Today I tried a code on the cloud for parsing html to structured data:
Clear[wikicat]
wikicat:=Module[{URLstr},
URLstr=URLFetch["http://en.wikipedia.org/wiki/Special:AllPages/Category:Ho"];
{URLstr//StringLength,ImportString[URLstr,"Data"]}
]
It works perfectly in the development Notebook environment of the cloud:
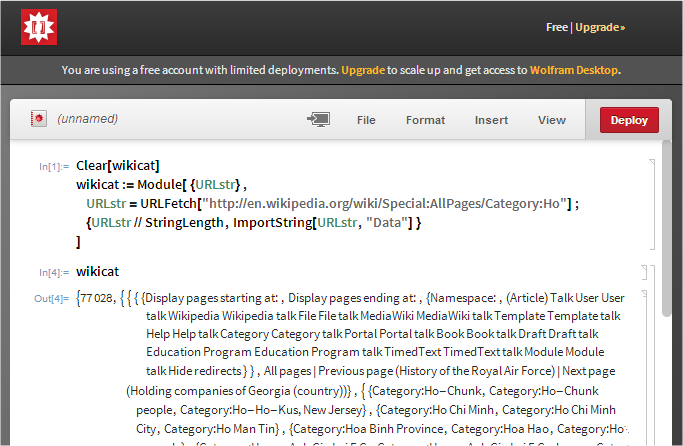
But when I tried to deploy it by
CloudDeploy[Delayed[wikicat,"String"]]
(* Out[3]= CloudObject[https://www.wolframcloud.com/objects/753a49c8-9fdc-4dbf-a7c1-359f918d68ef] *)
Visiting the corresponding URL gives

As it can be seen, URLFetch successfully got the HTML source string, which has 77028 characters. But somehow ImportString[URLstr,"Data"] failed.
My questions are:
Did I do something wrong?
I've tested that using string pattern match to extract the information is doable, but is there any work-around more elegant and/or compact?


