While most humor has continually eluded the grasp of computers, some jokes can be reduced to simple linguistic formula. I focus on two in this post:
Joke Type 1: The Comparison
I like my <noun 1> like I like my <noun 2>: <adjective or other word that can describe both nouns>
Example:
I like my immunity like I like my resistance: passive.
The Comparison is probably the easier of the two jokes to generate. In other languages it would be difficult even with a dictionary dataset, but we can take advantage of a sometimes-annoying feature of the Wolfram Language: the fact that WordData contains compound nouns, nouns with two or more component words.
First we define a subset of WordData[], all compound words with exactly two component words:
twoword = Select[WordData[], Length[StringSplit[#]] == 2 &]

Then we group all of the compound words by the first component word, and delete any groups with only one element. We then truncate each group to two elements only. This discards some possible jokes, but it makes the list more manageable.
pairs = Values[
Select[GroupBy[twoword, StringSplit[#][[1]] &],
Length[#] > 1 &]][[All, ;; 2]]

If you wanted to create all possible pairs, you could find all the 2-subsets of each group: Subsets[#,{2}] &/@ groups
Next we define a StringTemplate for this joke formula to make generation easier:
comparisontemp =
StringTemplate["I like my `1` like I like my `2`: `3`."];
Now the fun part! We choose a random sample of 5 word groups, and apply the string template to each:
comparisontemp[StringSplit[#[[1]]][[2]], StringSplit[#[[2]]][[2]],
StringSplit[#[[1]]][[1]]] & /@ RandomSample[pairs, 5]
All those StringSplits are there just to get the component words for insertion into the StringTemplate.
This gives us something like:
{"I like my Ashe like I like my Compton: Arthur.",
"I like my method like I like my section: rhythm.",
"I like my lithography like I like my printing: offset.",
"I like my californica like I like my cinerea: Juglans.",
"I like my cynthia like I like my walkeri: Samia."}
Most of the jokes this method generates are nonsensical or not funny like those above, but occasionally one elicits a small chuckle. Here are a couple of my favorites:
- I like my curve like I like my decay: exponential.
- I like my bathing like I like my blocker: sun.
- I like my bag like I like my benefit: sick.
- I like my dew like I like my double: daily.
Joke Type 2: The Rhyme
What do you call a <noun or adjective 1> <noun or adjective 2>? A(n) <synonym for noun/adjective 1 that rhymes with synonym 2> <synonym for noun/adjective 2 that rhymes with synonym 1>.
Example:
What do you call a ramshackle conservative? A broken-down button-down.
The Rhyme is a fair bit more complicated to create, but it usually yields much funnier jokes than The Comparison, plus it has the advantage that you can generate a big list of jokes at once.
NOTE: While the two joke types shouldn't have overlapping symbol namespaces, just to be on the safe side you should quit the kernel with Quit[] before starting this section of the code.
We start out by defining the number of syllables that have to match at the end of two words for those words to rhyme. You can set this to anything, but I've found that a value of 2 generally produces the highest-quality results. Bear in mind that a higher value will produce less jokes.
syllables = 2;
Then we define a StringTemplate for this joke formula to make generation easier:
rhymetemp = StringTemplate["What do you call a `1` `2`? A `3` `4`."];
Next we making a big list of nouns and adjectives that WordData has hyphenation and synonym data for.
words = Flatten[
Table[# -> {WordData[#, "Hyphenation"],
Flatten[WordData[#, "Synonyms"][[All, 2]]]} & /@
WordData[All, part], {part, {"Noun", "Adjective"}}]]
This list is a bunch of rules in this form:
"word"->{{"syllables","in","word"},{"synonyms","for","word"}}
Now we select only the words in the list that have no space, have at least one synonym, have hyphenation (syllable) data, and have at least syllables syllables:
filteredwords =
Select[words,
Length[StringSplit[#[[1]], " "]] == 1 && Length[#[[2, 2]]] > 0 &&
Length[#[[2, 1]]] >= syllables && ! MissingQ[#[[2, 1]]] &];
Next we group filteredwords by the last syllables syllables of each word, so all the words in each group rhyme:
rhymes =
Select[GroupBy[filteredwords,
StringJoin @@ #[[2, 1, -syllables ;;]] &], Length[#] > 1 &]
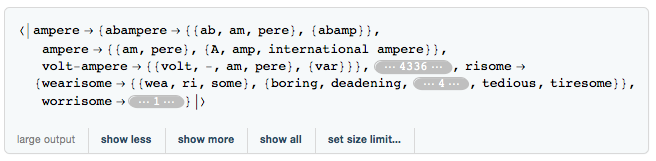
The next part creates a list of four-word lists that contain the words applied to the joke formula. It uses a large piece of code, but it's mostly just a bunch of tests in a Select statement ensuring that all four words are unique and that no two words are too similar.
Short[jokequarts =
Select[Table[{RandomChoice[suffix[[1, 2, 2]]],
RandomChoice[suffix[[2, 2, 2]]], suffix[[1, 1]],
suffix[[2, 1]]}, {suffix, rhymes}], (#[[1]] != #[[2]])
&&
(#[[3]] != #[[4]])
&&
Quiet[StringTake[#[[1]], -3] != StringTake[#[[2]], -3]]
&&
(Quiet[StringTake[#[[1]], 3] != StringTake[#[[3]], 3]] &&
Quiet[StringTake[#[[2]], 3] != StringTake[#[[4]], 3]])
&&
(Length[StringPosition[#[[3]], #[[4]]]] == 0 &&
Length[StringPosition[#[[4]], #[[3]]]] == 0) &]]
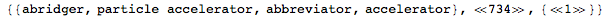
Like The Comparison, we're only generating one joke for each suffix to keep the list size down, but you could again use Subsets to extend the "joke space" to all possible jokes.
Now we apply rhymetemp to all of the four-word lists:
jokestrings = rhymetemp @@@ jokequarts;
And we're done! Evaluate this line repeatedly to generate as many jokes as you want:
Style[RandomChoice[jokestrings], "Subtitle"]
This method still creates many bad jokes, but a surprising amount are pretty good:
- What do you call a mediate intermediary? A in-between go-between.
- What do you call a lucid disciple? A coherent adherent.
- What do you call a topsy-turvy senior? A disorderly elderly.
- What do you call a ophthalmologist democrat? A oculist populist.
This code still has its fair share of problems. For example, the second sentence always starts with "A", even if the next word starts with a vowel sound (although this should be pretty easy to fix.) Also, the conditional tests could probably be improved to weed out "jokes" like this:
What do you call a Eastern Roman Empire Byzantium? A Byzantine Empire Eastern Roman Empire.
However, it's still quite impressive that my computer can make me laugh given only a dictionary and a formula!
Can you improve this code? Did it produce a particularly good joke for you? Leave a response below!


