In this post I will discuss how to go about using classify on a standard academic machine learning data set - which I have included in the post for download. More details about the Iris data can be found here. I also included a copy of the notebook that can be downloaded. This data set contains the Sepal Width/Length and the Petal Width/Length information for 150 flowers. These flowers are grouped into 3 sets of 50 - each representing a family of the Iris flower family.
I was inspired to write this post after reading a basic question on the stack exchange which had to deal with how to go about splitting a dataset up into training / testing data for analysis. I decided not only to answer the question but to write a post that would address how to properly curate data and Datasets[] in particular to be machine learned by various methods.
First I need to import our data. Similiar to another post I made about setting up searchable databases we are going to use SemanitcImport[] which automatically structures the imported data into a Dataset[].
initialData =
SemanticImport[
"C:\\Users\\YottaTech\\Desktop\\Wolfram Samples\\iris.csv"]
Now we need to mix the data up a bit. The problem with it now is that all of each type of flower is stored sequentially in the data set so that if we were to split it half - we would not get nice training / testing data - since all of the species are clumped together. The RandomSample[] function allows us to mix the data easily.
data = RandomSample[initialData]
Now we need to curate the data set into associations that can be fed into the Classify[] function. We will want to pair each set of numerical values - located in the first four elements of each entry - with the name of the flower specie located in the 5th entry. I demonstrate this process on a single entry bellow.
ToString[data[1][[5]]] -> Values[data[1][[1 ;; 4]]]

Now I will set up a table to iterate over all the entries and do the above operation as well as pass the GroupBy[] function over the table of results. This takes the names and list of values in each pairing and creates and association out of it - as well as combines all the associations into one large set. I do this twice: once on the first half of the data and once on the second half of the data so that I can create two separate objects - trainingData and testingData. These will be used to train and test our classifier function using various methods.
trainingData =
GroupBy[Table[
ToString[data[i][[5]]] -> Values[data[i][[1 ;; 4]]], {i, 1,
Length[data]/2}], First -> Last];
testingData =
GroupBy[Table[
ToString[data[i][[5]]] -> Values[data[i][[1 ;; 4]]], {i,
Length[data]/2 + 1, Length[data]}], First -> Last];
trainingData

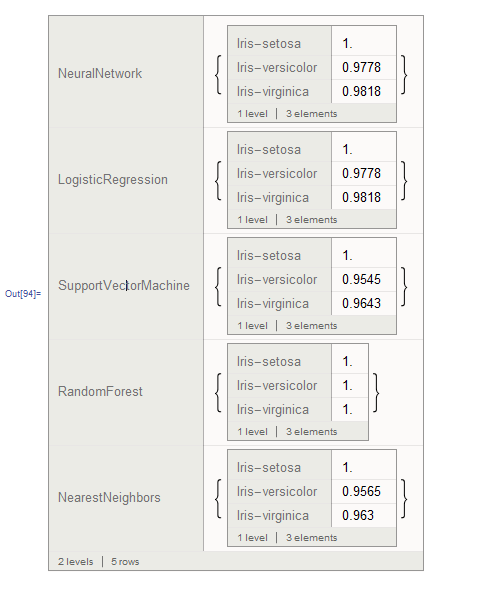
Now I create multiple classifier functions using the trainingData and test them using the testingData. By using a table iterating over all the possible classification methods and paring the label of each method with its accuracy outputs; I can compare and contrast how different methods preform on classifying each of the different plant species based on their numerical data. I nest Datasets[] to make this look really pretty.
results =
Dataset@GroupBy[Table[
c1 = Classify[imagedata1, Method -> method,
PerformanceGoal -> "Quality"];
method ->
Dataset@ClassifierMeasurements[c1, testingData, "FScore"],
{method, {"NeuralNetwork", "LogisticRegression",
"SupportVectorMachine", "RandomForest", "NearestNeighbors"}}],
First -> Last]
I have extended and automated this process for multiple data sources and will be making a post about a toolkit to do this type of stuff in the future. Let me know if you have any questions / suggestions moving forward!


