Thales, this is quite nice! BTW I think you did not define SortByLength. I thought I should recreate this in a bit different manner. Note various places, such as using TextCases and TextWords to simplify regular expressions processing. I started from resource data - we can search for availability:
ResourceSearch["Shakespeares Sonnets"]

Then download the data:
raw = ResourceData["Shakespeare's Sonnets"];
This will split into separate sonnets and delete noise such as roman numeral for sonnet number:
sonnets = Select[TextCases[raw, "Paragraph"], StringLength[#] > 10 &];
So we have Length@sonnets 154 sonnets. Some do not have 14 lines
In[]:= Position[Length/@StringSplit[sonnets,"\n"],x_/;x!=14]
Out[]= {{39},{99},{126}}
so we delete them:
sonnets14 = DeleteCases[sonnets,
Alternatives @@ Extract[sonnets, {{39}, {99}, {126}}]];
Find last words in every line:
lastWords = Map[Last[TextWords[#]] &, StringSplit[sonnets14, "\n"], {2}]
and following the rhyming pattern you suggested:
rhymePatt = {1, 3, 2, 4, 5, 7, 6, 8, 9, 11, 10, 12, 13, 14};
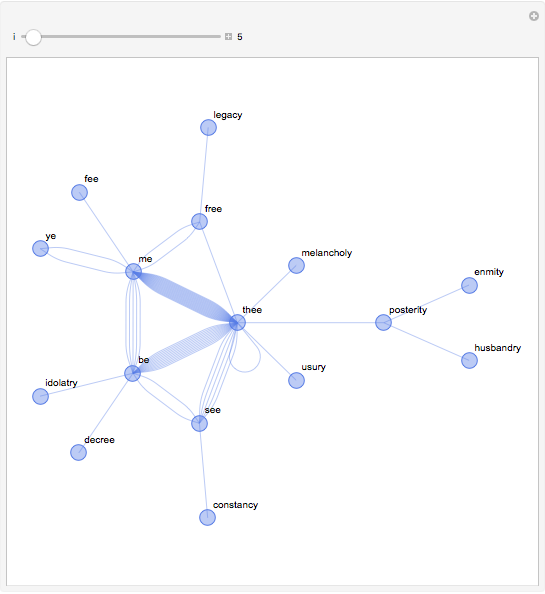
we can build the graph (I chose undirected graph, for alternative sake):
g = Graph[UndirectedEdge @@@ Flatten[Partition[#[[rhymePatt]], 2] & /@ lastWords, 1]]
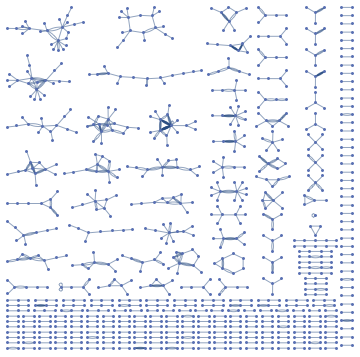
And finally computing subgraphs
subGra = Subgraph[g, #, VertexLabels -> "Name",
PlotTheme -> "Minimal", BaseStyle -> Opacity[.4],
ImageSize -> 500 {1, 1}] & /@ ConnectedComponents[g];
and building the app - I kept multiple edges to see what is more frequently used: