Absolutely marvelous! But could there be another way? I think many. Here is one.
Don't you think ranking letters according the order they appear in the alphabet is sort of random? I suggest we rank them according to their frequency in the full dictionary.
letterRANK = MapIndexed[Prepend[#1, First[#2]] &,
Sort[Tally[Select[Flatten[Characters[ToLowerCase[WordData[]]]], LetterQ]], #1[[2]] > #2[[2]] &]];
As you can see (first number) I ranked (gave most points) the highest the rarest letters. I consider them jems because I guess they make up the rarest (I hope the funniest?) words.
Multicolumn[letterRANK, 2]

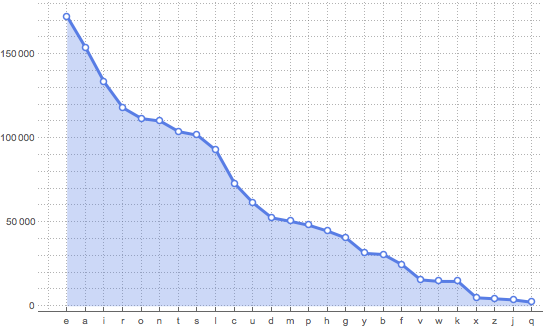
And I must say the frequencies do give a weird graph:
ListLinePlot[letterRANK[[All, 3]], PlotTheme -> "Business", Filling -> Bottom,
FrameTicks -> { {Automatic, None}, {letterRANK[[All, {1, 2}]], None}}, GridLines -> All]
Now let's make our little indexed database:
indexRANKED = Association[Thread[letterRANK[[All, 2]] -> letterRANK[[All, 1]]]]

Here is Rodrigo's function:
wordValue[word_String] :=
Total[Lookup[indexRANKED, #, 0] & /@ StringPartition[ToLowerCase@RemoveDiacritics@word, 1]]
and here it is - our new jem-like 100-points scoring words:
words100 = Select[DictionaryLookup[], wordValue[#] == 100 &];
But let's go a step further. Consider the most POPular words those who get 100 points the quickest --- with least amount of letters. And consider the most RARE words those who get 100 points the slowest --- with most amount of letters. We weigh them according to this logic for word cloud:
weightPOP = {#, 1/StringLength[#]} & /@ Union[ToLowerCase[words100]];
weightRARE = {#, StringLength[#]} & /@ Union[ToLowerCase[words100]];
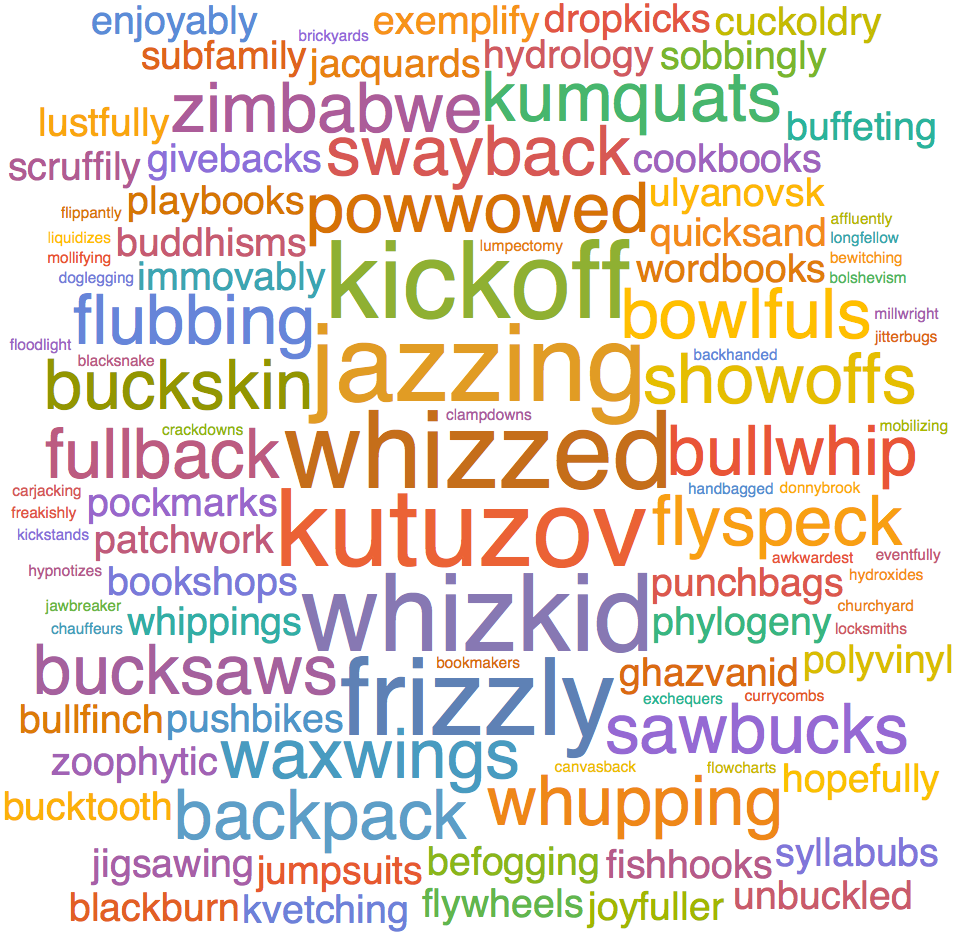
And now behold their corresponding word clouds - I bet you will grab the dictionary. A recent quote from a friend looking at this "I'm thrilled to my very kutuzov." ;-)
WordCloud[weightPOP]
WordCloud[weightRARE, ScalingFunctions -> (#^2 &)]