I will show how to build
The Oracle of Bacon in Wolfram Language (WL) using a small database of a few 100s actors. This can be easily generalized to many 1000s by a simple parameter change, but here we will keep it small so the graph theory objects can be visualized.
Six degrees of separation is a theory proposed by Frigyes Karinthy in 1929. It suggests that any 2 people in the world are are 6 or fewer acquaintance links apart. This idea found its analogy in a parlor game
Six Degrees of Kevin Bacon where film-knowledgable people compete to find shortest path between and arbitrary actor and revered Kevin Bacon. It assumes that any Hollywood actor can be linked to Kevin Bacon via at most 6 links - each linked formed when two actors participate in the same movie. Idea became very popular and lead to creation of a website called The Oracle of Bacon:
http://oracleofbacon.org where you can find the shortest movie path linking 2 actors and see other related information.
We will show that inside our database there is no longer chain than
FIVE. Most remote actors are "Audrey Tautou" and "Ray Romano". Below are typical results of our Oracle:
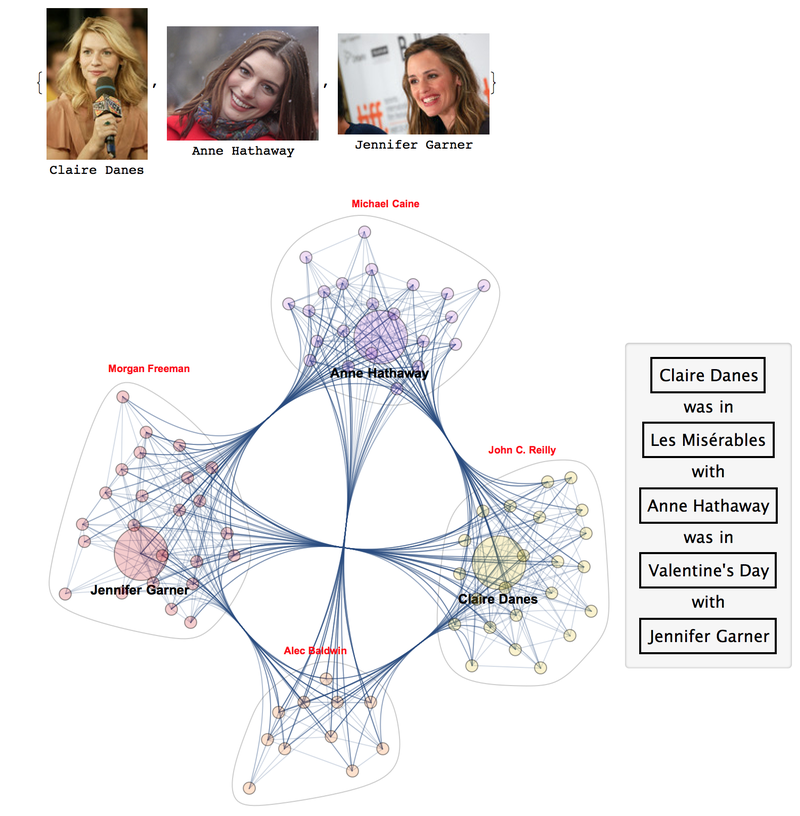
- Movie-path between given actors - here "Claire Danes" and "Jennifer Garner"
- Community nearest-neighbor sub-graph around the movie path
- Black names - linked actors
- Red names - enablers or hubs - actors who has most connections and around which communities are gathered in the subgraph of 2 given actors
So let's get to it - building the "The Oracle of Bacon". First we need to build a database of actors and movies they played in. There are many ways to do this - including using built-in WL data from Wolfram|Alpha - but lets make things more flexible - use external and internal data. We start from external data - scraping
Forbes magazine top-charts webpages for leading actors:
actor$RAW = ParallelMap[StringTake[#, {2, -2}] &, Union @@ ParallelMap[
Import["http://star-currency.forbes.com/celebrity-list/top-celebrities?page=" <> ToString[#], "Data"][[2, 2, All, 2]] &,
Range[0, 10]]];
Now let's use built-in data from Wolfram|Alpha and get the movies they played in:
acmo[a_] := WolframAlpha[a <> " moives", {{"Result", 1}, "ComputableData"}, PodStates -> {"Result__More", "Result__More"}]
movie$RAW = ParallelMap[acmo, actor$RAW]; // AbsoluteTiming
Out[]= {104.490424, Null}
Because of very large set some data will be missing - let's filter those out and build the database:
data = Association[Select[Thread[Rule[actor$RAW, movie$RAW]], #[[2]] =!= Missing["NotAvailable"] &]];
Now we can get all actors and see how many we have as:
In[26]:= actor = Keys[data];
% // Length
Out[]= 269
A typical database entry is
Normal[data][[23]]
Out[]= "Beyonce Knowles" -> {"Carmen: A Hip Hopera", "Austin Powers in Goldmember", "Fade to Black", "The Pink Panther", "Dreamgirls", "Cadillac Records", "Obsessed", "Epic", "Bettie Page Reveals All"}
Let's construct "adjacency matrix function" which will build a link between any 2 actors if they played in the same movie. And then we use it to compute adjacency matrix for all actors in database - excluding diagonal self-links. Then finally we build "adjacency graph" based on adjacency matrix.
amf[a_, b_] := If[Intersection[a[[2]], b[[2]]] == {}, 0, 1]
am = Outer[amf, Normal@data, Normal@data, 1] (1 - IdentityMatrix[Length[data]]);
ag = AdjacencyGraph[actor, am];
To check if an actor is in the database simply run
data["Claire Danes"]
Out[]= {"Little Women", "Home for the Holidays", "To Gillian on Her 37th Birthday", "Romeo + Juliet", "U Turn", "I Love You, I Love You Not", "The Rainmaker", "Les Misérables", "Polish Wedding", "The Mod Squad", "Brokedown Palace", "Mononoke-hime", "Igby Goes Down", "The Hours", "It's All About Love", "Terminator 3: Rise of the Machines", "Stage Beauty", "Shopgirl", "The Family Stone", "The Flock", "Me and Orson Welles", "Lemon"}
If an actor is not there you'll get
data["Santa Claus"]
Out[]= Missing["KeyAbsent", "Santa Claus"]
Pick any 2 actors in data base and find shortest path between them:
path = FindShortestPath[ag, "Claire Danes", "Jennifer Garner"]
Out[]= {"Claire Danes", "Anne Hathaway", "Jennifer Garner"}
Let's see how the path looks in "portrait" ;-)
Labeled[WolframAlpha[#, {{"Image:PeopleData", 1}, "Content"}], #] & /@ path

Let's find a nearest-neighbor subgraph along the path in our huge adjacency graph:
ng = NeighborhoodGraph[ag, path,
VertexLabels -> Thread[Rule[path, Placed[Style[#, 13, Bold], Below] & /@ path]],
VertexSize -> Thread[Rule[path, Table[{"Scaled", .07}, {Length[path]}]]],
VertexStyle -> Opacity[.2], EdgeStyle -> Opacity[.2],
BaseStyle -> EdgeForm[Opacity[.4]]];
HighlightGraph[ng, PathGraph[path]]
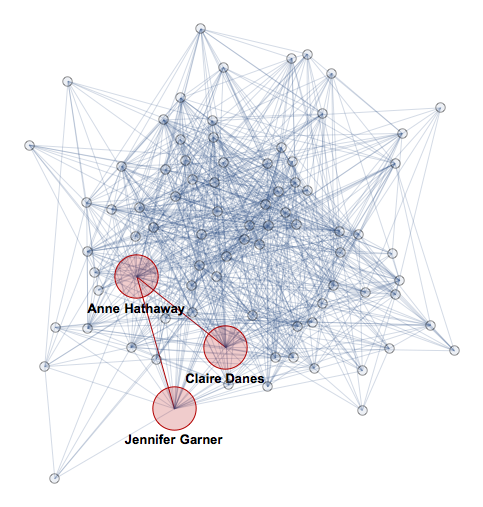
It has 83 vertices - basically 83 actors influencing this specific path:
VertexList[ng] // Length
Out[]= 83
This will list all actors along the path and group them in communities of most tightly related people according to graph measure called Modularity:
In[20]:= gp = FindGraphCommunities[ng]
Out[20]= {{"Jennifer Garner", "Jude Law", "Kate Beckinsale",
"Leonardo DiCaprio", "Matt Damon", "Robert Downey", "Andy Garcia",
"Ben Kingsley", "Jake Gyllenhaal", "Jamie Foxx", "Johnny Depp",
"Morgan Freeman", "Ben Affleck", "Christopher Walken",
"Colin Farrell", "Ellen Page", "Jason Bateman", "Jonah Hill",
"Jon Favreau", "Josh Hartnett", "Mark Ruffalo",
"Matthew McConaughey", "Michael Cera", "Michael Douglas",
"Tom Hanks"}, {"Claire Danes", "Billy Bob Thornton", "Diane Keaton",
"Jason Schwartzman", "Jennifer Lopez", "John C. Reilly",
"Josh Brolin", "Luke Wilson", "Meryl Streep", "Michelle Pfeiffer",
"Rachel McAdams", "Richard Gere", "Ryan Phillippe",
"Sarah Jessica Parker", "Sean Penn", "Steve Martin",
"Susan Sarandon", "Zac Efron", "Anna Faris", "Ashton Kutcher",
"Bill Murray", "Cate Blanchett", "Glenn Close",
"Salma Hayek"}, {"Anne Hathaway", "Christian Bale",
"Helena Bonham Carter", "Hugh Jackman", "Joaquin Phoenix",
"Julianne Moore", "Kirsten Dunst", "Nicole Kidman", "Russell Crowe",
"Sacha Baron Cohen", "Emily Blunt", "Gary Oldman", "James McAvoy",
"Jessica Biel", "Liam Neeson", "Mandy Moore", "Marion Cotillard",
"Michael Caine", "Patrick Dempsey", "Scarlett Johansson",
"Steve Carell", "Amy Adams", "Helen Mirren"}, {"Billy Crudup",
"Ed Harris", "Paul Rudd", "Jessica Alba", "Julia Roberts",
"Kate Hudson", "Topher Grace", "Alec Baldwin", "Elizabeth Banks",
"Ricky Gervais", "Tina Fey"}}
Let's visualize these communities. Red names that label communities are enablers or hubs - most influential connection-wise actors:
CommunityGraphPlot[ng, gp, CommunityLabels -> (Style[Sort[{#, VertexDegree[ag, #]} & /@ #, #1[[2]] > #2[[2]] &][[1, 1]], Red, Bold] & /@ gp)]
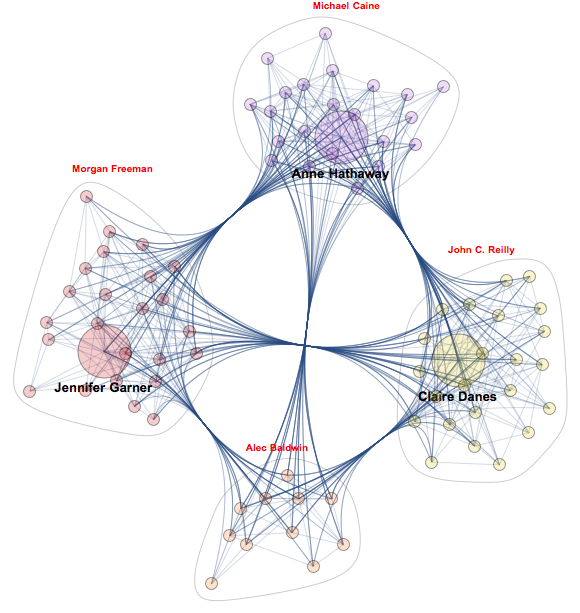
Let's do some text/string processing and format path-movie-actor chain in a readable form:
Panel@Column[Most[Flatten[DeleteDuplicates /@ Split[Flatten[{{Framed@#1, "was in"},
Framed@StringJoin@Riffle[Intersection[data[#1], data[#2]], " and "], "with",
{Framed@#2, "was in"}} & @@@ Partition[path, 2, 1],1]]]], Center] // Magnify

Finally we can ask a question what is the largest distance between any 2 actors in our database? Is it larger than 6 ? Turns out is is FIVE ! ;-)
fsp = FindShortestPath[ag];
asp = Outer[fsp, actor, actor];
Length /@ Flatten[asp, 1] // Union
Out[]= {1, 2, 3, 4, 5}
Who are they?
actor[[#]] & /@ Position[Map[Length, asp, {2}], 5]
Out[]= {{"Audrey Tautou", "Ray Romano"}, {"Ray Romano", "Audrey Tautou"}}
What is the path?
FindShortestPath[ag, "Audrey Tautou", "Ray Romano"]
Out[]= {"Audrey Tautou", "Ian McKellen", "Alec Baldwin", "Mark Wahlberg", "Ray Romano"}
This was fun ;-) I hoped enjoyed it. Feel free to experiment, suggest, optimize and comment!
 Attachments:
Attachments:


