Today (21st of February) is UNESCO International Mother Language Day and I decided to celebrate it by exploring a bit LanguageData function.
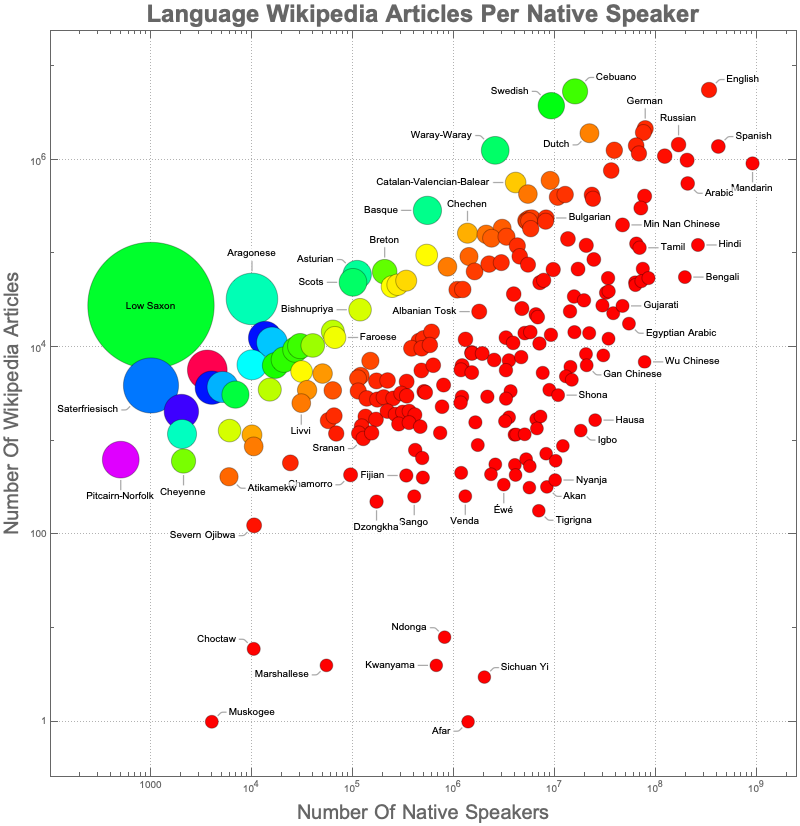
In particular, I will show how to create the top BubbleChart using two properties of LanguageData: "NativePopulation" and "WikipediaArticleCount". The goal behind using these properties is to explore the "fitness" of languages by measuring the ratio "number of wikipedia articles"/"number native speakers" which will be represented by the size and color of the bubbles.
This way I can easily illustrate how well-protected languages have a bigger internet presence (wikipedia articles counts per native speaker). And languages from poor countries like Tigrigna from Ethiopia and Eritrea (Africa) are underrepresented in wikipedia. Interestingly languages from small European countries like Sweden, Netherlands, Scotland, Catalonia, Basque Country,
are among the highest in terms of wikipedia activity.
For this purpose, I preselected languages that have at least some native speakers alive and some wikipedia articles. Here there is a list of such languages (Disclaimer: some languages fulfilling such conditions might be missing):
languages = {"Abkhaz", "Aceh", "Adyghe", "Afar", "Afrikaans", "Akan",
"AlbanianTosk", "Amharic", "Arabic", "ArabicEgyptianSpoken",
"Aragonese", "Armenian", "Assamese", "Asturian", "Atikamekw",
"Avar", "AzerbaijaniSouth", "Bamanankan", "Banjar", "Bashkir",
"Basque", "Bavarian", "Belarusan", "Beng", "Bengali",
"BicolanoCentral", "Bishnupriya", "Bislama", "Bosnian", "Breton",
"Bugis", "Bulgarian", "BuriatChina", "BuriatRussia", "Burmese",
"BwamuCwi", "CatalanValencianBalear", "Cebuano", "Chamorro",
"Chavacano", "Chechen", "Cherokee", "Cheyenne", "ChineseGan",
"ChineseHakka", "ChineseMandarin", "ChineseMinDong",
"ChineseMinNan", "ChineseWu", "ChineseYue", "Choctaw", "Chuvash",
"Corsican", "CrimeanTurkish", "Croatian", "Czech", "Danish",
"Dimli", "Dutch", "Dzongkha", "English", "Erzya", "Ewe",
"Extremaduran", "Faroese", "FarsiEastern", "Fijian", "Finnish",
"FrancoProvencal", "French", "FrisianEastern", "FrisianNorthern",
"Friulian", "Gagauz", "Galician", "Ganda", "Georgian", "German",
"GermanPennsylvania", "Gikuyu", "Gilaki", "Greek", "Gujarati",
"HaitianCreoleFrench", "Hausa", "Hawaiian", "Hebrew", "Hindi",
"HindustaniFijian", "Hungarian", "Icelandic", "Igbo", "Ilocano",
"Indonesian", "InuktitutGreenlandic", "IrishGaelic", "Italian",
"JamaicanCreoleEnglish", "Japanese", "Javanese", "Kabardian",
"Kabiye", "KalmykOirat", "Kannada", "KarachayBalkar", "Karakalpak",
"Kashmiri", "Kashubian", "Kazakh", "KhmerCentral", "Kirghiz",
"Kolsch", "KomiPermyak", "KonkaniGoanese", "Koongo", "Korean",
"KurdishCentral", "Kwanyama", "Ladino", "Lak", "Lao", "Lezgi",
"Ligurian", "Limburgisch", "Lingala", "Lithuanian", "Livvi",
"Lombard", "LuriNorthern", "Luxembourgeois", "Macedonian",
"Maithili", "Malayalam", "Maldivian", "Maltese", "Maori", "Marathi",
"MariEastern", "MariWestern", "Marshallese", "Mazanderani",
"Minangkabau", "Mingrelian", "MirandaDoDouro", "Moksha", "Muskogee",
"NahuatlCentral", "NapoletanoCalabrese", "Narom", "Nauruan",
"Navajo", "Ndonga", "Newar", "Nyanja", "OjibwaSevern", "Osetin",
"Pampangan", "Pangasinan", "PanjabiEastern", "PanjabiWestern",
"Papiamentu", "PashtoCentral", "Piemontese", "PitcairnNorfolk",
"Polish", "Pontic", "Portuguese", "Ravula", "Romanian",
"RomanianMacedo", "RomaniVlax", "Romansch", "Rundi", "Russian",
"Rusyn", "Rwanda", "SaamiNorth", "SaintLucianCreoleFrench",
"Samoan", "Sango", "Sanskrit", "Saterfriesisch", "SaxonLow",
"Schwyzerdutsch", "Scots", "ScottishGaelic", "Serbian", "Shona",
"Sicilian", "Sindhi", "Sinhala", "Slovak", "Slovenian", "Somali",
"SorbianLower", "SorbianUpper", "SothoNorthern", "SothoSouthern",
"Spanish", "Sranan", "Sunda", "Swahili", "Swati", "Swedish",
"Tagalog", "Tahitian", "Tajiki", "Tamil", "Tatar", "Telugu",
"Tetun", "Thai", "TibetanCentral", "Tigrigna", "TokPisin", "Tongan",
"Tsonga", "Tswana", "Tulu", "Tumbuka", "Turkish", "Turkmen",
"Tuvin", "Udmurt", "Ukrainian", "Urdu", "Uyghur", "Venda",
"Venetian", "Veps", "Vietnamese", "Vlaams", "Walloon", "WarayWaray",
"Welsh", "Wolof", "Xhosa", "Yakut", "YiddishEastern", "YiSichuan",
"Yoruba", "Zeeuws", "Zulu"};
Then, using LanguageData it's quite straightforward to get the native speakers population and the number of wikipedia articles. We can also easily compute the aforementioned ratio:
bubbles =
Map[Callout[{#[[2]], #[[3]], #[[3]]/#[[2]]}, #[[1]]] &,
LanguageData[
languages, {"Name", "NativePopulation", "WikipediaArticleCount"}]]
Finally we can plot the BubbleChart:
BubbleChart[ bubbles,
ScalingFunctions -> {"Log", "Log", Automatic},
ColorFunction -> Function[{x, y, z}, Hue[Log[1 + z]]],
ColorFunctionScaling -> False,
PlotLabel -> Style["Language Wikipedia Articles Per Native Speaker", Bold, 24],
FrameLabel -> {Style["Number Of Native Speakers", 20], Style["Number Of Wikipedia Articles", 20]},
PlotTheme -> "Detailed",
ImageSize -> 800]
(See Top BubbleChart)
It's really interesting to see that most of the biggest bubbles tend to be from languages spoken in developed countries but they don't have their own state yet; i.e. Basque, Scots, Catalan, Breton...
My mother tongue is Catalan and I'm quite happy to see that it's still quite healthy (at least according to its wikipedia activity).
PS: Two years ago @Vitaliy Kaurov wrote a really nice post about the same celebration day. You can read it here.
Happy International Mother Language Day!


