Hello Alex,
basically and in principle I do share Jim's point of view. But just to get things done, here is a "quick and dirty" approach (you are asking for outliers in 3D):
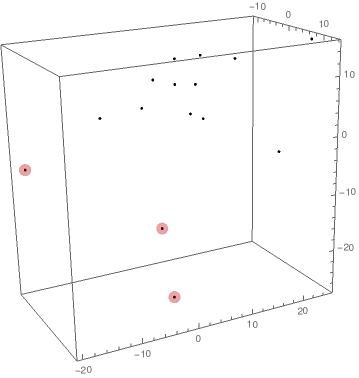
u = {-10, -2, 0, -3, 1, 2, 6, 14, 5, 4, 8, 11, 9, 3, 7};
v = {-19, 5, 1, 1.5, 3.5, -3, 0, 7, 6, -11, 25, 17, 2, 7.5, 4};
w = {-5, 8, -16, 9, 13, 6, -26, 15, 14, 6, 15, -2, 6, 3, 10};
pts = Transpose[{u, v, w}];
anomPts = FindAnomalies[pts, PerformanceGoal -> "Quality", Method -> "Multinormal"];
Graphics3D[{Point[pts], Red, Opacity[.2], Sphere[anomPts, 1]}, Boxed -> True, Axes -> True]