Hi Ilya,
Here is the code that I used. I generalized it to work with any language that WL has alphabet and dictionary data for. I verified it on English. Can you please verify that it works correctly for Russian. Thanks!
Two letter frequencies
Generate association of first two letters of words in the dictionary to frequency of occurrence. First and second letters are restricted to first and last letter in the alphabet. This eliminates words containing capitals or accented characters in the first two letters. For some reason DictionaryLookup[] for English has words which contain characters that are not part of Alphabet[] for English.
language = "Russian";
alphabet = Alphabet[language];
numLetters = alphabet // Length;
pairCounts =
alphabet //
Map[DictionaryLookup[{language, # ~~
CharacterRange[First@alphabet, Last@alphabet] ..}] &] //
Map[StringTake[#, 2] &] // Map[Counts];
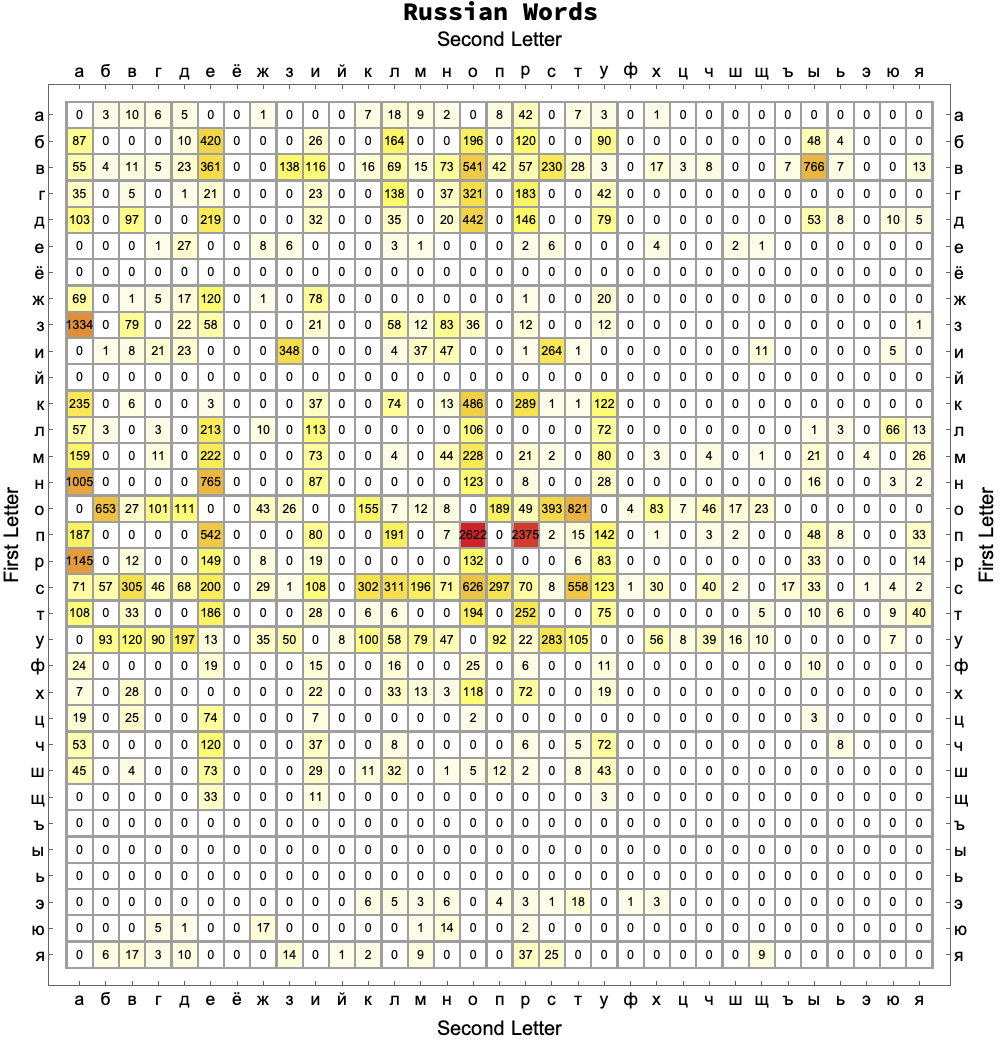
Matrix Plot
Several combinations do not occur so we need to add them to the association with a count of zero.
pairZeroCounts =
alphabet // Tuples[#, 2] & // Map[StringJoin] //
AssociationThread[#, ConstantArray[0, numLetters^2]] &;
allPairCounts = <|pairZeroCounts, pairCounts|>;
Generate matrix of frequencies and text strings of frequency values centered over matrix rows and columns.
matrixValues = allPairCounts // Values // Partition[#, numLetters] &;
epilog = MapIndexed[Text[Style[#, 10], #2 - 1/2] &, Transpose@Reverse@matrixValues, {2}];
Labels, ticks and MatrixPlot.
frameLabels = Style[#, 16, Black] & /@ {"Second Letter", "First Letter"};
ticks = Transpose[{Range@numLetters, alphabet // Map[Style[#, 14, Black] &]}];
matrixValues //
MatrixPlot[
#,
Mesh -> All,
FrameTicks -> {ticks, ticks, ticks, ticks},
FrameLabel -> Transpose[{frameLabels, frameLabels}],
PlotLegends ->
Placed[Style[language <> " Words", 20, Black, Bold], Above],
ColorFunction -> "TemperatureMap",
ColorRules -> {0 -> White},
ImageSize -> 800,
Epilog -> epilog] &
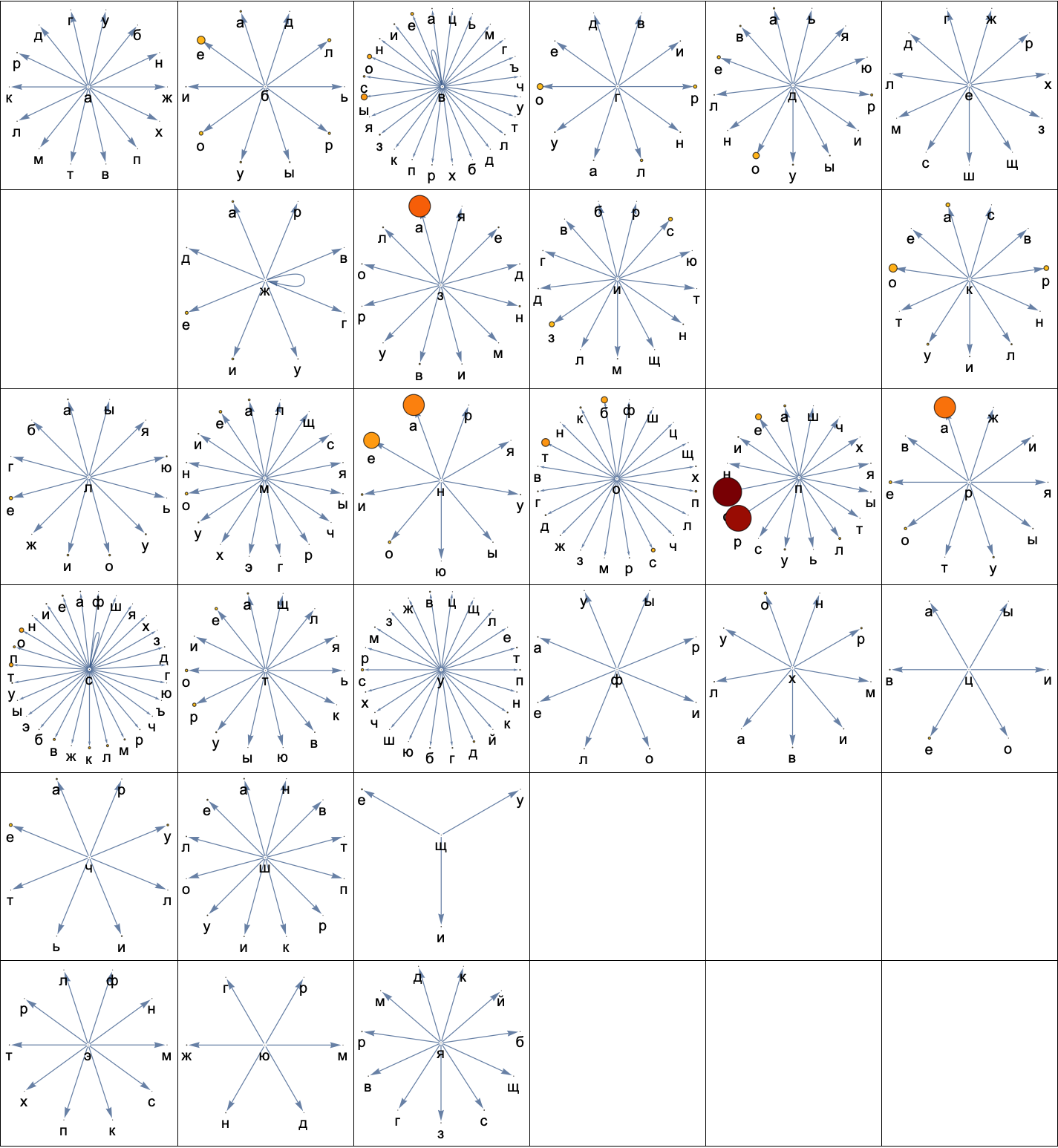
Graph
edges = pairCounts // Keys // Characters // Apply[DirectedEdge, #, {2}] &;
(* Association of second letter to frequency *)
weights = pairCounts // Map[KeyMap[StringTake[#, -1] &]];
(* Weight of 1 for second letters that do not occur *)
defaultWeights = Thread[alphabet -> ConstantArray[1, numLetters]] // Map[Association];
vertexWeights = MapThread[Association, {defaultWeights, weights}];
weightRange = vertexWeights // MinMax;
(* Helper to set VertexSize and VertexStyle *)
setProperties[graph_, index_] :=
Module[{scaledWeights = Rescale[vertexWeights[[First@index]], weightRange]},
SetProperty[graph,
{VertexSize -> {v_ :> scaledWeights[v]},
VertexStyle -> {v_ :> (ColorData[{"SolarColors", "Reversed"}]@scaledWeights[v])}}]]
G = edges // Map[Graph[#,
VertexLabels -> Placed["Name", Below],
VertexLabelStyle -> Directive[Black, 16],
GraphLayout -> "RadialEmbedding"] &];
G // MapIndexed[setProperties] // Partition[#, UpTo[6]] & // Grid[#, Frame -> All] &