Open code in Cloud | Download code to Desktop via Attachments Below
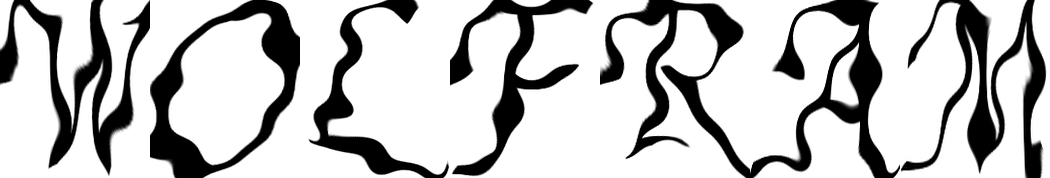
@Marco Thiel pointed me to an interesting project called The Venice Time Machine (see also a review video and a TED talk). The project aims to digitize and algorithmically process a wealth of data packed in ancient manuscripts. Some steps include the following:
SCANNING. Paper documents are turned into high-resolution digital images with the help of scanning machines.
TRANSCRIPTION. The graphical complexity and diversity of hand-written documents make transcription a daunting task. For the Venice Time Machine, scientists are currently developing novel algorithms that can transform images into probable words. The images are automatically broken down into sub-images that potentially represent words. Each sub-image is compared to other sub-images, and classified according to the shape of word it features. Each time a new word is transcribed, it allows millions of other word transcripts to be recognized in the database.
TEXT PROCESSING. The strings of probable words are then turned into possible sentences by a text processor. This step is accomplished by using, among other tools, algorithms inspired by protein structure analysis that can identify recurring patterns.

Because words in the manuscripts are mutually compared to identify similar features and ultimately same words - it reminded me of unsupervised learning. I wanted to play a bit with tech built in in Wolfram Language to see some toy examples at work. (Note, a supervised learning version of this was developed by Marco in a cool project Classifying Japanese characters from the Edo period).
To avoid hunting and cleaning real datasets, lets "simulate handwriting" reflecting on randomness of the character shapes. I also like it because it touches upon some art sides of things, relevant to generation of beautiful random fonts. And actually due to ancient writers' (for example monks) skills and attitudes often handwritten characters will differ less than the typed ones we distort here artificially (see image above). It's a different story of course if we to compare between handwritings of different authors, which is a challenge and what the Venice project envisions ultimately. This becomes even harder if the letters of a handwritten word are seamlessly connected.
I deal with single characters, not words. Let's define a function that makes an image from a letter:
raster[s_]:=ImagePad[ImageCrop[Rasterize[s,ImageSize->150]],50,White]
I padded it to give enough room for random distortions we will apply. Next function looks convoluted, but it is just a transformation formula that sends sin and cos waves over the letters to distort the shapes (think of your reflection in the water of a pond when you drop a stone there).
transf[rn_,amp_,fre_]:= #+{
amp Sin[rn[[1]]+fre(#[[1]]+#[[2]])]+amp Cos[rn[[2]]+fre(#[[1]]-#[[2]])],
amp Cos[rn[[1]]-fre(#[[1]]-#[[2]])]-amp Sin[rn[[2]]-fre(#[[1]]+#[[2]])]}&
The next function actually applies a random transformation to a letter image:
randTransf[amp_,fre_][i_]:=
With[{rn=RandomInteger[99,2]},ImageTransformation[i,transf[rn,amp,fre]]]
Trying this in action for the letters of the word WOLFRAM and "Felipa" font:
set:=ImagePad[#,-50,Red]&/@randTransf[.02,20]/@raster/@
(Style[#,FontFamily->"Felipa"]&/@Characters["WOLFRAM"])
set//ConformImages//ImageAssemble
Trying this twice and finding the difference reveals that different random samples differ quite strongly:
ImageSubtract[set//ConformImages//ImageAssemble,set//ConformImages//ImageAssemble

Lets generate 6 different random versions (each per a CPU core of my machine for parallel processing):
data=Flatten[ParallelTable[set,6]];
Thumbnail[#,50,Padding->None]&/@data

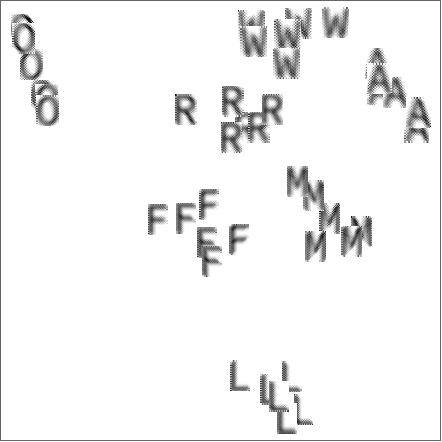
While letters look the same, if you pay attention to the details, the smaller features are different, - that reminds me of ink and hands effects on real paper. Now, to the machine learning. Here is Wolfram Language "out of the box" function, FeatureSpacePlot, that uses machine learning to deduce most relevant features of objects and find similar ones demonstrating the similarity in 2D space. Here the closer objects are more similar. It picks the similarity, correctly gathering letters into 7 different groups - each group for each letter in WOLFRAM:
FeatureSpacePlot[data,PlotTheme->"Frame"]

Let's try now another effect. I will increase the frequency of distortion making letters "fuzzy" (I cannot ignore the artistry of the visual :-) ). Repeated generations will give different small-scale features:
set:=ImagePad[#,-50,Red]&/@randTransf[.05,100]/@raster/@(Characters["WOLFRAM"])
set
While general shape is the same internal details are very different and noisy. Again generating 6 different sets and applying FeatureSpacePlot we are able to group properly:
data=Flatten[ParallelTable[set,6]];
Thumbnail[#,50,Padding->None]&/@data
FeatureSpacePlot[data, PlotTheme -> "Frame", PerformanceGoal -> "Quality"]
Of course, with more distortion we would need more sophisticated processing to find clusters of similarity. But this was fun to play with. It would be interesting to come up with something that could cluster same letters even between the 2 fonts shown at the top image in this post.
 Attachments:
Attachments:


