Hi everyone,
in one of the recent discussions I used the powerful Classify function of Mathematica 10 to try to make up for my lack of knowledge of fruits. It appears that the Classify function has quite some nice applications, particularly when combined with data scraped from the internet. I then remembered this beautiful Wolfram Blog article by Matthias Odisio about finding a good sequence of movies to watch. I believe that his approach is based on the covers/poster of the movies. I thought that now with Mathematica 10 we might try that again using a bit more information and very little (!) programming, Actually it will work in one line:
c = Classify[Table[Flatten[data[[k]]] -> ret[[k]], {k, 1, 150}]]
WARNING: If you evaluate the commands you are effectively downloading many websites automatically. Make sure that you do not violate the terms and conditions. Take this post as a description of the principle idea of how do to such things! If you run the code, check that you don't infringe any terms and conditions.
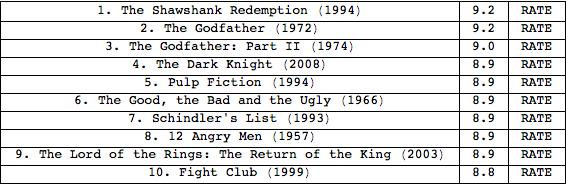
Let's start with getting some data. The IMDb has a nice website with a ranking of the 250 best films ever. Let's import the ranking:
ranking = Import["http://www.imdb.com/chart/top", "Data"][[4 ;; 253, 2]];
and list the top 10:
Grid[ranking[[1 ;; 10]], Frame -> All]
It is quite straight forward to get the hyperlinks to the movies like so:
links = Import["http://www.imdb.com/chart/top", "Hyperlinks"];
This command cleans that list up and only gives links to the films:
moviesite = DeleteDuplicates[Select[links, StringMatchQ[#, "http://www.imdb.com/title/" ~~ ___ ~~ "ref_=chttp_tt" ~~ ___] &]];
The results (well the first ten of them) look like this:

The next part needs a bit of work. We need to identify the important pieces of information on those websites. I am interested in: poster/cover image, title and year, director, lead actors, and short synopsis. The following slightly lengthly and clumsy code does the trick:
data = Monitor[
Reap[For[i = 1, i <= Length[moviesite], i++,
site = Import[moviesite[[i]], "Text"];
Sow[{Import[moviesite[[i]], "Images"][[4]],
StringDrop[
StringDrop[
StringSplit[
StringSplit[
StringSplit[site, " <meta name=\"title\" content="],
"<meta name=\"keywords\" content=\"Reviews, Showtimes, \
DVDs, Photos, Message Boards, User Ratings, Synopsis, Trailers, \
Credits\>"][[2]][[1]], "/\>"][[1 ;; 2]][[1]], -9], 1],
StringDrop[
StringDrop[
StringDrop[
StringSplit[
StringSplit[
StringSplit[site, " <meta name=\"title\" content="],
"<meta name=\"keywords\" content=\"Reviews, \
Showtimes, DVDs, Photos, Message Boards, User Ratings, Synopsis, \
Trailers, Credits\>"][[2]][[1]], "/\>"][[1 ;; 2]][[2]],
44], -Length[
Characters[
StringSplit[
StringDrop[
StringSplit[
StringSplit[
StringSplit[site,
" <meta name=\"title\" content="],
"<meta name=\"keywords\" content=\"Reviews, \
Showtimes, DVDs, Photos, Message Boards, User Ratings, Synopsis, \
Trailers, Credits\>"][[2]][[1]], "/\>"][[1 ;; 2]][[2]], 44],
"Directed by" ~~ ___ ~~ ". With"]][[1]]]], -6],
StringTake[
StringSplit[
StringDrop[
StringSplit[
StringSplit[
StringSplit[site, " <meta name=\"title\" content="],
"<meta name=\"keywords\" content=\"Reviews, \
Showtimes, DVDs, Photos, Message Boards, User Ratings, Synopsis, \
Trailers, Credits\>"][[2]][[1]], "/\>"][[1 ;; 2]][[2]], 44],
"Directed by" ~~ ___ ~~ ". With"],
Flatten[StringPosition[
StringSplit[
StringDrop[
StringSplit[
StringSplit[
StringSplit[site,
" <meta name=\"title\" content="],
"<meta name=\"keywords\" content=\"Reviews, \
Showtimes, DVDs, Photos, Message Boards, User Ratings, Synopsis, \
Trailers, Credits\>"][[2]][[1]], "/\>"][[1 ;; 2]][[2]], 44],
"Directed by" ~~ ___ ~~ ". With"], "."]][[1]]],
StringDrop[
StringDrop[
StringSplit[
StringDrop[
StringSplit[
StringSplit[
StringSplit[site, " <meta name=\"title\" content="],
"<meta name=\"keywords\" content=\"Reviews, \
Showtimes, DVDs, Photos, Message Boards, User Ratings, Synopsis, \
Trailers, Credits\>"][[2]][[1]], "/\>"][[1 ;; 2]][[2]], 44],
"Directed by" ~~ ___ ~~ ". With"],
Flatten[StringPosition[
StringSplit[
StringDrop[
StringSplit[
StringSplit[
StringSplit[site,
" <meta name=\"title\" content="],
"<meta name=\"keywords\" content=\"Reviews, \
Showtimes, DVDs, Photos, Message Boards, User Ratings, Synopsis, \
Trailers, Credits\>"][[2]][[1]], "/\>"][[1 ;; 2]][[2]], 44],
"Directed by" ~~ ___ ~~ ". With"], "."]][[1]]], -1]
}]]][[2, 1]], i]
A typical entry looks like this:

Downloading all info can take 30-40 minutes. Ok. Now comes a little bit of work. I have programmed a little (clumsy) interface where I can rate the first 150 movies - the training set.
ret = {};
For[i = 1, i <= 150, i++, ret = AppendTo[ret, ChoiceDialog[{ImageResize[data[[i, 1]], 100], data[[i, 2]], data[[i, 3]], data[[i, 4]], data[[i, 5]]} //
TableForm, {"bad" -> "bad", "good" -> "good"}, WindowSize -> Large]]]
It is primitive, and I would be more than happy if people want to improve it. The interface looks like this:
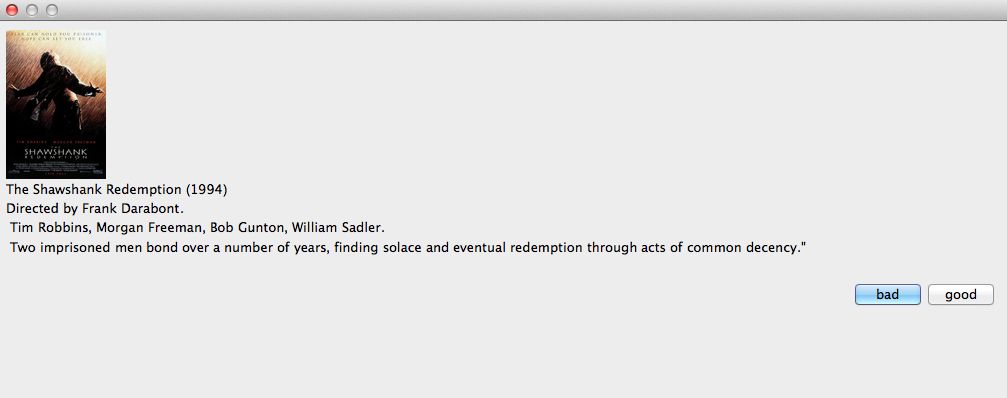
It shows all relevant information though very badly formatted. The good/bad rating is saved in the variable ret. We can finally train our Classify function
c = Classify[Table[Flatten[data[[k]]] -> ret[[k]], {k, 1, 150}]]
It uses NearestNeighbors, and seems to work just fine. We can now see what classify thinks I like or dislike.
RandomChoice[Table[{data[[k, 1]], data[[k, 2]], c[Flatten[data[[k]]], "Probabilities"]}, {k, 151, 250}], 1] // TableForm
which gives:

So I apparently do like Jaws more than I dislike it. Interesting. Of course, if you have the data you can now check large numbers of films at the click of a button:
Table[{data[[k, 1]], data[[k, 2]], c[Flatten[data[[k]]], "Probabilities"]}, {k, 151, 250}] // TableForm
It is easy to train the system better if you have better data on what you like or dislike. Obviously, Netflix and Amazon will use similar things to advertise something you might like to you. The amazing thing for me is that, once you have the database, all that can be done with one line of code:
c = Classify[Table[Flatten[data[[k]]] -> ret[[k]], {k, 1, 150}]]
I will attach a notebook with all commands.
Disclaimer: I do not know whether you breach the Terms and Conditions of IMDb. You run this command on your own risk.
Hope you enjoy the results and the power of Classify[],
Marco
 Attachments:
Attachments:


