the website for R:
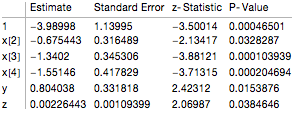
I still believe that this is a rather "dirty" fix and it would be nice if there was a built-in option, perhaps an undocumented one. It kind of lacks the elegance of a typical Mathematica command. I am aware that it is quite easy to convert all these numbers into one another, but as you say, it would be nice to have an option for that.
Using IncludeConstantBasis -> False is similar to the renaming of the variables. It is useful, but not as elegant and for some applications it would be nice to use the ConstantBasis.
Regarding the mixed models you are right, too. As you say, they are not easy to implement. At the moment I use Mathematica's RLink to use the same functionality of R. I would rather have everything within the framework of Mathematica.
As a research statistician at the Pacific Southwest Research Station you must come across many situations where both GLMs and Mixed Effect Models can be quite useful. There is a whole range of really cool topics you are working on. You must be using an incredible wealth of modelling and statistics.
Thanks again for your reply.
Cheers,
Marco
PS: I really like your bat occupancy model in the Demonstrations.


