Thank you so much for taking the time to help me, Jérôme.
All the audio signals in the dataset are 1.024s@16000kHz (i.e., 16384 samples in length):
In[]:= test = Import["C:\\folder\\example.wav"];
In[]:= Information[test]
Out[]:=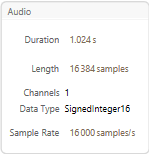
The reason my "c" is 2 is because those are the dimensions our given by the encoder:
In[]:= Dimensions[enc@test]
Out[]:= {256,256,2}
The 2 channels are the R & I parts:
...Block[
{data = ShortTimeFourier[#, window, offset, HannWindow]["Data"]
},
ArrayPad[
Transpose[
{
Re[data], Im[data]
}, {3, 1, 2}
], {{pad}, {0}, {0}}
]
], {"Varying", window, 2}
}...
If I even try to define my discriminator beginning from {256,256,1} using this encoder it throws this error:
NetChain::invspenc: NetEncoder[{"Function", \[Ellipsis]}] producing a n*256*2 array of real numbers, cannot be attached to port Input, which must be a 256*256*1 array.
Any ideas on how I could drop the I part & implement signal reconstruction from magnitude (e.g., Griffin-Lim, etc.) on the decoder end?
Passing the R & I parts BOTH through the net isn't the only thing that isn't in the paper. ArrayPad[]ing the {128, 256, 2} data to {256, 256, 2} in the encoder:
...ArrayPad[
Transpose[
{
Re[data], Im[data]
}, {3, 1, 2}
], {{pad}, {0}, {0}}
]...
also differs from the paper, & every implementation (e.g., MATLAB, Python, etc.) I've seen (i.e., because they somehow begin with {128,128,1} from 256winx128offset STFTs).
I can't figure out how a 256 window & a 128 offset can be cropped to 128x128 & still be reconstructed using the decoder/InverseShortTimeFourier[] (or w/o the passing the I parts through the net).
Here is the MATLAB example. I don't understand either language well enough to translate this into a Mathematica NetEncoder[], but I was able to underline where, firstly, it insures the training data is 128x128, & secondly it converts the data from {128,128,2} to {128,128,1}:
. . . . . . . 
It's definitely something with the encoder/decoder that's off right now (e.g., either {n,n,2} needs to be {n,n,1}, &or ArrayPad[] needs to be changed so it's 128x128 (& with 256win/128off/STFTs) rather than 256 x 256 (i.e., 128x256 padded to 256x256), that, &/or I'm still doing something doing wrong with the TransposeLayers[], but I tried your suggestion:
discriminator =
NetChain[
{
TransposeLayer[{2, 3, 1}]
...
},
"Input" -> enc
]
.
generator =
NetChain[
{
...
TransposeLayer[{3, 1, 2}]
},
"Input" -> 100,
"Output" -> dec
]
&, unfortunately, it didn't help with the results at all.
The net architecture/transpositions should be easy enough, though, if I can get the encoder/decoders working such that data is correctly input & output of the net.
Here is the discriminator architecture in some other languages, MATLAB:
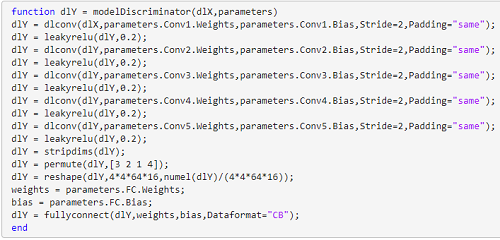
& Python:

& the generator architecture in MATLAB:
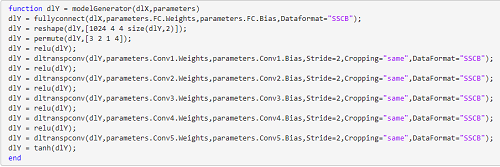
& Python
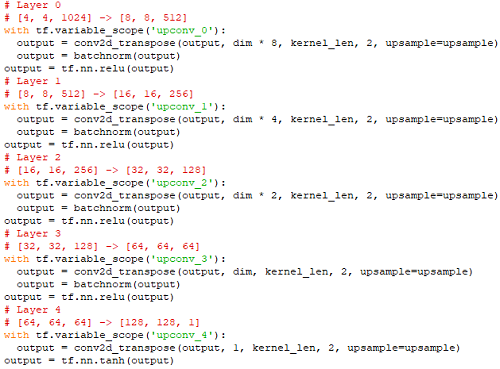
It's simple enough (indeed, the simplest) to achieve that in Mathemtica:
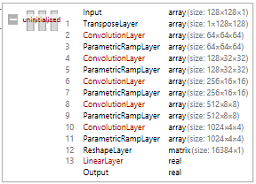
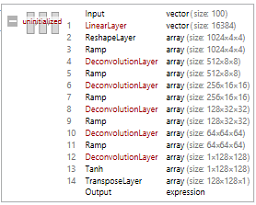
I just need to figure out this encoder/decoder problem.
Any tips would be much appreciated. Thank you!


