Introduction
The previous post described an approach to perform ASCII art conversion. We used the mean intensity values to measure the distance, which ignored the underlying region structures. That is why a new system is required to recover the underlying region. It turns out that convolution is the right choice for extracting that kind of feature; that is why this approach is called the Convolution-based approach.
In general, convolution is a mathematical operation on two functions (f and g) that produces a third function (f*g) expressing how one's shape is modified by the other. In our case, these functions were represented by the matrix's(f - image matrix and g - convolution kernel).
Since the implementation of the ImageASCII is already in the Wolfram Function Repository and the source code is also available, we will skip the implementation details and look into the concept of the solution. The function can be accessed as ResourceObject[ImageASCII].
Approach
The character rasterization happens in the same way as the Intensity-based approach. So we will skip this part and will jump into the primary process.
When we convolve an image with a kernel, we will get a weight that shows how much the kernel modified the image's shape. As we do the same with both image and character rasters, we will compare these weights instead of the original image.
At first, we created custom matrices by hand to match the possible character shapes. However, experimentally, it turned out that known kernels from the VGG-16 neural network will lead to more accurate feature extraction. VGG-16 neural network consists of 64 independent kernels; we added an intensity kernel (kernel of all ones0 - basically to preserve the Intensity-based technique). As a result, we have 65 kernels in total.

The result of the convolution is a matrix, where each element is a tensor of 65 weights. After we convolve an image and character raster, we compare the computed weights and determine which character raster can represent a particular part of the image.
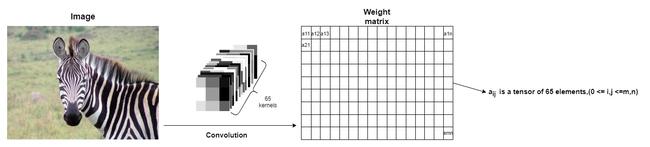
The main difference with the Intensity-based approach is that if we have a single weight in the Intensity-based approach, we now have 65 of them. Also, the Intensity-based approach will have identical results with the Convolution-based one with only intensity kernel. Technically, the Intensity-based is a general case of the Convolution-based.
Extracting features via convolution merely is using the ConvolutionLayer; where weights are the computed weights bases on the convolution kernels:
ConvolutionLayer[
Length[weights],
kernelSize,
"Stride" -> kernelSize,
PaddingSize -> 1,
"Weights" -> weights,
"Biases" -> None,
"Input" -> NetEncoder[{"Image", ImageDimensions[image], ColorSpace -> "Grayscale"}]
][image]
There is one issue regarding comparing the weights between the character rasters and the original image: they do not conform in the range of values. Normalizing the weights extracted from the characters concerning those extracted from the image allows overcoming the issue.
The normalization is a pretty straight-forward technique:
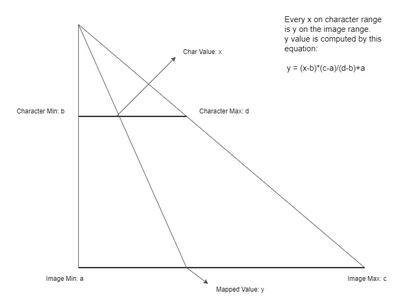
To ensure that the character ones cover the image weights' range, we need to remap the weights extracted from characters to the image range (where the start is the minimum weight and the maximum weight extracted from an image).
At this point, we have two groups of weights that are in the same range, and we can use Nearest to find the best match for replacing the image segment with a corresponding character. Nearest uses clusterization to find the nearest element from the list to x. This way, we will re-create an accurate ASCII representation of an input image as an Image object.
treeImage = Import["https://wolfr.am/SbiD9kgo"];
ResourceObject[ImageASCII][treeImage, "Image"]

Precisely, in the same way, we can reconstruct the ASCII representation in a string form. We also need to keep track of which raster corresponds to which character at the rasterization stage; hence, the computation will still happen at the character rasterization step, but we will choose the structure and make a copiable output at the assembly step.
ResourceObject[ImageASCII][treeImage, "Text"]

We might also need to preserve the character style information but lose the ability to copy the output to most editors.
ResourceObject[ImageASCII][treeImage, "Grid"]

As in most cases, ASCII art anticipated output is a string representation; that is why the default value is "Text".
ResourceObject[ImageASCII][treeImage]
Results
Below are a few results to demonstrate the function behavior:

font size 8 resulted in character raster to have {10, 15} dimensions, resizing the input image to match 500 in one dimension
Let us compare this approach to the Intensity-based approach to see how the results got improved visually:

font size 8 resulted in character raster to have {10, 15} dimensions, resizing the input image to match 500 in one dimension
As we can see, the edge recovery and image contrast are more accurate.
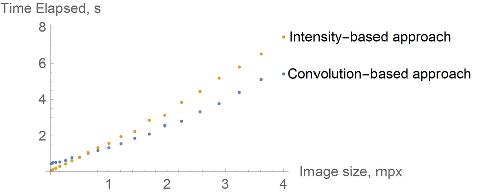
For time-complexity Comparison, a square image, which resolution was changing from 100 to 2000. Approaches used the same values for similar parameters (the time computation uses AbsoluteTiming). Also, the approaches import already rasterized characters, so only algorithm complexity is considered:
Conclusion
As we can see, the Intensity-based approach performs faster in lower resolutions and slower in higher ones. The Convolution-based approach's visual outcome is more accurate and appealing. Overall this approach is more accurate and useful to perform ASCII art.
References & Credits
Thanks to Wolfram Team and Mikayel Egibyan in particular for mentoring the internship.


