Thank you much, Jérôme, the code you provide above works perfectly.
Unfortunately, however, I'm still having problems with NetTrain[] using these encoders/decoders. Maybe you, or someone at Wolfram Research, could help me out?
I'm attempting adversarial audio synthesis (as described this paper & demonstrated in this MATLAB example) using Mathematica.
I define my STFT parameters:
window = 256;
offset = 128;
pad = (window - offset)/2;
samplerate = 16000;
I define my NetEncoder[] using the code you provide above. Notice, however, I also include/use ArrayPad[] so the output is square (i.e., {256, 256, 2} instead of {128, 256, 2} outputs):
enc = NetEncoder[
{"Function",
Function@
Block[
{data = ShortTimeFourier[#, window, offset, HannWindow]["Data"]
},
ArrayPad[
Transpose[
{
Re[data], Im[data]
}, {3, 1, 2}
], {{pad}, {0}, {0}}
]
], {"Varying", window, 2}
}
];
I define my NetDencoder[]. Notice, again, I also include/use ArrayPad[] so the encoder padding is removed (i.e., {128, 256, 2} instead of {256, 256, 2} outputs for the InverseShortTimeFourier[]):
dec = NetDecoder[
{"Function",
Function@
Block[
{re = ArrayPad[Normal[#[[All, All, 1]]], {{-pad}, {0}}],
im = ArrayPad[Normal[#[[All, All, 2]]], {{-pad}, {0}}]
},
Audio[
InverseShortTimeFourier[
re + I*im, window, offset, HannWindow
], SampleRate -> samplerate
]
]
}
];
The test you provide above still works perfectly even with my ArrayPad[] changes:
dec @ enc @ Audio[File["ExampleData/car.mp3"]]
I start running into problems, however, when I attempt to train a net with these encoders/decoders, so, e.g., I define my net parameters:
kern = {4, 4};
chan = 64;
α = 0.2;
I define my discriminator (Table 5 in [1]), adding an additional ConvolutionLayer[] for 256x256:
discriminator =
NetChain[
{
TransposeLayer[{3 <-> 1}, "Input" -> {256, 256, 2}],
ConvolutionLayer[chan, kern, "Stride" -> 2, PaddingSize -> 1],
ParametricRampLayer[{}, "Slope" -> α],
ConvolutionLayer[chan*2, kern, "Stride" -> 2, PaddingSize -> 1],
ParametricRampLayer[{}, "Slope" -> α],
ConvolutionLayer[chan*4, kern, "Stride" -> 2, PaddingSize -> 1],
ParametricRampLayer[{}, "Slope" -> α],
ConvolutionLayer[chan*8, kern, "Stride" -> 2, PaddingSize -> 1],
ParametricRampLayer[{}, "Slope" -> α],
ConvolutionLayer[chan*16, kern, "Stride" -> 2, PaddingSize -> 1],
ParametricRampLayer[{}, "Slope" -> α],
ConvolutionLayer[chan*32, kern, "Stride" -> 2, PaddingSize -> 1],
ParametricRampLayer[{}, "Slope" -> α],
LinearLayer[{}]
},
"Input" -> enc
]
out[]= ________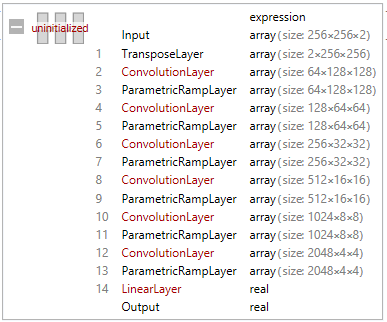
I define my generator (Table 4 in [1]), adding an additional DeconvolutionLayer[] for 256x256:
generator =
NetChain[
{
LinearLayer[chan*(window*2)],
ReshapeLayer[{2048, 4, 4}],
ElementwiseLayer["ReLU"],
DeconvolutionLayer[chan*16, kern, "Stride" -> 2, PaddingSize -> 1],
ElementwiseLayer["ReLU"],
DeconvolutionLayer[chan*8, kern, "Stride" -> 2, PaddingSize -> 1],
ElementwiseLayer["ReLU"],
DeconvolutionLayer[chan*4, kern, "Stride" -> 2, PaddingSize -> 1],
ElementwiseLayer["ReLU"],
DeconvolutionLayer[chan*2, kern, "Stride" -> 2, PaddingSize -> 1],
ElementwiseLayer["ReLU"],
DeconvolutionLayer[chan, kern, "Stride" -> 2, PaddingSize -> 1],
ElementwiseLayer["ReLU"],
DeconvolutionLayer[2, kern, "Stride" -> 2, PaddingSize -> 1],
ElementwiseLayer[Tanh],
TransposeLayer[{1 <-> 3}]
},
"Input" -> 100,
"Output" -> dec
]
out[]= _______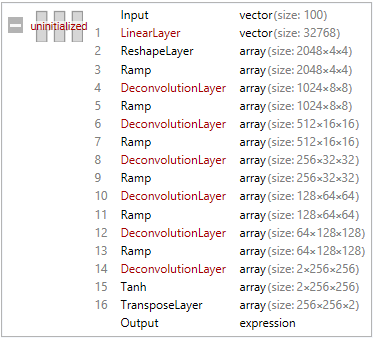
I load my training data (a dataset of wav files, each 16384 samples in length [i.e., 1.024s@16000KHz]):
wav = FileNames["*.wav", NotebookDirectory[]];
trainingData = Import[#] & /@ wav;
I define my "latent" input for training (following the documentation for NetGANOperator[]):
RandomLatent[batchSize_] :=
Map[NumericArray[#, "Real32"] &,
RandomVariate[NormalDistribution[], {batchSize, 100}]];
datagen =
Function[<|"Sample" -> RandomSample[trainingData, #BatchSize],
"Latent" -> RandomLatent[#BatchSize]|>];
I train the GAN:
gan = NetGANOperator[{generator, discriminator}];
trained = NetTrain[
gan,
{
datagen,
"RoundLength" -> Length[trainingData]
},
TrainingUpdateSchedule -> {"Discriminator", "Generator"},
Method -> {"ADAM", "Beta1" -> 0.5, "LearningRate" -> 0.0002},
BatchSize -> 64,
MaxTrainingRounds -> 100,
TargetDevice -> "GPU"]
However, when I generate new samples from the trained generator.:
trainedgen = NetExtract[trained, "Generator"];
trainedgen[RandomLatent[1]]
it's clear that something is wrong with my net architecture or my decoders/encoders or something because the generated samples don't resemble:
dec @ enc @ Audio[File["ExampleData/car.mp3"]]
they're either silent, or just noise, or etc. I can't figure it out.
I must be doing something wrong because I've used Mathematica's NetTrain[] on image datasets with similar architectures & I've never run into this problem (i.e., the generated samples always resemble the input).
Could it be I've set some parameter wrong?
Could it be the TransposeLayer[]s in my generator & discriminator are somehow making the data unusable?
Could it be the function (RandomLatent[]) I'm using for "latent" input for the generator is suitable only for image datasets & not for audio/STFT datasets?
Any help you, Jérôme, or anyone at Wolfram Research, could give me would be greatly appreciated. I'd really like to figure out how to NetTrain[] GANs with these encoders/decoders in Mathematica.
I've included an EXAMPLE notebook. Thank You.
 Attachments:
Attachments:


