Summarization of data
Some time ago I programmed a function, RecordsSummary, inspired by R's summary. Here is an example of its usage: Census data summary .
As the name implies, it is assumed that we have a list of records, all with the same length, and we want the columns to be summarized. (Each record is a row.)
You can get the package MathematicaForPredictionUtilities.m from MathematicaForPrediction at GitHub or simply run this command:
Import["https://raw.githubusercontent.com/antononcube/MathematicaForPrediction/master/MathematicaForPredictionUtilities.m"]
Let us create random data.
data = RandomInteger[{0, 100}, 100];
dataCat = RandomChoice[Characters["azbuka"], 100];
data2 = RandomInteger[{0, 100}, {100, 4}];
Here are examples of using RecordsSummary over the created data.
1. Call on a 1D array:
RecordsSummary[ data ]
2. Summary of a 2D numeric array. The columns are named automatically.
RecordsSummary[N[data2]]

3. Fancy output of numerical and categorical data summary. The column names are the second argument given to RecordsSummary.
Grid[{RecordsSummary[
Transpose[{N[data], dataCat}], {"Numeric", "Categorical"}]},
Alignment -> Top, Dividers -> All]

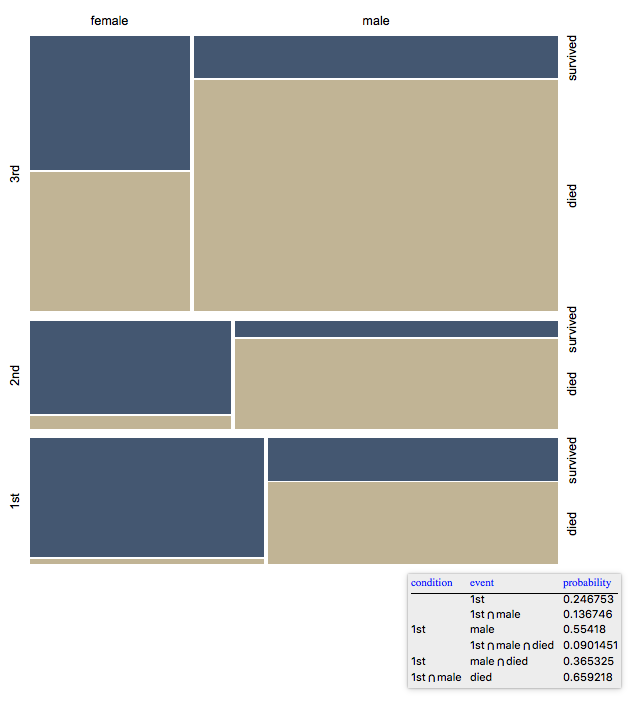
Mosaic plots
Using Mosaic plots for data exploration/visualization was described in these WordPress blog posts and this Community discussion.
Here is an example:
Import["https://raw.githubusercontent.com/antononcube/MathematicaForPrediction/master/MosaicPlot.m"]
titanicDataset = Map[Flatten, List @@@ ExampleData[{"MachineLearning", "Titanic"}, "Data"]];
Dimensions[titanicDataset]
(* {1309, 4} *)
titanicVarNames = Flatten[List @@ ExampleData[{"MachineLearning", "Titanic"}, "VariableDescriptions"]]
(* {"passenger class", "passenger age", "passenger sex", "passenger survival"} *)
MosaicPlot[titanicDataset[[All, {1, 3, 4}]], ColorRules -> {3 -> ColorData[7, "ColorList"]}]