Introduction
The idea of the project was to find the concepts that have the highest co-occurrence with specified Mathematical keywords. The data was scraped from research preprints as a source for math concepts and keywords using the arXiv API, and the highest occurring words were found using regular expressions, and processing using basic natural language processing.
Importing Data using ServiceConnect["ArXiv"]
arXiv = ServiceConnect["ArXiv"];
articles = arXiv["Search",{"Query" -> "Circles","MaxItems" -> 1}];
urls = Normal@articles[All,{"URL"}];
iurls = Flatten[Values[urls]];
furls = StringReplace[iurls,"http://arxiv.org/abs/"->"http://arxiv.org/pdf/"];
urldata = Quiet[Import[#,"Plaintext"]&/@ furls];
Importing Data using the arXiv API
url = "http://export.arxiv.org/api/query?search_query=all:circle&\start=0&max_results=1000";
import = Import[url, {"HTML", "XMLObject"}];
paperlinks =
Cases[import,
XMLElement[
"link", {"title" -> "pdf", "href" -> link_, ___, ___}, _] :>
link, Infinity];
data = Quiet[Import[#, "Plaintext"] & /@ paperlinks];
The data was imported using the API which can be found here. With a change in the max_results in the API, “n” number of papers can be imported and processed. With using the Cases function on the XMLElements of the page, we download all of the links with the tags “pdf”. The links are then imported in plaintext.
Cleaning of Data
deleteCases = DeleteCases[data (*|urldata*), $Failed];
whiteSpace =
StringReplace[#, WhitespaceCharacter .. -> " "] & /@ deleteCases;
mapS1 = StringDelete[#,
DigitCharacter ..] & /@ (StringSplit[#, "."] & /@ whiteSpace) //
Flatten;
mapS2 = List[ToLowerCase[#] & /@ mapS1];
The failed cases are deleted which are generated during the import, the whitespace characters are replaced to make the data more presentable, and the digit characters are deleted.
Searching for mathematical keywords in the papers
The data was converted to lower case to avoid the overhead of defining different switch cases to handle for user query input. The keywords were then searched using RegularExpression. A regular expression is a sequence of characters that define a search pattern. The RegularExpression (regex) we used to find out the words in the papers is as follows:
mapS2 = List[ToLowerCase[#] & /@ mapS1];
regx = StringCases[#, RegularExpression["\\bcircle(s?)\\b"]] & /@ mapS2;
The above regex captures any occurrences of ‘circle’ or ‘circles’, given that it is surrounded by a word boundary in the data, next we have to find out the position of the sentences containing ‘circle’ or ‘circles’
pos = Position[#, Except@{}, 1, Heads -> False] & /@ regx // Flatten;
To find occurrences of the associating word, we can consider the preceding and succeeding three sentences around the position of the word, with conditions as follows:
ifs = If[# > 3,
List[# - 3, # + 3]
, If[# <= 3, List[# + 3]]
, If[# >= Length[mapS2 // Flatten],
List[# - 3]]] & /@ pos // Flatten;
Extract the sentences using the new positions
mapS3 = Flatten[mapS2][[#]] & /@ ifs // Flatten;
We then delete the keyword (the word captured by the regex pattern) from the papers, remove the words if their length is less than three, and then delete the stopwords using the built-in function.
regxd = StringDelete[#, RegularExpression["\\bcircle(s?)\\b"]] & /@
mapS3 // Flatten;
ss = StringSplit[#, " "] & /@ regxd;
regxd1 = StringCases[#, RegularExpression["[a-zA-Z]+"]] & /@ ss //
Flatten;
mapS4 = Flatten[
DeleteCases[If[StringLength[#] >= 3, List[#]] & /@ regxd1, Null]];
deleteStopwords = List[StringRiffle[DeleteStopwords[#] & /@ mapS4]];
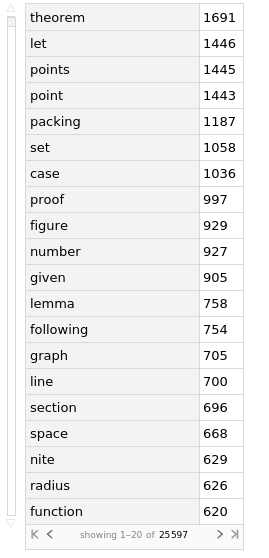
We can look at the words co-occurring most often with the keywords in a Dataset
WordCounts[StringRiffle[deleteStopwords]] // Dataset
Issues
A problem I faced while testing an initial version of the code was that of efficiency.
Some of the inbuilt functions in the Wolfram Language when used together take up a lot of memory when used for a large dataset. When testing on a small set of papers (4-5) the code finished execution in a short time interval, but when tested on 1000 papers, the machine crashed. We had to profile the code, delete some code, and rewrite some of the variables. We ran each line of code took the absolute timing, tried to replace it with something more efficient, and running it on a Linux machine I was able to do it using 400Kb of memory instead of 4Gb.
Conclusion
This code can mostly be used for any other website, in fact, we referenced most of the code to the WSC19 project we had done, which was to find out the common word list for the Marathi language. An idea to extend this work would be using computer vision to generate the list using the reference figures in the papers. While importing the papers in PDF, some of the characters fail to import and some characters aren’t supported. So, instead of using PDF’s, I would like to import them in LaTeX.
I would like to thank Fez for all the help he gave me in completing my project.
If you want to check out the notebook, visit my GitHub repo.
If you want to check out the function, visit the WFR page


