Recently I found
this link very useful for python users if they are interestered in the integration of W|A into their python code. I can quickly explain what this code does and show some modification I have made so that you can interactively use Python as a plain text interface to get information from W|A.
Before you start, you can
register for a developer account on the Wolfram Product page. You may also apply for a free and non-commercial use API ID from the W|A developer portal. You will need this ID to access the database and its XML data structure.
Let me first show you how it looks when you run the modified script and after. The example is a "group of 8 " query about an international group
myMac: ~ shenghui$ ./WAPy.py 'group of 8'
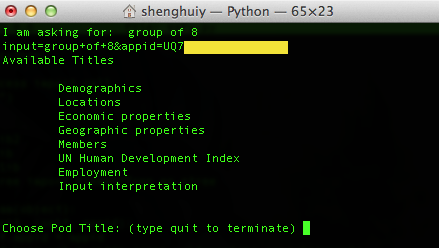
The application then prints the input query and its url encoded form, which just like that you will see in the url bar after you search for this answer in web W|A interface. It also prints out a list of titles related to the detailed information. They corresponds to the following pods from the outputs through web browser. For instance, the tabular result for Demographics is both available for web query and query via API.
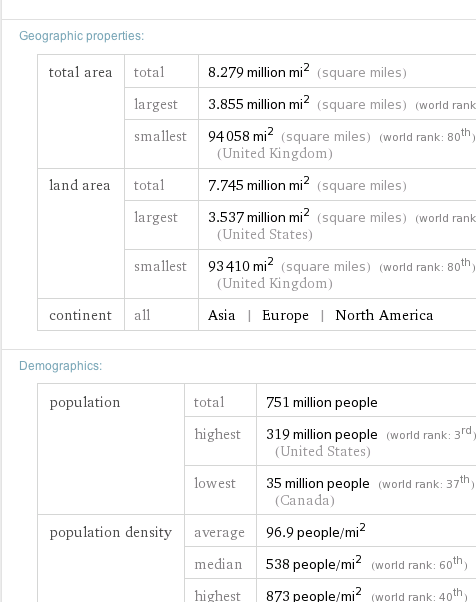
The prompt at the bottom is asking for a valid choice from the title list. If you want to check out the demographics info for the member coutries, just go ahead the type the exact match or paste it into the input prompt:
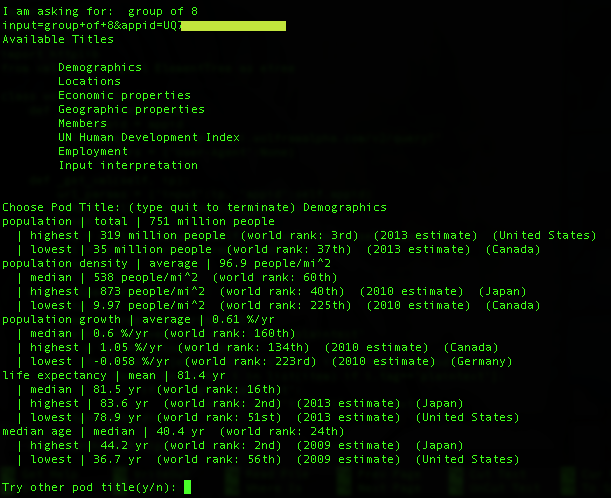
A nice feature is added here for searching the pod info again within the current XML session. Because there is a cap for non-commercial/personal developer API ID, I do not want to load the XML again from the server to waste my data cap. Therefore I added this "try again" prompt and I could reuse everything already on the local machine. Let's type y (yes) to get some new piece of data from the XML:
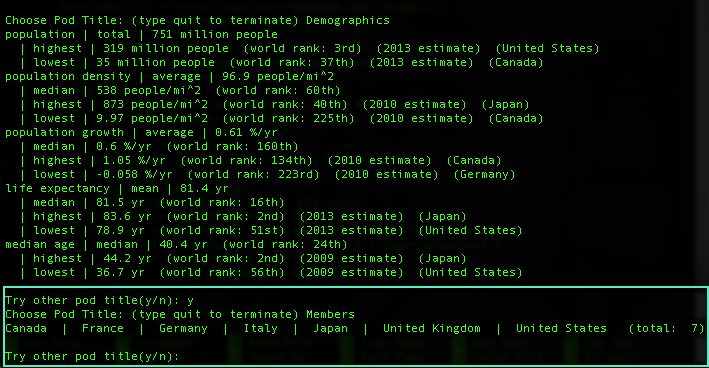
Until you hit "n" or any letter other than 'y', you can squeeze the XML to the last drop of data.
The python code is like the following:
preambles:
#!/usr/bin/python
from subprocess import call
call("clear")
import sys
import urllib2
import urllib
import httplib
from xml.etree import ElementTree as etree
The body is simply a method call for a wolfram object
appid = 'UQ7*********'
query = sys.argv[1]
print 'I am asking for: ', query
w = wolfram(appid)
w.search(query)
All heavy lifting goes into the definition of the object "wolfram". The constructor takes my API ID/appid as input
class wolfram(object):
def __init__(self, appid):
self.appid = appid
self.base_url = 'http://api.wolframalpha.com/v2/query?'
self.headers = {'User-Agent':None}
The get_xml method uses the urlencode function to turn my W|A input, aka first argument following executing WAPy.py file. After the call, it gets the XML data from the W|A server
def _get_xml(self, ip):
url_params = {'input':ip, 'appid':self.appid}
data = urllib.urlencode(url_params)
print data
req = urllib2.Request(self.base_url, data, self.headers)
xml = urllib2.urlopen(req).read()
return xml
The core of this python application is to extract the titles from the XML data
def _xmlparser(self, xml):
data_dics = {}
tree = etree.fromstring(xml)
#retrieving every tag with label 'plaintext'
for e in tree.findall('pod'):
for item in [ef for ef in list(e) if ef.tag=='subpod']:
for it in [i for i in list(item) if i.tag=='plaintext']:
if it.tag=='plaintext':
data_dics[e.get('title')] = it.text
return data_dics
If you are not too familiar with the code, that's fine. Basically it first create a python object < treeobj 0xpppppp> from the XML file and looking for proper tags. The following simply creates list from list e with some condition.
[ef for ef in list(e) if ef.tag=='subpod']
specifically the condition is that the the XML tag must be like <subpod> </subpod>.
Finally the human-readable data is stored in the data_dics. This is a special data structure in python called dictionary. Nothing fancy but just create a mapping like list. e.g.
a = ['name': 'wolfram research', 'product':"wolfram alpha"]
and
a['name']
returns 'wolfram research'. Notice that you cannot use integer index here for a.
The last part is about waiting for my input and print out the result under the chosen pod tile. This method calls two methods of wolfram object before to get "xml" and "result_dics".
def search(self, ip):
xml = self._get_xml(ip)
result_dics = self._xmlparser(xml)
print 'Available Titles', '\n'
titles = dict.keys(result_dics)
for ele in titles : print '\t' + ele
print '\n'
tryAgain = 'y'
while tryAgain == 'y':
s = raw_input('Choose Pod Title: (type quit to terminate) ')
if s == 'quit': quit()
while (s not in titles):
if s == 'quit': quit()
print 'Not Valid Title'
s = raw_input('Choose Pod Title Again: ')
print result_dics[s]
tryAgain = raw_input('\nTry other pod title(y/n): ')
print '\nTerminate the query'
To print out the pod titles after I have the dictionary object, I use the dict.keys method. Shortly, it does the following:
a = ['name': 'wolfram research', 'product':"wolfram alpha"]
dict.keys(a) ====> ['name', 'product']
The for loop exhausts the list of pod titles and prints them out.
for ele in titles : print '\t' + ele
The next While loop's purpose is to wait the user choose to quit the progam and the inner loop checks if the user has typeda valid pod title from the list of available pod titles.
Once you have the code saved to a .py file, use
chmod a+x myfile.py
to make it an executable.
Of course this is just a very simple application about the embedding W|A into python code, yet this shows a basic collection of essential elements one need to complete such a task. For a thorough manual about the XML structure, please go to
this site.


