New file formats are emerging to encode data for storage, and our tools have to constantly play catch up to support these. The file formats specify how the bits are used to encode the information in the digital storage medium. There are no great ways of analyzing the information independently of structure. Currently, most file analysis have been through observing the hex editors, disassembler and debuggers. Though hex data is an exact representation of the data file, it is difficult to sift through.
Humans are naturally good at processing spatial information. Our hopes is to use Mathematica as tool to analyze a file's binary much faster if we are able to translate it into some visual representation we can see. Given this, we want to explore different ways to which we can analyze the files visually by transforming its binary values into 2D/3D spatial information independent of file type. This is very useful in scenarios which require low-level analysis such as...
- Identify unknown file format
- Compare files
- Analyze files for vulnerability
- Locate and extract hidden content or metadata (Forensic analysis)
- Find keys or password in files (Cryptanalysis)
- Locating malicious codes within files
Byte View
One simple method we can visualize files is by coloring corresponding byte values. This view is great for observing the byte distribution and file layout. We read in the files as chunks of 8-bit character encoding. This gives us 256 different byte values. We read contents of file into Mathematica in binary by using BinaryReadList, which brings in the file data as list of integers 0 to 255. We can then partition them into blocks and plot it by its default values. For a better understanding of the byte distribution in a file, we can choose our own color scheme. So, let's begin by picking a color scheme to classify the different bytes by defining our own ColorFunction.

This covers the common class types in 8-bit encoding ASCII.
Next, we want to visualize the stream of bytes as a 2D array where we can examine or zoom into parts of files by modifying the start and end point or block size by using Dynamic and Slider, allowing us to adjust the parameters of what we enter in ArrayPlot and observe in realtime. I produced the following plots by taking the following samples of different file extensions such as our beloved notepad++ editor executable (first).
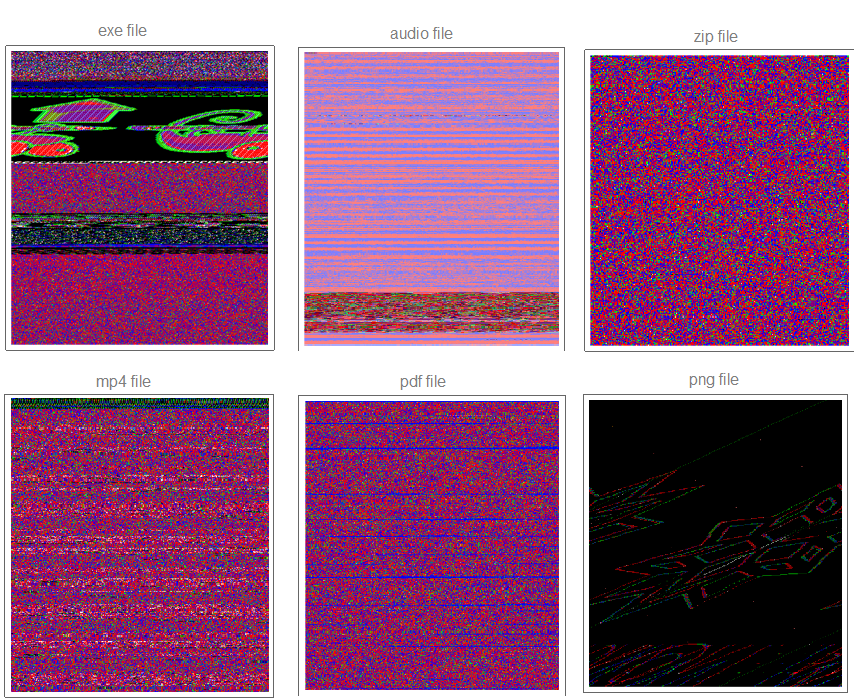
We noticed right away different formats have different byte view characteristics in the samples above. For example, PDF would show strips of red and blue colors, while a compressed file (ZIP) would show homogeneous distribution of red, blue, and green colors. We see a hidden image within Notepad++ executable, which shows that this view may be useful in stenography analysis.
Digraph Dot Plot View
Dot plot view is great way to determine the file format and visualize the byte distribution. We partition the stream of bytes into pairs with offset one using Partition. The plot also allows us to understand what sequence of bytes often appears net to each other. Let's take a close look at the digraph of an executable file below plotting 10,000 bytes at a time.
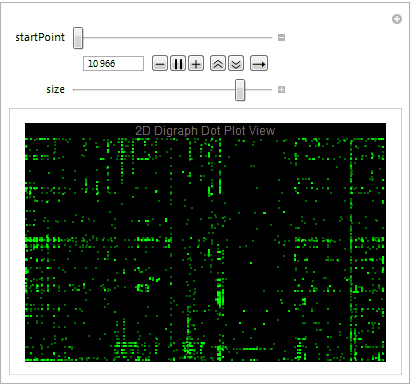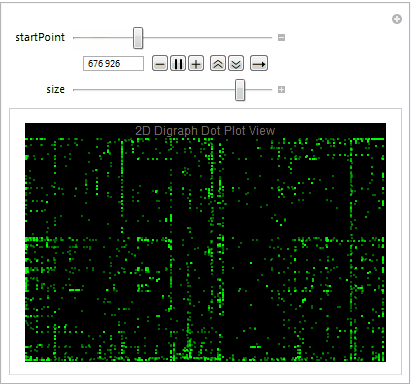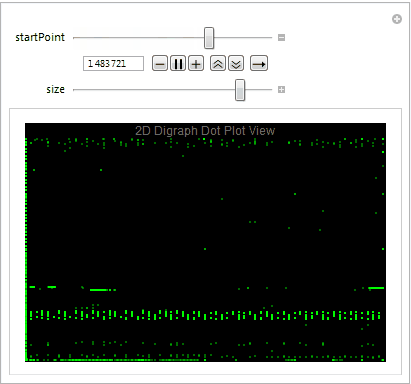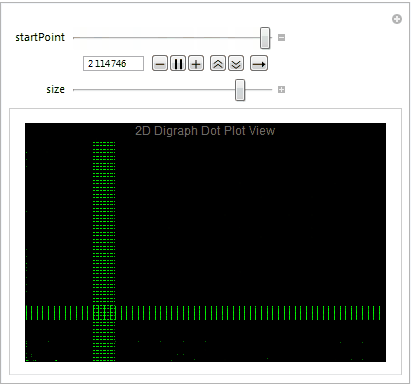 Mmmm....The Matrix.
Mmmm....The Matrix.
We easily observe that the executable files have a variety of behaviors as we use Manipulate to adjust our starting point in the file. We can then take blocks of 2D digraph dot plot of the file and stack them on top of each other to give the layered digraph plot view. Here's a sample image with the exe file.
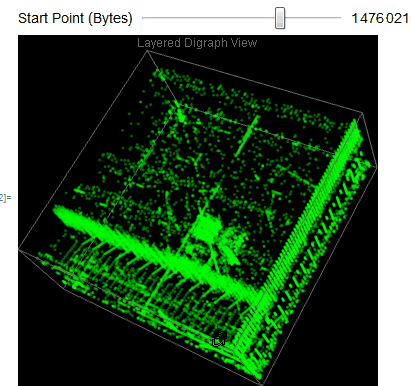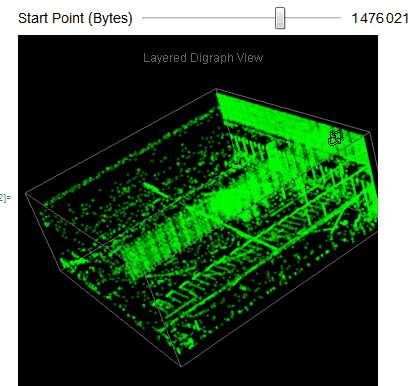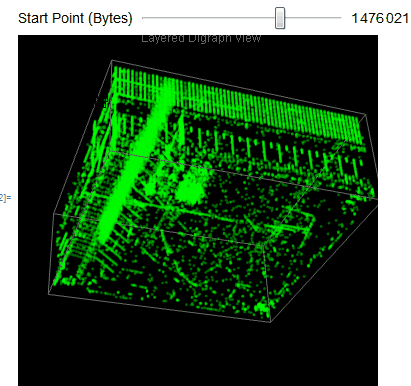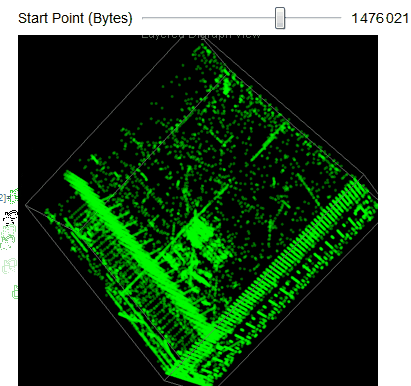
We see different characteristics emerge when using different sample input files. The different sequence of bytes generates different structures.
Hilbert Curve View
With byte view, small-scaled features that are only a few lines long tend to get lost. We can solve this by using the Hilbert curve. The Hilbert curve method maps the 1D sequence of bytes to a 2D image while preserving their locality. We generate it by recursively creating curves using SubstitutionSystem with the encoded rules: "L" -> "+RF-LFL-FR+" and "R" -> "-LF+RFR+FL-". Here is a side-by-side comparison of Hilbert curve view versus byte view of exe file.
 versus
versus 
Calculating Entropy and Malware Detection
We can use the Hilbert curve to visualize local entropy of the neighboring bytes in different files. Think of entropy as the degree to which a chunk of data is disordered. If we have a data set where all the elements have the same value, the amount of disorder is nil, and the entropy is zero. If the data set has the maximum amount of heterogeneity (i.e. all possible symbols are represented equally), then we also have the maximum amount of disorder, and thus the maximum amount of entropy. I calculated it using Shannon entropy over a sliding window of 128 bytes.
High-entropy data are of special interest to reverse engineers and penetration testers. The first is compressed data - finding and extracting compressed sections is a common task in many security audits. The second is cryptographic materials such as keys, certificates, and encrypted data.
Malware analysis can also be carried out. Malware developers use obfuscation techniques that hides the malware's content from detection and analysis. This is done by bit manipulations or using advanced cryptographic standards (i.e. DES, AES, etc), makes binary data unreadable or hard to understand so their programs. But, the obfuscation introduces high-entropy in its area of residence. Image below was generated using a sample executable packed with a p2p virus.
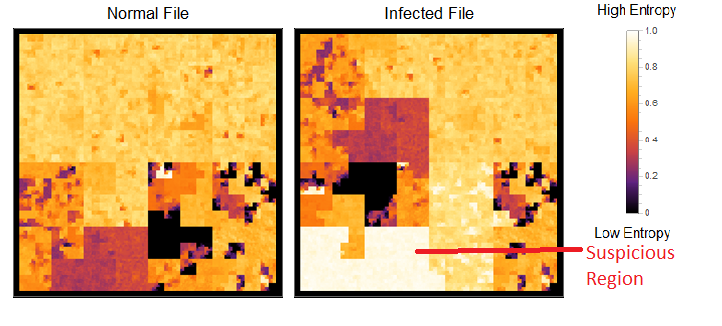
It's easy to find the location of the virus with this view. There's a defined block of region with high entropy where it resides.
Open Problems
Each file format shows a unique signature that can be easy for users to identify. There's some many ways one can expand upon this project. One is the problem of help automating the classifications of files, especially if it is unknown or corrupted. We can look into the subtle differences between similar file formats or determine different markers to increase classification accuracy. We can further adjust and refine the code to be able to handle larger blocks of files. We can also improve malware detection using our entropy view. I hope to make the interface more interactive to include real-time hex locator. There are other different low-level analysis applications we can explore to improve the process.


