I recently came across a video that intended to show how neural networks interpret images of (not so beautiful) things if they have only been trained on beautiful things. It is quite a nice question, I think. Here is a website describing the technique, and here is a video that illustrates the idea. In this post I will show you, how to generate similar effects easily with the Wolfram Language:

and in video format:
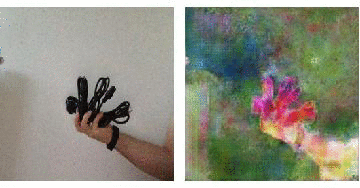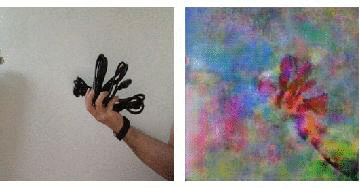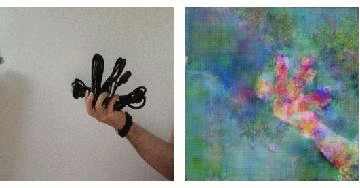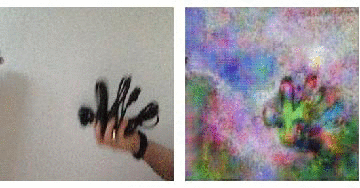
On the right you see the "interpretation" of a neural network that has been shown lots of photos of flowers, when it actually looks at a rubbish dump with a couple of birds sitting on the rubbish.
Devising a plan
We will need a training dataset and should hope to find a network in the Wolfram Neural Net Repository that more or less does what we want to do. If you have watched some of the excellent training videos on neural nets offered by Wolfram you will have noticed that the general suggestion is not to develop your own neural networks from scratch, but rather use what is already there and perhaps combine it, or adapt it so that you can achieve what you want. This is also very well described in this recent blog-post by experts on the topic. I am usually happy if I can use the work of others and do not have to re-invent the wheel.
If you read the posts describing how to build a network that have only seen beautiful things, you will find that they used a variation of the pix2pix network and an implementation in tensorflow (a "conditional adversarial network"). If you go through the extensive list of networks that are offered on the Wolfram Neural Net Repository you will see that there are Pix2pix resources, e.g.
ResourceObject["Pix2pix Photo-To-Street-Map Translation"]
or
net=ResourceObject["Pix2pix Street-Map-To-Photo Translation"]
I will use the latter resource object, but that does not actually matter. Next, we will need to build a training set.
Scraping data for the training set
The next thing we need is a solid training set. My first attempt was to use ServiceConnect with the google search to obtain lots of images of flowers.
googleCS = ServiceConnect["GoogleCustomSearch"]
imgs = ServiceExecute["GoogleCustomSearch",
"Search", {"Query" -> "Flowers", MaxItems -> 1000,
"SearchType" -> "Image"}];
It turns out that the max of results returned is only 100, which is not enough for our purpose. I tried to fix this by using
imgs2 = ServiceExecute["GoogleCustomSearch",
"Search", {"Query" -> "Flowers", MaxItems -> 1000,
"StartIndex" -> 101, "SearchType" -> "Image"}];
but that did not work. So WebImageSearch is the way to go. It does cost ServiceCredits, but the costs are relatively limited. Let's download information on 1000 images of flowers:
imgswebsearch = WebImageSearch["Flowers", MaxItems -> 1000];
Export["~/Desktop/imglinks.mx", imgswebsearch]
A WebImageSearch of up to 10 results costs 3 ServiceCredits. So this should be 300 credits. 500 credits can be bought for $3, and 5000 for $25 (+VAT). This would mean the generation of our training set comes in at maximally $1.8, which is manageable - particularly if we consider the price of the eGPU that we will use later on.... Just in case we export the result, because we paid for it and might have to recover it later if we suffer a kernel crash or something.
Alright. Now we have a dataset that looks more or less like this:
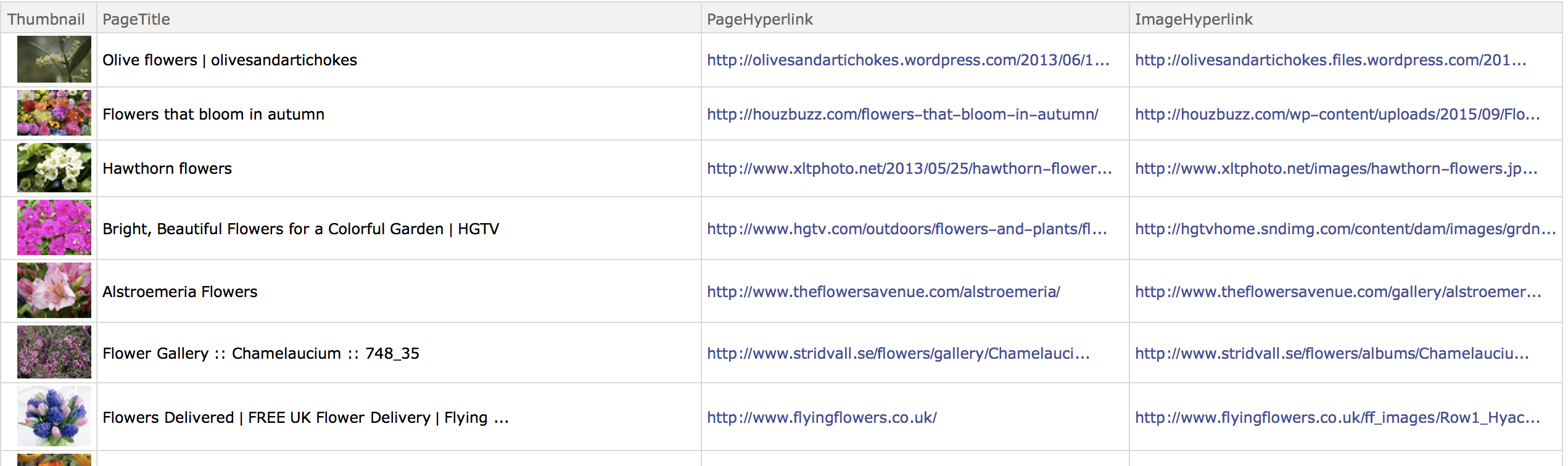
Great. That contains the "ImageHyperlink" which we will now use to download all the images:
rawimgs = Import /@ ("ImageHyperlink" /. Normal[imgswebsearch]);
Export["~/Desktop/rawimgs.mx", rawimgs]
Again, we export the result (better safe than sorry!). Let's make the images conform:
imagesconform = ConformImages[Select[rawimgs, ImageQ]];
By using Select[...,ImageQ] we make sure that we use only images; and not error messages of the cases where it didn't work.
Generating a training set
In the original posts they suggest that they used edges, i.e. EdgeDetect to generate partial information of the images, and then linked that to the full image like so:
rules = ImageAdjust[EdgeDetect[ImageAdjust[#]]] -> # & /@ imagesconform;
It turns out that my results with that were less than impressive so I went for a more time consuming approach that gave better results. I used
Monitor[rulesnew = Table[Colorize[ClusteringComponents[rules[[i, 2]], 7]] -> rules[[i, 2]], {i, 1, Length[rules]}];, I]
i.e. ClusteringComponents to generate a trainingset. Partial information on the images now looked like this:

rather than
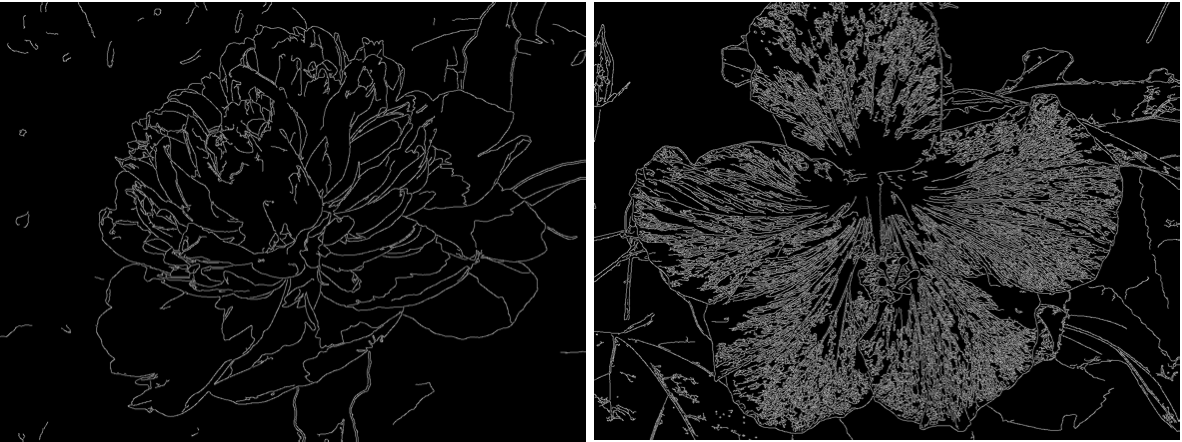
when we use EdgeDetect. Our training data set now links the image with partial (CluseteringComponents) information via a rule to the original image. Basically, we give partial information of the world and train the network to see flowers. Just in case we export the data set like so:
Export["~/Desktop/rulesnew.mx", rulesnew]
Training the network
If you want to train on the EdgeDetect version you can use:
retrainednet = NetTrain[net, rules, TargetDevice -> "GPU", TrainingProgressReporting -> "Panel", TimeGoal -> Quantity[120, "Minutes"]]
otherwise you can use
retrainednet2 = NetTrain[net, rulesnew, TargetDevice -> "GPU", TrainingProgressReporting -> "Panel", TimeGoal -> Quantity[120, "Minutes"]]
Note that I use a GPU and considerable training time (2h). On a CPU this would take quite a while. Here are typical results of the EdgeDetect network:
retrainednet[EdgeDetect[CurrentImage[], 0.7]]
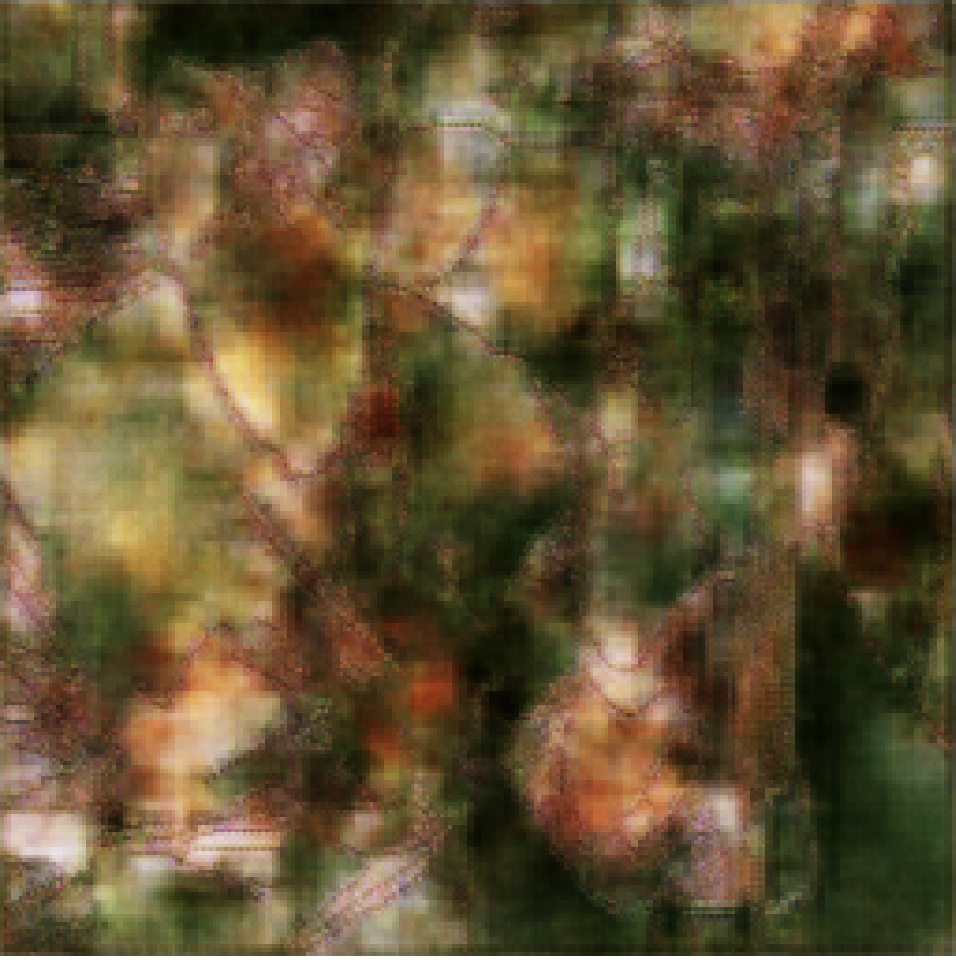
and the ClusteringComponents one:

We should not forget to export the network:
Export["~/Desktop/teachnwnicethings2.wlnet", retrainednet2]
More examples
Let's look at the ClusteringComponents network a bit closer. We apply
GraphicsRow[{ImageResize[#, {256, 256}], beautifulnet[Colorize[ClusteringComponents[#, 7]]]}] &
to different images to obtain:

Application to videos
Suppose that I have the frames of a recorded movie stored in the variable movie1. Then load our network into the function beautifulnet
beautifulnet = Import["/Users/thiel/Desktop/teachnwnicethings2.wlnet"]
Then the following will generate frames for an animation:
animation1 = GraphicsRow[{ImageResize[#, {256, 256}], beautifulnet[Colorize[ClusteringComponents[#, 7]]]}] & /@ movie1;
We can animate this like so:
ListAnimate[animation1]
Conclusion
These are only very preliminary results. But we see the workflow from scraping data, via generating a training set, choosing a network and training it. I think that having more images and more training, perhaps a small change of the net might give us much better results. The video is quite bad, because we should use a better object than "four cables in a hand". It is also a bit debatable whether it is ok to say that this is how a network that only has seen beautiful things interprets the world, but I couldn't resit the hype. Sorry for that!
This is certainly in the realm of "recreational use of the Wolfram Language", but the network does appear to make the world more colourful and provides a very special interpretation of the world. I hope that people in this forum who are better than me at this (@Sebastian Bodenstein , @Matteo Salvarezza , @Meghan Rieu-Werden , @Vitaliy Kaurov ?) can improve on the results.
Cheers,
Marco


