Hi everyone,
quite regularly, one finds postings in non-English Languages in this community. Often there are dozens of them that clog up the first pages of this community. It loos like this:
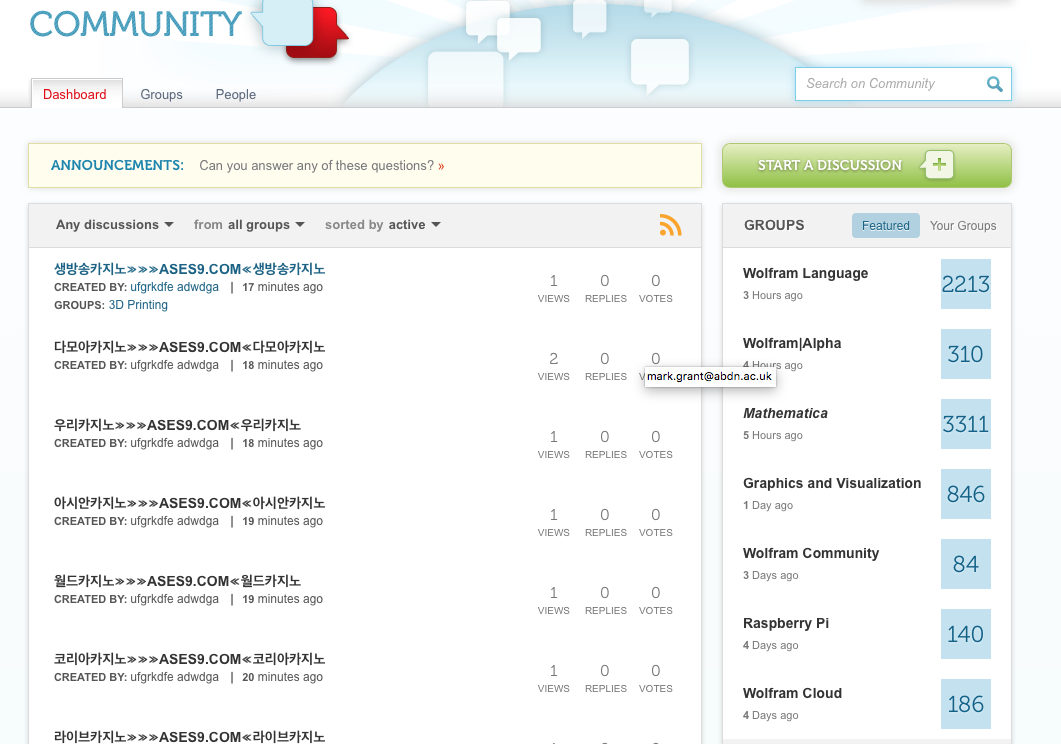
It would be kind of cool if these postings were filtered out, by the system. This is quite straight forward with the Wolfram language. This is a very simple approach (when you run this, the moderation team might have removed the Korean post, so this might not work anymore):
Classify["Language", #] & @ StringSplit[StringSplit[Import["http://community.wolfram.com/groups/-/m/t/575914", "Plaintext"], "GROUPS"][[2]], "POSTED BY: "][[1]]
which gives:

and
Classify["Language", #] & @StringSplit[StringSplit[Import["http://community.wolfram.com/groups/-/m/t/575366", "Plaintext"], "GROUPS"][[2]], "POSTED BY: "][[1]]
which gives
Of course, it is quite straight forward to train a neuronal network just for this. Interestingly,
Classify["Spam", #]
does not appear to work; probably it is trained on English spam. The community also has an RSS feed, so it is quite easy to use Mathematica to check every couple of minutes where one of these spam attacks is taking place.
Cheers,
Marco


