Hi everyone,
if it was English the function DeleteStopwords would be quite handy. But luckily it is easy to make your own stop word function. So, David, has done all the hard work. (I am not contributing much, but had some time to spare...) So, like David, I import the words.
text = Import["~/Desktop/7_5150.pdf", "Plaintext"];
with TextWords, I get a list of the words:
wordlist = TextWords[text];
Problem is I don't have stop words, i.e. "useless" or content-free small words. Luckily there are hundreds of websites with lists of them. This commands imports a list of these words from a website I found:
stopwordsspanish = TextWords@Import["https://sites.google.com/site/kevinbouge/stopwords-lists/stopwords_es.txt?attredirects=0&d=1"];
Here is David's tally:
Reverse@SortBy[Tally[Select[ToLowerCase[wordlist], ! StringMatchQ[#, stopwordsspanish] &]], #[[2]] &]
The word cloud looks like this:
WordCloud[Select[ToLowerCase[wordlist], ! StringMatchQ[#, stopwordsspanish] &]]

Here's a BarChart of that:
BarChart[(Reverse@SortBy[Tally[Select[ToLowerCase[wordlist], !StringMatchQ[#, stopwordsspanish] &]], #[[2]] &])[[1 ;; 20, 2]], ChartLabels -> Evaluate[Rotate[#, Pi/2] & /@ (Reverse@SortBy[Tally[Select[ToLowerCase[wordlist], ! StringMatchQ[#,stopwordsspanish] &]], #[[2]] &])[[1 ;; 20, 1]]]]
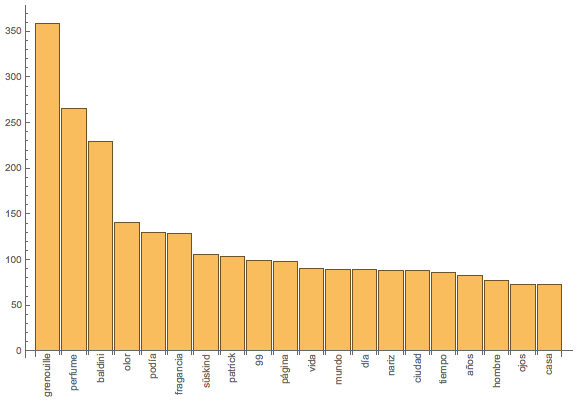
Looking at this, it appears to be the most inefficient way to program it; i.e. I do all the heavy StringMatching and Tally twice, but luckily the programmers at Wolfram were taking care of making the code fast so that I can be a bit lazy...
Ok, this was a minimal contribution, but I hope it helps with the stop word problem.
Cheers,
Marco
PS: Is it actually legal to post the pdf of that book online?


