Fantastic post! Thanks a lot!
I am wondering how readily this could be used as a personal tutor/teacher at Universities. I have been teaching the Wolfram Language, Data Science, and Mathematical modelling for many years, and due to University regulations I had to record each and every session (there should be more than 1000 probably 2000 videos; each video should be 2 hours or so. Additionally there are lots of notebooks, and other texts that are relevant.
GPT-4 is able to help a great deal writing and debugging code, as well as interpreting data and building ideas for modelling.
The way we teach is not really tailored to an individual student due to class sizes. We also have many online students in different time zones. It would be great if this technology could give students a 24/7 personal lecturer - and replace me?
Here is an example (we need to keep in mind that GPT3.5 is not that good at programming....):
My question to StephenBot:
"Can you show me some Wolfram Language code to compute the first 20
Fibonacci Numbers, then fit an exponential curve to it, and finally
plot the data points in red and the fit in black in the same plot?"

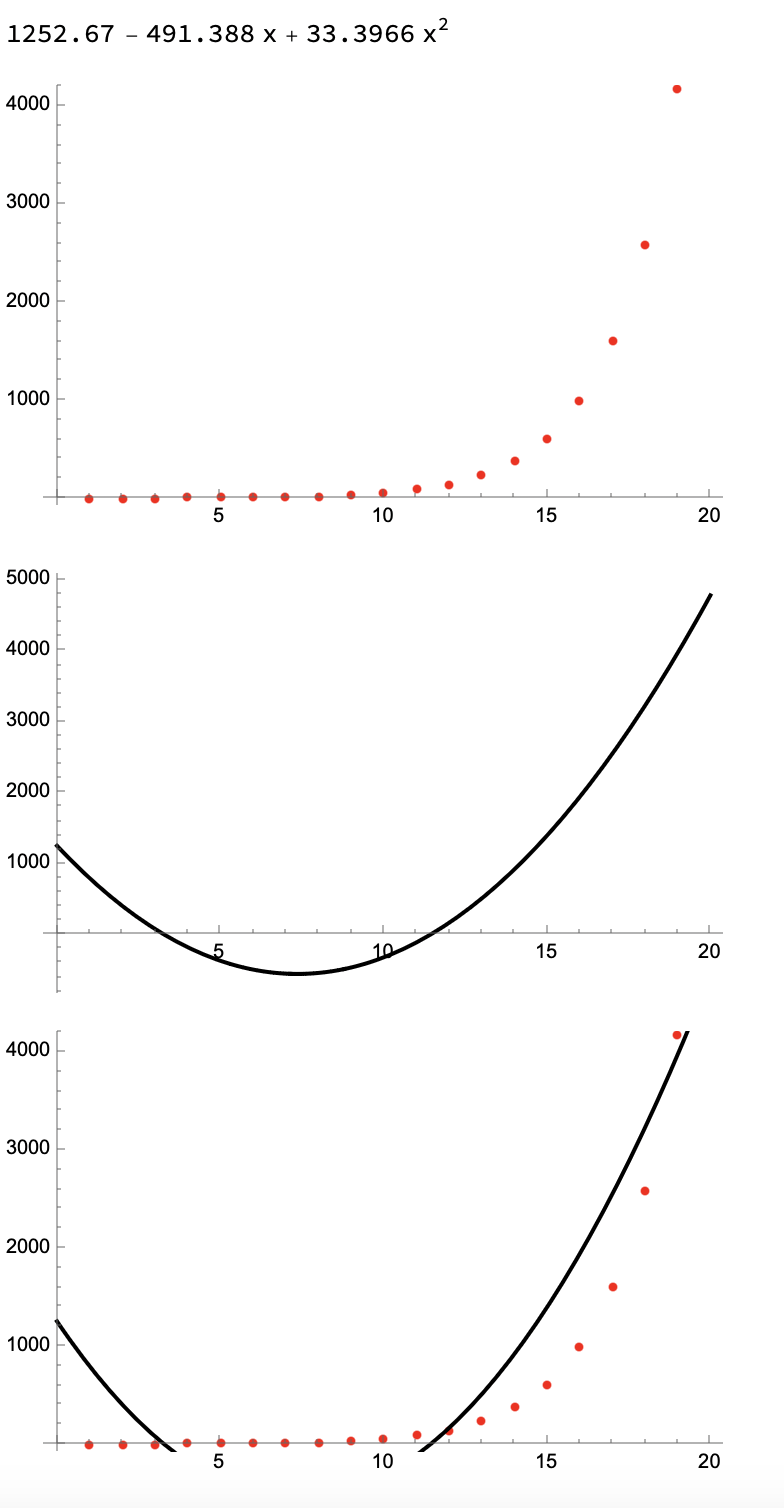
The suggested code does not actually fit an exponential curve, but does quite well:
fibonacci[n_] := If[n <= 1, n, fibonacci[n - 1] + fibonacci[n - 2]]
fibonacciNumbers = Table[fibonacci[i], {i, 20}]
exponentialCurve = Fit[fibonacciNumbers, {1, x, x^2}, x]
plot = ListPlot[fibonacciNumbers, PlotStyle -> Red]
fitPlot = Plot[exponentialCurve, {x, 0, 20}, PlotStyle -> Black]
Show[plot, fitPlot]
I wonder if there is enough data available, whether the Bot would take the special programming style the lecturer promotes into consideration. For example, I very much prefer Functional programming style rather than procedural. Would it be able to mimic the "tricks of the trade"?
In a next step, of course one could think about the ideal combination of lecturers.
Once again: Thanks a lot for the great post.
Cheers,
Marco
PS: Interestingly I have been collecting data of all sorts for many years. Apart from work related recordings, I also have months worth of recordings of everything I have said.
PPS: There are different projects to keep memories of historical events even after eye witnesses have passed away. How expensive was the training and especially the embedding?


