Implementations
I find this to be a great discussion topic!
Of course, it is best to have a
Wolfram Function Repository (WFR) function that generates random datasets.
I implemented such function for WFR -- see
RandomTabularDataset.
Another, closely related WFR function is
ExampleDataset.
Remark: Note that I prefer the name RandomTabularDataset instead of RandomDataset. In Mathematica / WL datasets can be (deeply) hierarchical objects. Tabular datasets are simpler than the general WL datasets, but tabular data is very common, easier to explain and to reason with.
Motivations
My motivations are very similar to those of OP: rapid prototyping (of proof of concepts),
thorough testing of algorithms, making unit tests.
More specifically I want to:
Demonstration
The resource function
ExampleDataset
makes datasets from
ExampleData.
Here is an example dataset:
dsAW = ResourceFunction["ExampleDataset"][{"Statistics", "AnimalWeights"}]
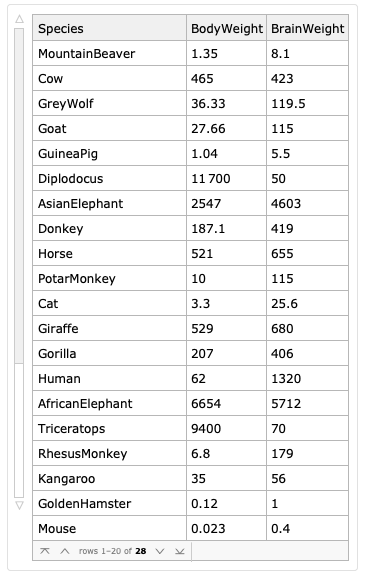
Here is a similar random dataset:
SeedRandom[23];
dsCW = ResourceFunction["RandomTabularDataset"][
{60, {"Creature", "BodyWeight", "BrainWeight"}},
"Generators" -> <|
1 -> (Table[StringJoin[RandomChoice[CharacterRange["a", "z"], 5]], #] &),
2 -> FindDistribution[Normal@dsAW[All, "BodyWeight"]],
3 -> FindDistribution[Normal@dsAW[All, "BrainWeight"]]|>];
IQB = Interval[Quartiles[N@Normal[dsAW[All, #BrainWeight/#BodyWeight &]]][[{1, 3}]]];
dsCW[Select[IntervalMemberQ[IQB, #BrainWeight/ #BodyWeight] &]]
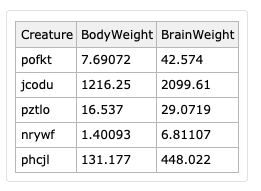
Remark: Instead of quartile boundaries filtering we can filter with
AnomalyDetection[Normal[dsAW[All, #BrainWeight/#BodyWeight &]]],
but the latter is prone to produce results that are "too far off."
Neat example
A random dataset with values produced by resource functions that generate random objects:
SeedRandom[3];
ResourceFunction[
"https://www.wolframcloud.com/obj/antononcube/DeployedResources/\
Function/RandomTabularDataset"][{5, {"Mondrian", "Mandala", "Haiku", "Scribble", "Maze", "Fortune"}},
"Generators" ->
<|
1 -> (ResourceFunction["RandomMondrian"][] &),
2 -> (ResourceFunction["RandomMandala"][] &),
3 -> (ResourceFunction["RandomEnglishHaiku"][] &),
4 -> (ResourceFunction["RandomScribble"][] &),
5 -> (ResourceFunction["RandomMaze"][12] &),
6 -> (ResourceFunction["RandomFortune"][] &)|>,
"PointwiseGeneration" -> True]



