Is there a way to Solve Mod[9 x, 23, x] == 1 algebraically with Mathematica ?
|
|
|
Solve[Mod[9 x,23,x]==1,x]
Please note, that the 3-argument form of Mod means, according to the documentation,
Mod[m, n, d] uses an offset d.
|
|
|
Sorry , error , i have updated , the problem remains the same
|
|
|
Using the Integers option give some answers:
Solve[Mod[9 x, 23, x] == 1, x, Integers]
Reduce[Mod[9 x, 23, x] == 1, x, Integers]
{{x -> -5}}
x == -5
And:
Solve[Mod[9 x, 23] == 1, x, Integers]
{{x -> ConditionalExpression[
18 + 23 ConditionalExpression[1, \[Placeholder]],
ConditionalExpression[1, \[Placeholder]] \[Element] Integers]}}
|
|
|
I had updated my post as I did try that option but I need a positive integer 18. If I use Z
x->18+23 c1
which is correct
|
|
|
It's (the field of) Integers (with 's'), and this will be the same as Z.
|
|
|
You can restrict the value of x via an extra constraint:
Solve[{Mod[9 x, 23] == 1, 0 <= x < 23}, x, Integers]
Reduce[{Mod[9 x, 23] == 1, 0 <= x < 23}, x, Integers]
{{x -> 18}}
x == 18
|
|
|
Update on the course quizzes: We are seeing many people who have passed Quiz 1 and a few who have already passed all the quizzes. Keep up the impressive work! We are investigating a couple problem reports from emails received at wolfram-u@wolfram.com. Thank you for sending detailed problem reports when you encounter them. To clarify the video logging, this is a feature of the course, and videos watched outside of the course (in the Study Group) are not tracked with your course progress. We do have attendance and recording views logged for the Study Group, and this, along with quiz results, allows us to issue certificates of program completion for the Study Group. The Introduction to Cryptography Study Group certificate of completion is considered equivalent to the course completion certificate, and we're pleased to offer both options for earning a certificate for this material.
|
|
|
At the bottom of the course page, the last entry is "Track My Progress." When clicked, it lists two conditions for successful completion of the course:
"Earn your certificate of course completion by watching 25 course videos and ..."
However, it gives me, and I guess others, ZERO credit for watching the videos during Dariia's lectures. I assume this feature is meant for the future course takers, not for the current cohort. Please clarify.
|
|
|
Thank you!
Will check it out.
Best.
M
|
|
|
The two resources that gave me a better understanding of elliptical curves in Mathematica "Elliptic Curve Cryptography with Mathematica" by Jouko Teeriaho (attached ) and a better understanding of the algorithms associated with elliptical curves at Elliptic Curve Cryptography: a gentle introduction by Andrea Corbellini I found the visual tool very handy
 Attachments:
Attachments:
|
|
|
Good to know!
Thank you, Doug.
|
|
|
Thanks, Doug.
Great links, very "hand-on"!
Best.
M
|
|
|
Great find, the elliptic curves notebook by Jouko Teeriaho, Doug!
|
|
|
Doug, Your link to the pdf file (notebook?) by Jouko Teeriaho does not work. Could you re-post it, please? Thanks, Zbigniew
|
|
|
reattached the file
Attachments:
|
|
|
Doug,
Thanks for your quick response. I really appreciate it. And the file indeed looks like a great read--I am delving right into it.
Cheers,
Zbigniew
|
|
|
(Note: The book by Stinson is from 1995, not 1999 as is stated in the first paragraph.) (Notebook attached)
Attachments:
|
|
|
Just in case anyone is interested, Eric W. Weisstein's notebook http://mathworld.wolfram.com/notebooks/NumberTheory/EllipticCurve.nb
in modern notations is simply (show its main part): In[3]:= curves = {x^3 - 1, x^3 + 1, x^3 - 3 x + 3, x^3 - 4 x, x^3 - x}; In[22]:= GraphicsGrid[{ContourPlot[y^2 == #, {x, -3, 3}, {y, -3, 3},
ContourStyle -> {Red, Thick}] & /@ curves}] 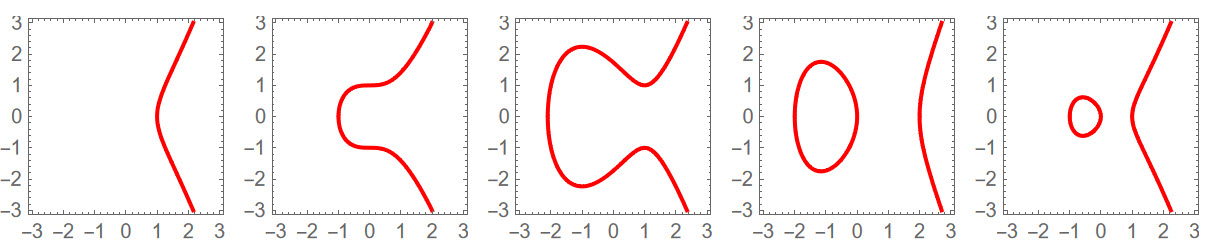
There is no need to install the packages,
GraphicsImplicitPlot and GraphicsColors, and some functions are now (13 years later) outdated.
|
|
|
I took the first quiz and there is some problem with the evaluation system. I scored 0/14. Attempted again and the same result. Then for one of the question, I picked one answer , submit the result and observe the behavior, and repeated it three more times. No matter what option is selected as an answer, score is always 0
|
|
|
Earlier this week I took Quiz 1-4 without any problems. Yesterday I tried Quiz 5 and got the same result as you, i.e. only 0-scores. After quite much of reloading the Quiz page, changing some answer and submitting the answers, it finally worked and I got a proper score. (I reported this to wolfram-u@wolfram.com so they should be aware of the problem.)
|
|
|
I confirm this problem: Taking the first quiz today and got 0 scores as well.
The quiz frame also errors out with the following errors:
 (It also shows : v1.20220128 )
|
|
|
I did what you suggested but did not work, I am still awaiting contact from the email I sent to wolfram-u@wolfram.com
|
|
|
I just took Quiz 6 and it worked without any problems.
Also, there are no error/warnings at the end of the page that was - and still is - in my Quiz 5 page (but as mentioned above I did pass that Quiz as well).
|
|
|
Given the number of times Claude Shannon's name has come up during the study group, I thought that SG participants might want to learn more about this amazing man. I thought he was brilliant before joining the study group and my admiration has only increased over the past two weeks. A Mind at Play: How Claude Shannon Invented the Information Age Kindle Edition
by Jimmy Soni (Author), Rob Goodman (Author)
In their second collaboration, biographers Jimmy Soni and Rob Goodman present the story of Claude Shannon—one of the foremost intellects of the twentieth century and the architect of the Information Age, whose insights stand behind every computer built, email sent, video streamed, and webpage loaded. Claude Shannon was a groundbreaking polymath, a brilliant tinkerer, and a digital pioneer. He constructed the first wearable computer, outfoxed Vegas casinos, and built juggling robots. He also wrote the seminal text of the digital revolution, which has been called “the Magna Carta of the Information Age.” In this elegantly written, exhaustively researched biography, Soni and Goodman reveal Claude Shannon’s full story for the first time. With unique access to Shannon’s family and friends, A Mind at Play brings this singular innovator and always playful genius to life.
|
|
|
ok, so really to use zero to 25 and then use the mod 25 is the best policy...I should have thought to try that. Thanks Hermes, I will recalculate and we can continue. Great conversation here!
|
|
|
for the vigenere question I have h e l l o w o r l d
08 05 12 12 15 23 15 18 12 04 m y k e y m y k e y
13 25 11 05 25 13 25 11 05 25 Mod[8+13,26] = 21
Mod[5+25,26] = 04
Mod[12+11,26] = 23
Mod[12+05,26] = 17
Mod[15+25,26] = 14
Mod[23+13,26] = 10
Mod[15+25,26] = 14
Mod[18+11,26] = 03
Mod[12+05,26] = 17
Mod[04+25,26] = 03 U D W Q N I N C Q X
21 4 23 17 14 10 14 03 17 03 Using the Vigenère cipher, what is the encrypted form of the message “helloworld” using the key “mykey”? tcvpmimbpb khoorzruog uryybjbeyq ->None of the above Shows a wrong answer for quiz 1, am I off base on this? Thanks for a good clue Luke and a really great course, I could do another month of this class! This seemed a little specific for the community discussion, but if it is apropos I am happy to stand corrected of course.
|
|
|
It appears that when they encoded the message and the key, before doing the "encryption" step, they just offsetted by the character code of "a", i.e. offsetted everything in such a way that the letter 'a' gets coded to 0, 'b' to 1, etc., and then after the encryption step, to go back from the new character codes to letters, they did the reverse offset. They didn't add an extra offset of "1" to the character code of "a", in order to make 'a' coded to 1, 'b' to 2, etc.
|
|
|
Also thanks for the proof around 30min. It is quite nice and easy, and lends itself well to a discussion of "confusion" from your suggested article. Here is another notation using Fold:
FeistelForm[kn_] := {#[[2]], Xor[#[[1]], F[#[[2]], kn]]} &
FoldList[#2@#1 &, {L, R}, {
FeistelForm[k1], FeistelForm[k2], FeistelForm[k3], Reverse,
FeistelForm[k3], FeistelForm[k2], FeistelForm[k1], Reverse
}] ;
SameQ[%[[1]], %[[-1]]]
Out[] = True
Let's try and make this a little easier for Physicists (or former) by assuming that
$F$ is just addition, then the naive form reduces to linear algebra:
NaiveFeistelForm[kn_] := {{0, 1}, {1, 1}} . # + {0, F[kn]} &
FoldList[#2@#1 &, {L, R}, {
NaiveFeistelForm[k1], NaiveFeistelForm[k2], NaiveFeistelForm[k3],
Reverse,
NaiveFeistelForm[k3], NaiveFeistelForm[k2], NaiveFeistelForm[k1],
Reverse
}] /. {_Integer?EvenQ -> 0, _Integer?OddQ -> 1};
SameQ[%[[1]], %[[-1]]]
Out[]=True
What happens here is basically a nesting
$g \cdot( \ldots( g\cdot(g\cdot s + p_1) + p_2 ) \ldots ) + p_n $, and it's easy to see if distributive holds we get
$g^n \cdot s +P$ where
$s$ is signal,
$P$ a summed pad, and mixing matrix
$g$ satisfies
$g^3=Id$. This is the same problem I mentioned previously, where Feistel scheme essentially reduces to a one time pad. However if the pair of operations
$(\cdot,+)$ do not allow distributive property, then the nested form above might actually be a decent characterization of what is meant (loosely) by "Feistel Scheme". There is one alternative, applying the pad before the mixing:
$g \cdot( \ldots( g\cdot(g\cdot (s + p_1) + p_2 ) \ldots + p_n) $. In this case distributive does not hold if
$g\cdot (s + p_1) \neq g\cdot s +g\cdot p_1 $, which is what we want to fix the previous algorithm. Start by generating test data:
SeedRandom["confusion"];
randPad = RandomInteger[{0, 4}, 32];
randMessage = RandomInteger[{0, 4}, 32];
And weakly prove (in terms of test data) distributive holds in the previous case:
SameQ[ Flatten[ Mod[ForwardMix . Partition[Plus[randPad, randMessage], 8], 5]],
Flatten[Mod[Plus[ ForwardMix . Partition[randPad, 8],
ForwardMix . Partition[randMessage, 8]], 5]]]
Out[]=True
This is what we don't want, so we need to add new Addition and Subtraction functions (the idea is taken from Dariia's suggested reference above):
BoxSubtract[dat1_, dat2_, part_, base_] :=With[{ints = (FromDigits[#, base] & /@
Partition[#, part]) & /@ {dat1, dat2}}, Flatten[
IntegerDigits[#, base, part] & /@ Mod[Subtract @@ ints, base^part]]]
BoxPlus[dat1_, dat2_, part_, base_] := With[{ints = (FromDigits[#, base] & /@
Partition[#, part]) & /@ {dat1, dat2}}, Flatten[
IntegerDigits[#, base, part] & /@ Mod[Plus @@ ints, base^part]]]
(* test inverse property *)
SameQ[BoxSubtract[BoxPlus[randPad, randMessage, 8, 5], randPad, 8, 5], randMessage]
Out[]=True
Again here is a proof that distributive doesn't hold:
(* not distributive *)
SameQ[ Flatten[ Mod[ForwardMix . Partition[BoxPlus[randPad, randMessage], 8], 5]],
Flatten[Mod[BoxPlus[ ForwardMix . Partition[randPad, 8],
ForwardMix . Partition[randMessage, 8]], 5]]]
Out[]=False
Then our Encode / Decode functions need only minor modification, replacing Plus and Subtract for BoxPlus and BoxSubtract:
EncodeRound[sig_, AGmat_] := Flatten[
Mod[ForwardMix . Partition[BoxPlus[sig, AGmat, 8, 5], 8], 5]]
DecodeRound[sig_, AGmat_] := Mod[BoxSubtract[ReplaceAll[
Mod[Flatten[ReverseMix . Partition[sig, 8]], 5], Div4], AGmat,
8, 5], 5]
Using these updated functions, we can produce another set of encrypts: 
These are possibly better than the previous set since we are doing a little more than just padding, but the run statistics really don't look any better. I am still skeptical--What exactly do we gain by requiring non-distributive property? Is one data set easier to decrypt than another? I think that the non-distributive property must be an important defining part of what makes a Feistel Cipher, but I don't yet completely understand the theory why. Anyone else, agree / disagree? Thoughts?
|
|
|
Just watched Stephen Wolfram, Dariia and others in "Live CEOing Ep 555: Language Design in Wolfram Language [Hash Related Functions]" (YouTube: https://www.youtube.com/watch?v=0JZVX6kDEQU and Twitch: https://www.twitch.tv/videos/1293670192 ). It's always interesting to listen to this kind of discussions. They discussed new features in Wolfram Language regarding Hash function, Digital Signature etc. How appropriate for us. :-)
|
|
|
It's always fun to hear about these kind of discussions, especially about how a function should be named or which parameters / their orders should be, in order to be the most general and not have to be changed in the very near future of its introduction.
|
|
|
Should hash values calculated with the same algorithms but on different platforms agree?
Yes they should. If you find they don't, as pointed out by Dariia and Doug, check whether it's because their output representation is just given in a different way (for numbers -> different bases, etc.)
Otherwise it may be due because the data being hashed might have looked the same but is actually different in some way: e.g. for strings: they were provided in different encodings (for example, utf8 vs. utf16 vs. something else). Within WL, check whether the data you want to encode is not "embedded" into an overall WL "object" that would thus change what's going to be actually encrypted.
|
|
|
Question for the community: Should hash values calculated with the same algorithms but on different platforms agree? I tried comparing the hash digest for a simple text string ("abcdefg") calculated with Mathematica and calculated with an online calculator
https://www.fileformat.info/tool/hash.htm . The notebook is attached. I tried a few different hash algorithms but the hash digests did not agree with the Mathematica digest.
Attachments:
|
|
|
Specify "HexString" as 3rd argument to Hash, by default it produces an integer.
|
|
|
Thanks! The daily study group is very interesting and informative.
|
|
|
Is it not that you must select the correct output type eg Hash["abcdefg", "Adler32"] 182125245 Hash["abcdefg", "Adler32", "HexString"] 0adb02bd
|
|
|
After watching the last session on Feistel schemes and reading some of Hakan's code, it seems like we have a pro-binary bias sneaking in here. The overall theme of this post is to say that cryptography still works with more than two symbols (or without self-inverse properties), but the implementation may not be as neat and simple. For example, Dariia's transformation analysis of Feistel scheme might not apply at higher radix, if XOR is generalized to addition modulo base
$b>2$. As long as implementations still run fast, added complexity can even serve a purpose relative to the adversary. Here is some encrypted data, which I claim is the output of a sort-of Feistel Cipher:  Repeated Encryption of a length 32 message over 4 symbols
Repeated Encryption of a length 32 message over 4 symbols
To the eye, it looks random, but we need to do testing. Normality does not imply randomness, but it is a necessary condition. We can easily check run lengths in base 5 (the encrypt base is one higher than the message base), but first let's look at base 10 encoding:
encodes = Partition[Partition[#, 4][[All, 1]] & /@ Transpose[ReplaceAll[
Round[ImageData[Import["~/Work/Cryptography/encrypts.png"]]],
{{1, 0, 0} -> 2, {0, 1, 0} -> 3, {0, 0, 1} -> 1, {1, 1, 1} ->
0, {1, 1, 0} -> 4}]], 4][[All, 1]];
Row[Show[#, ImageSize -> 300] & /@ {Histogram[
FromDigits[#, 5] & /@ encodes, 10],
ListLogPlot[FromDigits[#, 5] & /@ encodes]}, Spacer[20]]
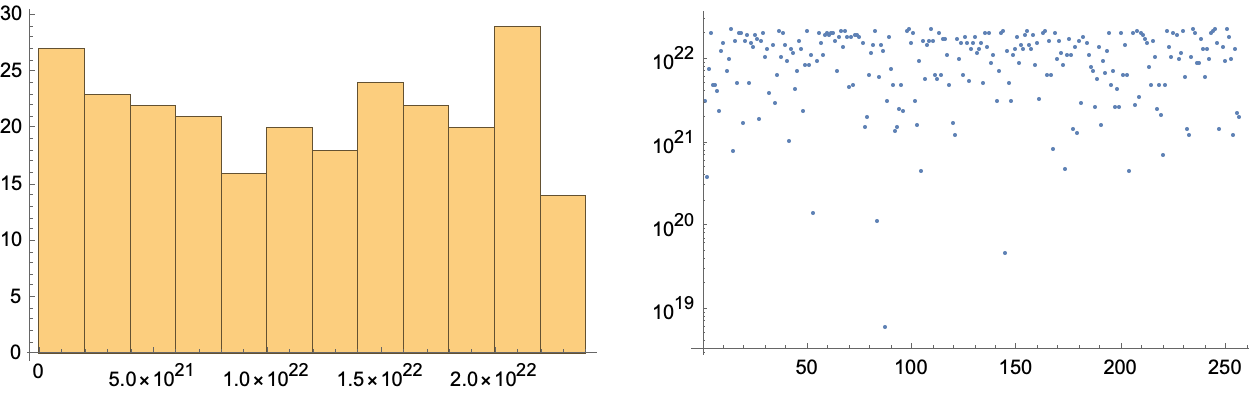
Decently flat between
$10^{21}$ and
$10^{22}$. Now here are run length tests, which I have written in a base-dependent graphical form:
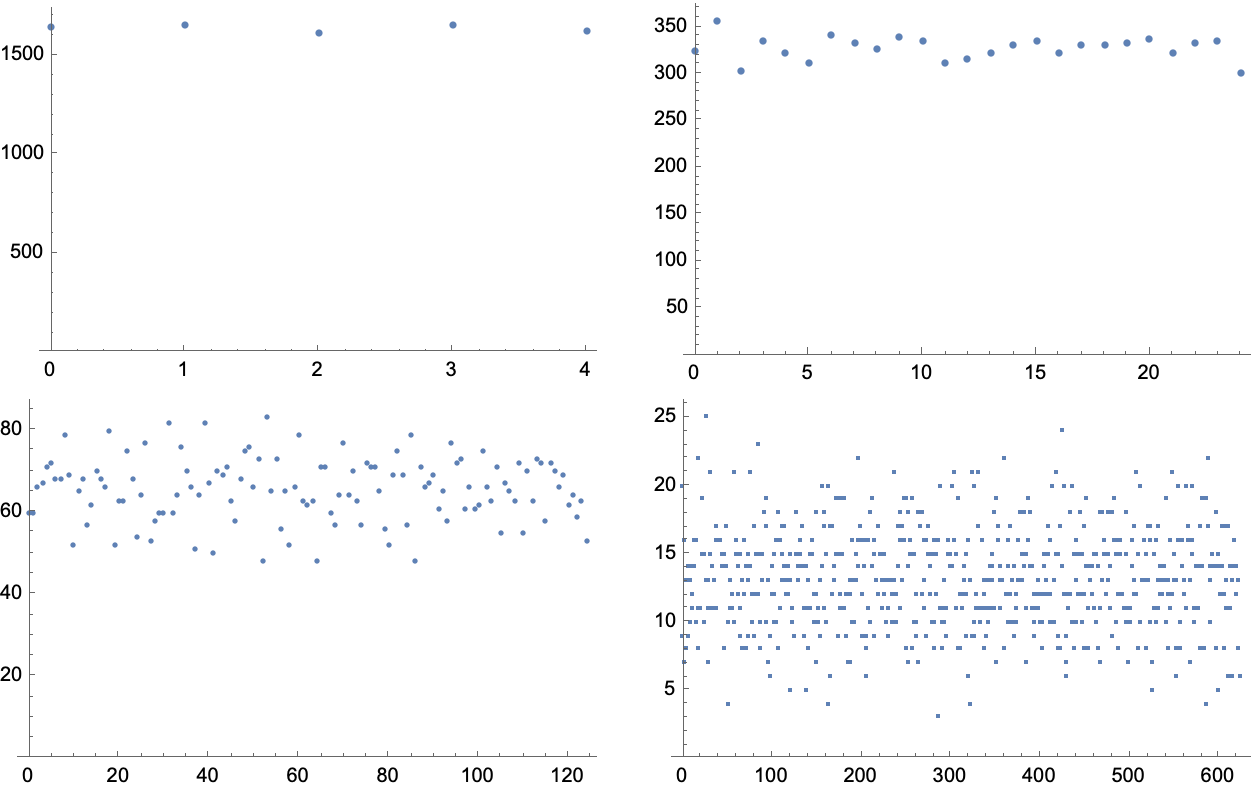
TestNormalListPlot[data_, runLen_, base_] := ListPlot[
Tally[FromDigits[#, base] & /@ Flatten[
Partition[#, runLen, 1, 1] & /@ data, 1]],
PlotRange -> {0, Automatic}]
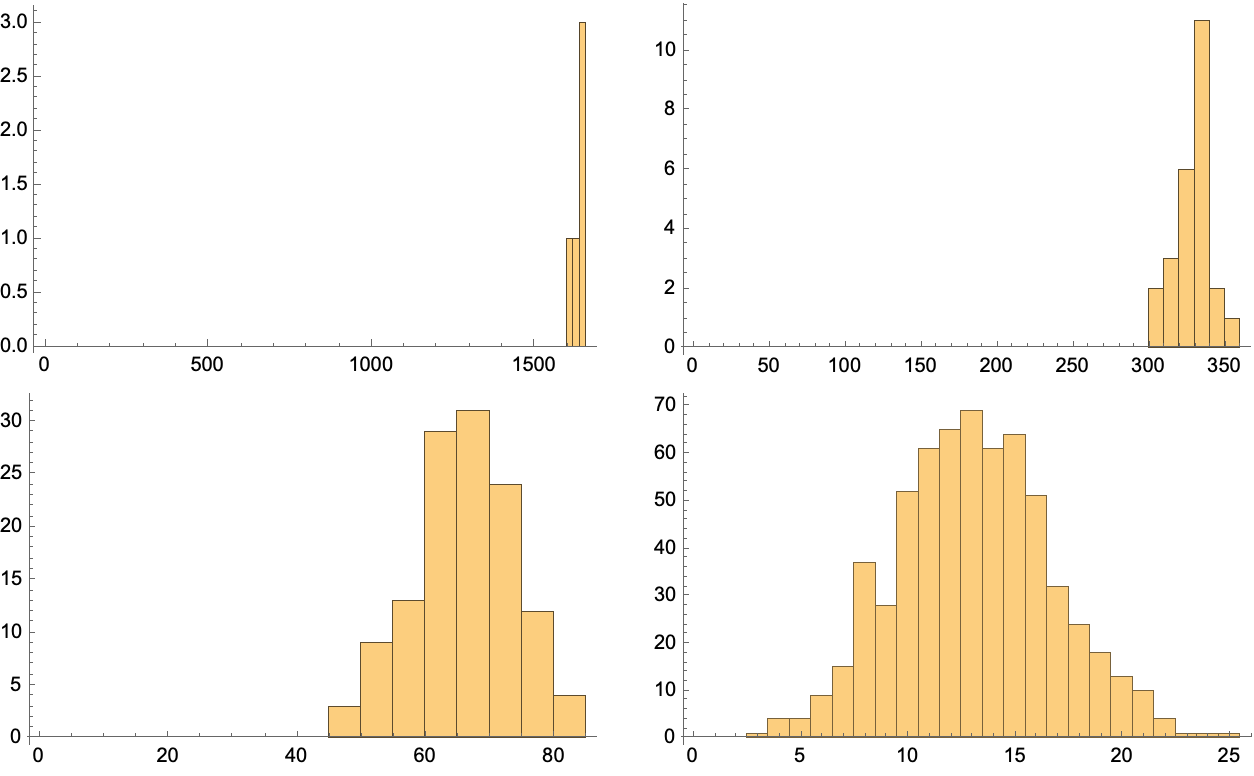
TestNormalHistogram[data_, runLen_, base_] := Histogram[
Tally[FromDigits[#, base] & /@ Flatten[
Partition[#, runLen, 1, 1] & /@ data, 1]][[All, 2]],
PlotRange -> {{0, Automatic}, {0, Automatic}}]
And the output data looks Gaussian distributed as is expected for random inputs:
TableForm[Partition[Show[
TestNormalListPlot[encodes, #, 5],
ImageSize -> 300] & /@ Range[4], 2]]
TableForm[Partition[Show[
TestNormalHistogram[encodes, #, 5],
ImageSize -> 300] & /@ Range[4], 2]]
The purpose of the entire battery of diehard tests is to look beyond normalcy for other hints of randomness. Diehard is considered state of the art in practice, but I've heard that machine learning can sometimes do better finding bits of unexpected order. So I'll leave the question open, does anyone have a test on the data above that is predictive of at least one digit (without peeping at the keys, which are online somewhere)? We definitely can't look at an Feistel Cipher output and identify it as such. For the output above, we probably can't rule out that it follows from a Feistel cipher (again, unless someone starts predicting digits). So instead we have to go back to algorithm analysis. Dariia's transformation analysis gives us a nice place to start--if we just ignore the issue about S-Boxes. I don't know anyone else's opinion, but Daniel Bernstein's argument against S-Boxes has influenced my thinking that "S-Boxes are just mathematical functions with some certain properties, and they may not always be necessary". Now, Dariia has emphasized self-inverse as a defining property of Feistel cipher, but I disagree by saying that the self-inverse property is a result of choosing
$\bigoplus$ as Addition modulo 2, and choosing a parity permutation group, for which group action is self inverse. If another choice is made, say addition modulo 5 with cyclic permutation of order 4, then the parity symmetry is broken and an inverse round function is needed. Such an algorithm keeps a reversible key-schedule, and may mix blocks more effectively, thus reducing need for round function
$F$ to be overly complex. Here again is the code for producing encrypts above, and for decrypting them when the corresponding secret keys are known. First an apparently(?) almost pseudo-random number generator (thanks again Larva Labs!):
ONE = 4294967296;
SIZE = 32; HALFSIZE = 16;
xyz[ind_, aVal_] := With[{x0 = 2*(ind - HALFSIZE) + 1},
x0*aVal^2 (*hacked to force overflow, no sym*)]
v[x_, y_, z_, mod_] := With[{v0 = Mod[Floor[
If[# > 2^255 - 1, Mod[(# - 2^256)/ONE + 1, 2^256],
#/ONE] &@Mod[x*y*z, 2^256]], mod]},
If[v0 < 5, v0, 0]]
AutoGlyphM1D[aVal_] := With[{mod = Mod[aVal, 11] + 5},
Outer[v[xyz[#1, aVal], 1, 1, mod] &,
Range[0, SIZE - 1], 1]]
Next the round functions, key iterator, etc. : : :
ItKeys[key_, nInd_] :=
Map[Mod[Floor[key Pi^#], 2^160] &, Range[0, nInd - 1]]
(* Eigenvectors of CyclicG4 *)
ForwardMix = {
{1, 1, 1, 1},
{1, -1, 1, -1},
{1, 0, -1, 0},
{0, -1, 0, 1}};
ReverseMix = 4 Inverse[ForwardMix];
Div2 = MapThread[Rule, {Mod[2 Range[0, 4], 5], Range[0, 4]}];
Div4 = MapThread[Rule, {Mod[4 Range[0, 4], 5], Range[0, 4]}];
EncodeRound[sig_, AGmat_] := Flatten[
Mod[ForwardMix . Partition[Plus[sig, AGmat], 8], 5]]
DecodeRound[sig_, AGmat_] := Mod[Subtract[ReplaceAll[
Mod[Flatten[ReverseMix . Partition[sig, 8]], 5], Div4],
AGmat], 5]
Char4Encode[sig_, key0_, recd_] := Fold[
EncodeRound[#1, AutoGlyphM1D[#2]] &,
sig, ItKeys[key0, recd]]
Char4Decode[Crypted_, key0_, recd_] := Fold[
DecodeRound[#1, AutoGlyphM1D[#2]] &,
Crypted, Reverse@ItKeys[key0, recd]]
And the call to decrypt is:
AbsoluteTiming[ decodes = MapThread[Char4Decode[#1, #2, 4] &,
{encodes, SecretKeys}];]
Union[Style[ StringJoin[
FromCharacterCode[FromDigits[#, 4]] & /@ Partition[#, 8]],
Bold, 16] & /@ decodes]
Out[]= l.t. 1s
Out[]={????}
So what are we still arguing about? Well, it may be possible to choose a self-inverse permutation, starting from something like:
Mod[# . # &@(ForwardMix . ForwardMix), 5] /. Div2
Out[]= Identity Matrix 4
And maybe if we applied more creativity and / or chose an even radix, we could find an operator such as
$x \bigoplus y=x+b/2\times y \mod b$ which would be self inverse for radix
$b$, I don't know, and don't know if we should spend time on that question. So, in the end, Dariia and the rest of the experts might be right, self-inverse could be a necessary property of the Feistel Scheme. In that case, how to categorize the encrypt / decrypt algorithm presented above? Clearly we can change to whatever base, and use whatever permutation group representations so long as the inverse details work out. Does anyone have a reference to anything like this in the literature?
|
|
|
The confusion property on P. 31 looks good. One weakness of the above algorithm is that linearity of encode rounds ensures after four rounds that the ciphertext is permuted back to its original place with a factor 2, not ideal. In that sense, my simple algorithm looks more like a one time pad. However, I could also argue that Feistel cipher is just a clever way to apply one time pads. Back to the drawing board... maybe a permutation over all 32 indices?
|
|
|
I have been looking at how to create a quality metric for various ciphers and came up with a couple of tests. I'm sure there is some standard "cookbook" of tests that get applied but haven't seen such a thing yet. Have a look at my take on this. It considers frequency and statistics to compare the spiky image from lesson 13.
Attachments:
|
|
|
Nice! Did you look at NIST's "A Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications" (https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-22r1a.pdf) that Dariia mentioned in the session about Randomness/Pseudorandomness? It contains a Fourier related test (section "2.6 Discrete Fourier Transform (Spectral) Test") and a lot of other statistical tests. Though I don't find anything about your other test, the QuantilePlot Analysis. The notebook "09_Randomness and pseudorandomness.nb" has some other recommended documents as well (in the Further Reading section)..
|
|
|
Here is my write up on Dariia's Weekend "assignment" (attached).
Attachments:
|
|
|
Thanks, Dariia! I'll check out those more complex tests. Though I do like to implement stuff. :-)
|
|
|
You can always implement others and contribute to the Function Repository too!
|
|
|
Questions for Dariia (or other experts): Is there a list where WFR covers diehard tests, and are we missing any? What does it really mean if an encrypt fails diehard? I'm thinking that a combination of steganography with cryptography could fail diehard and still be decently hard metal. For example, did anyone decode the fake NFTs that I made for the "happy new years" contest?
|
|
|
Hi Can you use UTF-16 encoding with the Hash function in Mathematica? In Python :- 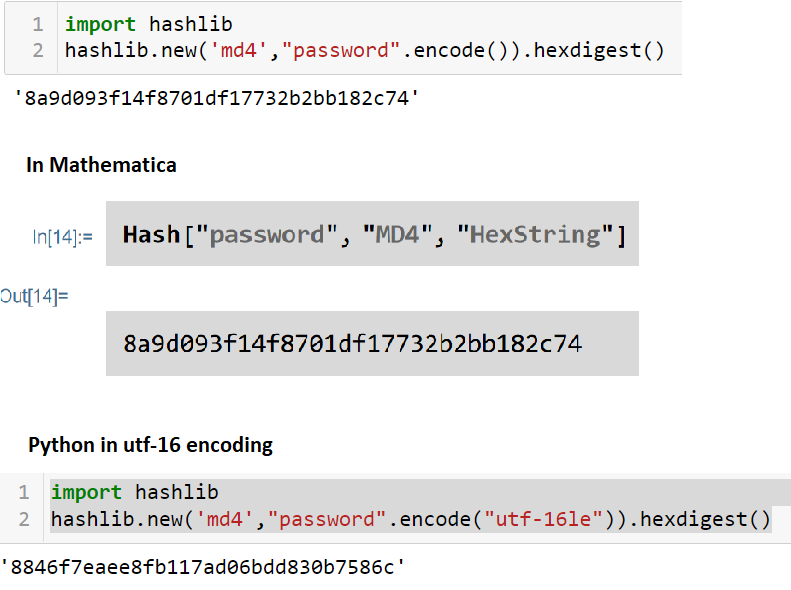
|
|
|
Wolfram does not support UTF16 encoding unfortunately
|
|
|
I tried to set up a UTF-8/UTF-16 conversion code in WL, see attached notebook (for UTF-16 it is also important to know what the underlying endianness of the byte stream is).
Hope that it helps!
Suggestions for improvements are welcome :)
maybe at some point this could be turned into an entry into the function repository? (I haven't seen any existing UTF16-related function there). Using these functions, the UTF16-LE example of Mr. Beveridge would look as follows:
In[1]:= Hash[UnicodeToUTF16LE[ToCharacterCode["password"], "ByteArray"], "MD4", "HexString"]
Out[1]= 8846f7eaee8fb117ad06bdd830b7586c
This agrees with the Python result.
Attachments:
|
|
|
Hi Hermes Wow , that is impressive . I will play around with it to test it but it looks great and a candidate for the repository. There does not seem to be a textbook of "Encryption with Mathematica" so I got the next best thing, "Encryption with python " books and as the functions are similar it is quite easy to convert from python hashlib library to the Wolfram Hash Function. The textbooks I have consulted all use the Windows NTLM Microsoft authentication protocol that uses UTF-16 Little Endian encoding as examples. (Maybe there is a little bias by Wolfram to Mac and Linux against Windows :) )
|
|
|
Note that this is not a very serious crypto analysis of hash
collisions since we know that these hash functions are not secure (and
some of them are not designed to be crypto secure).
As you also mentioned above, Adler32 is not a serious hash function. It is easy to study from first principles and find how to design a collision algorithm. This was done on a previous thread "Hello World = Goodbye World: chosen-prefix collision attack" (editors note: we have since learned that the word "attack" is better replaced by "analysis"). I did not put very much thought or effort into the above, so it would be interesting to see who can improve these results and how. If anyone has a good MD5 collider, that might make a good contribution to Wolfram Function Repository. Happy searching!
|
|
|
Brad, thanks for the link of your analysis. I'll read it more carefully and also the "SHA-1 is a Shambles" article you cited (https://sha-mbles.github.io/ ).
|
|
|
Here is a notebook exploring if some of WL's simpler hash functions generates hash collisions for some of WL's wordlists.
|
|
|
A related idea is to search for the smallest hash collisions for the two weak hash functions (CRC32 and Adler32) and use all possible strings of a certain size. Unfortunately, for the generated wordlists that I could test, there wasn't any hash collisions which surprised me a little. Anyway, here's the idea and the code. Let's assume that we use words with strings of the characters [a-zA-Z0-9] and generate all possible strings up to a certain length, i.e. size = 3 generates all possible strings of length 1, 2, and 3. Here's the alphabet and 30 random samples:
alpha = Flatten[{CharacterRange["a", "z"], CharacterRange["A", "Z"],
CharacterRange["0", "9"]}];
RandomSample[
Table[StringJoin[#] & /@ Tuples[alpha, n], {n, 1, 3}] // Flatten, 30]
{"oEg", "LMZ", "j3n", "GDY", "dUe", "7ma", "Z5x", "jtb", "6OI", \
"HdL", "EzE", "VMY", "OYM", "p7Z", "PNg", "Vqz", "obw", "Kyj", "OUi", \
"pda", "LwI", "S2A", "4KO", "Ah0", "VsX", "XI4", "ZiC", "tRE", "EMv", \
"fc3"}
We reuse some of the functions from the original notebook:
crc32[word_] := Hash[word, "CRC32", "HexString"]
adler32[word_] := Hash[word, "Adler32", "HexString"]
listCollisions2[words_, fun_] :=
Module[{hashList, counts, hashMap, collisions},
hashList = fun[#] & /@ words;
If[Length[hashList] != Length[words],
counts = Counts[hashList];
hashMap = AssociationThread[words -> hashList];
collisions = Keys@Select[counts, # > 1 &];
Table[Select[hashMap, # == c & ], {c, collisions}] ,
{} (* else: no collisions *)
]
]
As mentioned above, we don't found any hash collisions for CRC32 or Adler32 for sizes up to 4:
Table[{n, listCollisions2[generateWords[n], crc32]}, {n, 1, 4}] // AbsoluteTiming
{25.0142, {{1, {}}, {2, {}}, {3, {}}, {4, {}}}}
Table[{n, listCollisions2[generateWords[n], adler32]}, {n, 1, 4}] // AbsoluteTiming
{25.9066, {{1, {}}, {2, {}}, {3, {}}, {4, {}}}}
One major problem with this approach is that the size of wordlists increases very fast and soon be forbiddingly large:
Table[{n, Length[generateWords[n]]}, {n, 1, 4}] // TableForm
{
{1, 62},
{2, 3 906},
{3, 242 234},
{4, 150 18 570}
}
For size 5, I couldn't even generate the wordlist (got the error "No more memory available. Mathematica kernel has shut down"), but using WL's excellent FindSequenceFunction we can at least estimate the sizes of the wordlists for larger sizes:
FindSequenceFunction[{62, 3906, 242234, 15018570}]
{#, %[#]} & /@ Range[1, 10] // TableForm
which outputs
62/61 (-1 + 62^#1) &
{
{1, 62},
{2, 3906},
{3, 242234},
{4, 15018570},
{5, 931151402},
{6, 57731386986},
{7, 3579345993194},
{8, 221919451578090},
{9, 13759005997841642},
{10, 853058371866181866}
}
Thus, generateWords[5] would give a wordlist of 931 151 402 words. Update: Perhaps it's not that surprising that there are no hash conflicts for Adler32. Here are some of the words and their Adler32 hashes for the size 4 generated words, i.e. the hashes are distinct and just incrementing from the last (two counters) and are in order.
Short[{#, adler32[#]} & /@ generateWords[4], 20]
{{"a", "00620062"}, {"b", "00630063"}, {"c", "00640064"}, {"d",
"00650065"}, {"e", "00660066"}, {"f", "00670067"}, {"g",
"00680068"}, {"h", "00690069"}, {"i", "006a006a"}, {"j",
"006b006b"}, {"k", "006c006c"}, {"l", "006d006d"}, {"m",
"006e006e"}, {"n", "006f006f"}, {"o", "00700070"}, {"p",
"00710071"}, {"q", "00720072"}, {"r", "00730073"}, {"s",
"00740074"}, {"t", "00750075"}, {"u", "00760076"}, {"v",
"00770077"}, {"w", "00780078"}, {"x", "00790079"}, {"y",
"007a007a"}, {"z", "007b007b"}, {"A", "00420042"}, {"B",
"00430043"}, {"C", "00440044"}, {"D", "00450045"}, {"E",
"00460046"}, {"F", "00470047"}, <<15018506>>, {"999E",
"024a00f1"}, {"999F", "024b00f2"}, {"999G", "024c00f3"}, {"999H",
"024d00f4"}, {"999I", "024e00f5"}, {"999J", "024f00f6"}, {"999K",
"025000f7"}, {"999L", "025100f8"}, {"999M", "025200f9"}, {"999N",
"025300fa"}, {"999O", "025400fb"}, {"999P", "025500fc"}, {"999Q",
"025600fd"}, {"999R", "025700fe"}, {"999S", "025800ff"}, {"999T",
"02590100"}, {"999U", "025a0101"}, {"999V", "025b0102"}, {"999W",
"025c0103"}, {"999X", "025d0104"}, {"999Y", "025e0105"}, {"999Z",
"025f0106"}, {"9990", "023500dc"}, {"9991", "023600dd"}, {"9992",
"023700de"}, {"9993", "023800df"}, {"9994", "023900e0"}, {"9995",
"023a00e1"}, {"9996", "023b00e2"}, {"9997", "023c00e3"}, {"9998",
"023d00e4"}, {"9999", "023e00e5"}}
Testing with some longer words and it use the same principle of two counters:
{#, adler32[#]} & /@ {"aaaaa", "aaaab", "aaaac", "aaaaaaaaaaa",
"aaaaaaaaaab",
"aaaaaaaaaaaaaaaaaaa", "aaaaaaaaaaaaaaaaaab"}
{{"aaaaa", "05b401e6"}, {"aaaab", "05b501e7"}, {"aaaac",
"05b601e8"}, {"aaaaaaaaaaa", "190d042c"}, {"aaaaaaaaaab",
"190e042d"}, {"aaaaaaaaaaaaaaaaaaa",
"48110734"}, {"aaaaaaaaaaaaaaaaaab", "48120735"}}
The hashes for CRC32 is much more random like:
Short[{#, crc32[#]} & /@ generateWords[4], 20]
{{"a", "e8b7be43"}, {"b", "71beeff9"}, {"c", "06b9df6f"}, {"d",
"98dd4acc"}, {"e", "efda7a5a"}, {"f", "76d32be0"}, {"g",
"01d41b76"}, {"h", "916b06e7"}, {"i", "e66c3671"}, {"j",
"7f6567cb"}, {"k", "0862575d"}, {"l", "9606c2fe"}, {"m",
"e101f268"}, {"n", "7808a3d2"}, {"o", "0f0f9344"}, {"p",
"82079eb1"}, {"q", "f500ae27"}, {"r", "6c09ff9d"}, {"s",
"1b0ecf0b"}, {"t", "856a5aa8"}, {"u", "f26d6a3e"}, {"v",
"6b643b84"}, {"w", "1c630b12"}, {"x", "8cdc1683"}, {"y",
"fbdb2615"}, {"z", "62d277af"}, {"A", "d3d99e8b"}, {"B",
"4ad0cf31"}, {"C", "3dd7ffa7"}, {"D", "a3b36a04"}, {"E",
"d4b45a92"}, {"F", "4dbd0b28"}, <<15018506>>, {"999E",
"8fef8e8d"}, {"999F", "16e6df37"}, {"999G", "61e1efa1"}, {"999H",
"f15ef230"}, {"999I", "8659c2a6"}, {"999J", "1f50931c"}, {"999K",
"6857a38a"}, {"999L", "f6333629"}, {"999M", "813406bf"}, {"999N",
"183d5705"}, {"999O", "6f3a6793"}, {"999P", "e2326a66"}, {"999Q",
"95355af0"}, {"999R", "0c3c0b4a"}, {"999S", "7b3b3bdc"}, {"999T",
"e55fae7f"}, {"999U", "92589ee9"}, {"999V", "0b51cf53"}, {"999W",
"7c56ffc5"}, {"999X", "ece9e254"}, {"999Y", "9beed2c2"}, {"999Z",
"02e78378"}, {"9990", "af800b3e"}, {"9991", "d8873ba8"}, {"9992",
"418e6a12"}, {"9993", "36895a84"}, {"9994", "a8edcf27"}, {"9995",
"dfeaffb1"}, {"9996", "46e3ae0b"}, {"9997", "31e49e9d"}, {"9998",
"a15b830c"}, {"9999", "d65cb39a"}}
|
|
|
Just a small thing I noticed in the course notebook 11_Security features in the section with the collision for different hexadecimals hashed with MD5.
SameQ was returning True regardless of what type of hash I was choosing. I think it works when implemented with "@@" on the list returned from the hashing function. i.e. the SHA256 hashes are different.
In[17]:= SameQ[Hash[BaseDecode[#, "Base16"], "SHA256"] & /@ {hex1, hex2}]
Out[17]= True
In[18]:= SameQ@@(Hash[BaseDecode[#, "Base16"], "SHA256"] & /@ {hex1, hex2})
Out[18]= False
The MD5 hash is still identified as identical.
In[20]:= SameQ@@(Hash[BaseDecode[#, "Base16"], "MD5"] & /@ {hex1, hex2})
Out[20]= True
|
|
|
Thanks for finding this! In[120]:= SameQ[a, b] Out[120]= False In[118]:= SameQ @@ {a, b} Out[118]= False In[119]:= SameQ[{a, b}] Out[119]= True In[117]:= SameQ@{a, b} Out[117]= True
|
|
|
Good catch! Thank you! I will fix it in the course notebook!
|
|
|
This group might be interested in a post a made a few months ago Twitter steganography. The interesting use for steganography may be to send encrypted information attached to Twitter photos. As a communication channel it might be very hard to monitor and notice when encrypted information was actually being transmitted.
|
|
|
Earlier this week Linear Congruential Generators (LCG) was mentioned and I was trying to solve/attack the simple example that was mentioned in the notebook (09Randomnessand_psedorandomness.nb), but was not able to figure out how to restore the parameters a, b, and m in the LCG function. Here's the definition of the LCG from the notebook and the first 10 generated numbers in the sequence:
a = 65539;
b = 0;
m = 2^31;
LCG[seed_Integer] := Mod[a*seed + b, m];
NestList[LCG, 1, 10]
(the output:)
{1, 65539, 393225, 1769499, 7077969, 26542323, 95552217, 334432395, \
1146624417, 1722371299, 14608041}
First some simple trials of getting back the used values of a , b, and m using different approaches that doesn't work:
FindGeneratingFunction[seq, x]
returns the following (which means that it cannot find a solution):
FindGeneratingFunction[{1, 65539, 393225, 1769499, 7077969, 26542323,
95552217, 334432395, 1146624417, 1722371299, 14608041}, x]
But I would have thought that either Solve, Reduce or FindInstance could give some answer:
Solve[{seq[[2]] == Mod[aa * seq[[1]] + bb, mm]
}, {aa, seed, bb, mm} \[Element] Integers]
Nope, it returns:
This system cannot be solved with the methods available to Solve.
What about a little larger equation system:
Solve[{seq[[2]] == Mod[aa * seq[[1]] + bb, mm],
seq[[3]] == Mod[aa * seq[[2]] + bb, mm],
seq[[4]] == Mod[aa * seq[[3]] + bb, mm],
seq[[5]] == Mod[aa * seq[[4]] + bb, mm],
seq[[6]] == Mod[aa * seq[[5]] + bb, mm]
}, {aa, seed, bb, mm} \[Element] Integers]
Same error/warning message. I also tested this with Reduce and FindInstance but they all errors/warnings
Reduce::nsmet: This system cannot be solved with the methods available to Reduce.
and
FindInstance::nsmet: The methods available to FindInstance are insufficient to find the requested instances or prove they do not exist.
I assume it is the Mod function that makes this such a hard problem, or perhaps I just did some simple (or not so simple) mistake. Are there some good principled ways to solve/attack LCGs (in WL)?
|
|
|
Initialization cell to introduce the abbreviation seq ;-)
a = 65539; b = 0; m = 2^31; LCG[seed_Integer] := Mod[a*seed + b, m]; seq = NestList[LCG, 1, 10]
Hello Hakan, If you "help" WL by specifying the bb = 2^31 and the shift bb = 0, you will get an answer:
Solve[{seq[[2]] == Mod[aa*seq[[1]] + 0, 2^31]}, aa \[Element]
Integers]
Even if you omit the shift bb = 0, you get an answer.
Solve[{seq[[2]] == Mod[aa*seq[[1]] + bb, 2^31]}, {aa, bb} \[Element]
Integers]
On the other hand, if you ask for mm, i.e.
Solve[{seq[[2]] == Mod[aa*seq[[1]] + 0, mm]}, {aa, mm} \[Element]
Integers]
your error/warning message will be reproduced. The same happens when you try the toy example
Solve[1 == Mod[15, x], x]
(Edit: Note, that Solve[1 == Mod[15, x], x, Integers] works, and likewise Solve[2022 == Mod[65539, x], x, Integers]. \Edit) But you can get around that by running this:
Table[{k ->
Solve[{seq[[2]] == Mod[aa*seq[[1]] + 0, 2^k]}, {aa} \[Element]
Integers]}, {k, 1, 40}]
By doing so, you get a whole bunch of solutions.... But I think we're moving from the Crypto topic to modulo computation now.... PS: Sorry I didn't post the output here, because the conditional expressions make the result very unreadable here...
|
|
|
Thanks for your insights and suggestions , Lara! Perhaps it make sense that hard coding the value of the modulo works, it might be given in the specification of the used algorithm? Some findings:
Using the hard coded modulo with a single equation takes about 34s on my computer. But if adding one more equation to the system it's faster: about 7s.
Solve[{seq[[2]] == Mod[aa*seq[[1]] + bb, 2^31],
seq[[3]] == Mod[aa*seq[[2]] + bb, 2^31]
}, {aa, bb}, Integers] // AbsoluteTiming
Adding more equations seems to be a little slower: 3 equations takes 7.4s, 4 equations takes 7.5s and 5 equations takes 8s. But there are faster ways: Using Reduce only takes 0.05s:
Reduce[{seq[[2]] == Mod[aa*seq[[1]] + bb, 2^31]}, {aa, bb}, Integers] // AbsoluteTiming
[FindInstance is not that fast and give solutions "all over the place" and I had to add the constraints that aa and bb are non-negative. Here we want 5 solutions.
FindInstance[{seq[[2]] == Mod[aa*seq[[1]] + bb, 2^31], aa >= 0, bb >= 0},
{aa, bb}, Integers, 5] // AbsoluteTiming
Solutions:
{0.467047, {{aa -> 210453397504,
bb -> 785979080717}, {aa -> 188978626658,
bb -> 689342250923}, {aa -> 0,
bb -> 193273593869}, {aa -> 141733986317,
bb -> 0}, {aa -> 128849084491, bb -> 575525617602}}}
] I like the idea of looping through the modulo (2^k) though that assumes that the modulo is always a power of 2, which might very well be correct. Regarding your comment that looping through possible modulo values is leaving the cryptanalysis domain, I would say that we are still in that domain since everything is allowed to get a solution (well , perhaps except for a Kevin Mitnick kind of social engineering :-)). I had hoped that Solve would be of some (more) help here. Again, thanks!
|
|
|
This question may be more related to a future crypto lesson. I was toying around with encrypting/decrypting data (using Mathematica 12.1 functions) with DES, using the "Electronic Cookbook" (ECB) block mode, and was surprised by some obtained results, see below.
I would like to know the reasons of such behaviour, as well as whether it's possible to know and/or control what data padding is being used by default, in these settings? For an (a priori) empty byte array, the encrypted data length is much longer than for a one-byte array:
In[1]:= Encrypt[desKeyECB, ByteArray[{}]]["Data"] // Normal
Out[1]= {238,110,253,99,228,27,8,224,142,28,87,146,1,47,70,240,237,69,176,169,25,122,166,240}
but:
In[2]:= Encrypt[desKeyECB, ByteArray[{0}]]["Data"] // Normal
Out[2]= {177,216,132,168,6,11,203,72}
which is shorter. Finally, while it is known that DES works on 64-bit data chunks, I noticed that the encrypted data's length will increase already the 56-bit 7-byte (i.e. 56-bit)-long data: gives an encrypted block of 64 bits:
In[3]:= Encrypt[desKeyECB, ByteArray[{0, 1, 2, 3, 4, 5, 6}]]["Data"] // Normal
Out[3]= {62,54,162,174,211,50,208,182}
However, 8-byte (i.e. 64-bit)-long data would give a longer encrypted block of 2 x 64 bits:
In[4]:= Encrypt[desKeyECB, ByteArray[{0, 1, 2, 3, 4, 5, 6, 7}]]["Data"] // Normal
Out[4]= {83,131,254,213,181,242,11,15,151,186,160,29,255,217,246,70}
Interestingly, the last 8 bytes in the example above appear to "encode" an empty byte array somehow:
In[5]:= Decrypt[desKeyECB, ByteArray@{151, 186, 160, 29, 255, 217, 246, 70}]
Out[5]= {}
But the empty byte array encrypts differently (see In[1] above).
Finally, modifying one of these 8 bytes in In[5] would make Decrypt[] fail. Why is that so? Does this padding also contain some sort of checksum information?
|
|
|
What you see in In[1] is due to the fact that in Wolfram an empty byte array is actually a list:
In[1]:= ByteArray[{}]
Out[1]= {}
In[2]:= ByteArray[{}] == List[]
Out[2]= True
So since in WL you can encrypt any expression not just bytes or strings this gets treated as expression List[] and serialized as a generic expression. If you really want to encrypt an empty thing try empty string "".
What you see in the inputs 3, 4, and 5 is related to a standard convention on padding, which will be covered in lesson "Block and stream ciphers next week" so I hope you wouldn't mind waiting for that.
|
|
|
Hermes,
I'm not sure what I'm doing wrong, but copying your In[1] statement doesn't work. In your post, as in my attached notebook, the object desKeyECB is marked in blue, meaning Mathematica doesn't understand it. Are you missing a definition of this object in the post? Please clarify?
|
|
|
Ah yes of course! I omitted the definition of desKeyECB; here it is:
desKeyECB =
GenerateSymmetricKey[Method -> <|"Cipher" -> "DES", "BlockMode" -> "ECB"|>];
Note that here I passed the "BlockMode" as parameter to the Method of the GenerateSymmetricKey function (while I kept the Encrypt function without any other parameters). When I did the tests it was when using Mathematica 12.1. As far as I can see, however, they changed some of this stuff and it would now appear that the "BlockMode" should be now passed not to GenerateSymmetricKey, but separately to the Encrypt function instead...
|
|
|
As a question/suggestion: isn't it common to define the term "information security system" for the set of properties i.e. confidentiality, authentication, data integrity, and non-repudiation.
|
|
|
This is a somewhat simple-minded check for English words which result in other English words when encrypted with the Caesar Cipher (and only using a shift of 3 characters). It considers a word valid if it is contained in the "common words" returned by WordList[]. The results would be different if DictionaryWordQ[] was used to validate the result.
CCipher[x_String, offset_Integer : 3] :=
Mod[LetterNumber[x] + offset - 1, 26] + 1 // FromLetterNumber // StringJoin
Attributes[CCipher] = Listable;
CCipher[WordList[]]\
// Intersection[#, WordList[]] & \
// Thread[CCipher[#, 23] -> #] & \
{"alb" -> "doe", "ark" -> "dun", "be" -> "eh", "box" -> "era",
"bob" -> "ere", "bod" -> "erg", "boo" -> "err", "cold" -> "frog",
"dory" -> "grub", "ex" -> "ha", "elm" -> "hop", "ere" -> "huh",
"fa" -> "id", "fob" -> "ire", "folk" -> "iron", "ill" -> "loo",
"lab" -> "ode", "lob" -> "ore", "milt" -> "plow", "molt" -> "prow",
"orb" -> "rue", "pee" -> "shh", "pelt" -> "show", "perk" -> "shun",
"ply" -> "sob", "pry" -> "sub"}
Update: After I posted this code, I read Michael Schreiber's solution which used StringReplace rather than LetterNumber and FromLetterNumber and wondered about the relative efficiency of the approaches. I changed my code to use Michael's approach and the the speed increased by a factor of more than 60. Thank you Michael for demonstrating this approach. Updated code:
rules = Thread[Rule[Alphabet[], RotateLeft[Alphabet[], offset]]];
rulesRev = Thread[Rule[Alphabet[], RotateLeft[Alphabet[], 26 - offset]]];
wl = WordList[] // ToLowerCase;
StringReplace[#, rulesRev] -> # & /@
Intersection[wl, StringReplace[wl, rules]]
|
|
|
A longer list. DictionaryWordQ has more words than WordList.
WordList[] //
AssociationMap[ResourceFunction["CaesarCipher"][#, 3] &] //
Select[DictionaryWordQ]
|
|
|
The SIGSALY used the heat of giant vacuum tubes as a source of noise, but I've also come
across how-to guides for using a reverse-biased zener diode to produce "shot noise",
apparently something to do with total, natural randomness of quantum tunneling, don't ask me! [LINK] A Fast, Cheap, High-Entropy Source for IoT Devices
Thanks for mentioning this. It is possible to "deplete the entropy pool" when doing more business than usual, so HWRNG are worthwhile "weird machines", which could be studied in their own right. How do you think graphene sheets could / should be adapted to this purpose? : : Vacuum tubes can still be used for some fun experiments on the photoelectric effect, or if you have excess medical grade equipment, possibly for making Geiger counters. However, as you've said, much of more recent technology has already shifted toward diodes and laser diodes, which are also incredible little devices for any hobbyist's citizen lab. Have Fun! --Brad
|
|
|
I think there was a lot of interest (including my own!) in the Q&A around random number generation now and historically. I decided I will list a few things I've come across and welcome any other clever ways you've seen to generate real randomness, starting with a relevant crypto-stack-exchange question:
How were one-time pads and keys historically generated? One of the answers mentions SIGSALY, wherein the US Army awarded Bell Labs (with Alan Turing & Claude Shannon in their employ) a contract to build a system for encrypted radio calls in 1942, using vinyl records of digitized noise as the one-time-key, employing a source of true entropy and making use of the newly invented vo-coder to minimize the data that needed to be encoded, simultaneously inventing voice compression. The podcast "99% Invisible" has a great episode:
The SIGSALY used the heat of giant vacuum tubes as a source of noise, but I've also come across how-to guides for using a reverse-biased zener diode to produce "shot noise", apparently something to do with total, natural randomness of quantum tunneling, don't ask me!
A talk on squeezing games into the extreme constraints of the 8 bit Nintendo, including some tiny algorithms to introduce a little entropy to make the game a little less predictable (starting at 19:25). Tetris uses xor + shift on a 16 bit fibonacci sequence. Final Fantasy uses a lookup table of 256 precomputed random values. Contra uses spare cpu cycles to increment a variable that is used whenever a random number is desired.
And of course our man Wolfram figured out you can use Cellular Automata as good sources of entropy (default in mathematica) links thanks to Q&A staff (sorry I missed your name!)
|
|
|
Common words appearing as cypher texts of common words when using Caesar Cyphers
With[{
alpha = ToUpperCase[Alphabet[]],
enCommon = Select[
Union[ToUpperCase[WordList[]]],
Complement[Characters[#], alpha] == {} &]},
SortBy[
Table[
shift -> Intersection[
enCommon,
StringReplace[enCommon,
Thread[Rule[alpha, RotateLeft[alpha, shift]]]]
],
{shift, 25}],
Length[Last[#]] &]]
{5 -> {"FIE", "FIT", "IT", "ITS", "KNEE", "PH", "STY", "UM", "YA"},
21 -> {"ADO", "ADZ", "DO", "DON", "FIZZ", "KC", "NOT", "PH", "TV"},
2 -> {"CUR", "DAG", "ETA", "GAG", "GO", "IQ", "KEG", "ME", "MY",
"NAG", "OW", "TAG", "TWO", "URGE"},
24 -> {"ASP", "BYE", "CRY", "EM", "EYE", "GO", "ICE", "KC", "KW",
"LYE", "MU", "RUM", "RYE", "SPEC"},
1 -> {"BE", "BEE", "BIB", "BY", "DIBS", "EVE", "FOE", "IF", "IN",
"JUT", "KPH", "OFF", "PEE", "PI", "PIN", "PIP", "SIP", "TI", "UFO",
"UP"},
25 -> {"AD", "ADD", "AHA", "AX", "CHAR", "DUD", "END", "HE", "HM",
"ITS", "JOG", "NEE", "ODD", "OH", "OHM", "OHO", "RHO", "SH", "TEN",
"TO"},
9 -> {"AN", "ANY", "ARENA", "ARK", "ARM", "BRA", "BRAN", "BUNNY",
"BURY", "BYRE", "CANT", "CARP", "CRY", "DB", "KHAN", "LARK", "NAN",
"NAP", "NUT", "PRAM", "RAT", "RUT", "TRY", "URN", "WRY"},
17 -> {"BYRE", "CRIB", "ELK", "ERE", "ERG", "GIRD", "ILK", "IRK",
"KIP", "LIE", "NIP", "RE", "REP", "RIB", "RID", "RIVER", "SIR",
"SIRE", "SLEEP", "SLIP", "SPIV", "TIP", "TREK", "TRIG", "US"},
11 -> {"ALE", "ALTO", "APE", "AS", "AT", "DALE", "DATE", "DAZE",
"DAZED", "DEFY", "ELF", "ELM", "ESPY", "ETA", "EYE", "FA", "IT",
"LAP", "LO", "LOO", "LYE", "PI", "SPA", "SPY", "STOP", "TO", "YES",
"ZOO"},
15 -> {"AD", "ADD", "ANT", "APE", "EX", "HEN", "HEP", "HIDE", "ID",
"NTH", "ODD", "PAID", "PAT", "PET", "PH", "PI", "SPAT", "SPIT",
"SPOT", "SPOTS", "STUN", "TAB", "TAU", "THEN", "TIP", "TNT", "UP",
"XI"},
3 -> {"DOE", "DOS", "DUN", "EH", "ERA", "ERE", "ERG", "ERR", "FROG",
"GRUB", "HA", "HOP", "HUH", "ID", "IRE", "IRON", "KHZ", "LOO",
"ODE", "ORE", "PH", "PLOW", "PROW", "RUE", "SHH", "SHOW", "SHUN",
"SOB", "SUB"},
23 -> {"ALB", "ALP", "ARK", "BE", "BOB", "BOD", "BOO", "BOX", "COLD",
"DORY", "ELM", "ERE", "EX", "FA", "FOB", "FOLK", "HEW", "ILL",
"LAB", "LOB", "ME", "MILT", "MOLT", "ORB", "PEE", "PELT", "PERK",
"PLY", "PRY"},
13 -> {"AH", "AHA", "ANT", "BALK", "BAR", "CRAG", "CREEL", "ENVY",
"ER", "FLAP", "FUR", "GAG", "GEL", "GNAT", "IRK", "NAG", "NU",
"NUN", "ONE", "ONYX", "PENT", "PERRY", "RAIL", "RE", "SHE", "SYNC",
"TANG", "TNT", "TRY", "VEX"},
7 -> {"AH", "AHA", "ALL", "APTLY", "DOLL", "DOPA", "FLAP", "FLU",
"GLIB", "HA", "HE", "HO", "IF", "ILK", "ILL", "JOLLY", "LO", "NUB",
"OBI", "OH", "OLD", "OPT", "PA", "PILE", "SH", "SHALE", "SHE",
"SPA", "SPUR", "THY", "VIP", "WHO", "WHY", "WOLD", "ZOO"},
19 -> {"AH", "AT", "AX", "BED", "BEE", "BY", "CHEER", "EH", "GNU",
"HA", "HEW", "HIM", "HUB", "IBEX", "IT", "LA", "LATEX", "LAX",
"LINK", "LIT", "MAR", "OBI", "PAH", "PAR", "PHEW", "SHH", "TA",
"TAT", "TEE", "TIMER", "WHEE", "WHIT", "YEN", "YETI", "ZEBU"},
8 -> {"AIL", "AWE", "AWL", "BIAS", "BIB", "BIZ", "CAM", "COP", "EM",
"EMIT", "EWE", "I", "IF", "ILL", "JIB", "JIG", "MOIL", "MOO",
"MOW", "MU", "NIB", "NIL", "OIL", "OW", "OWL", "PI", "PIE", "PIG",
"PIX", "RIG", "SPIV", "TI", "TIE", "TWIN", "TWO", "UM", "WE",
"WET", "WIN", "XI", "ZIP"},
18 -> {"A", "ADD", "AX", "BAT", "BAY", "EGAD", "EGG", "EGO", "EM",
"FAD", "FAT", "GAD", "GO", "GOD", "HA", "HAP", "HAW", "HAY", "JAY",
"KHAN", "LA", "LAW", "LOAF", "LOG", "ME", "OAF", "OW", "OWL",
"PA", "RAH", "SAD", "SOD", "SOW", "TAR", "TASK", "TAT", "UGH",
"USE", "WE", "WEAL", "WOW"},
10 -> {"BED", "BONY", "BOON", "BOP", "COD", "COG", "COO", "COWS",
"CRED", "DEW", "DRY", "DYED", "GO", "GOD", "GOO", "GOON", "GROG",
"KC", "KW", "LEI", "LIDO", "LO", "LOO", "LOOP", "MEN", "MONO",
"NOON", "OH", "OW", "OWE", "OX", "POI", "POX", "RED", "ROB", "ROW",
"SNOW", "UM", "WE", "WEN", "WOOD", "ZED", "ZOO"},
16 -> {"AM", "AS", "BE", "BEE", "BEEF", "BUY", "BYTE", "CEDE", "CUD",
"DEED", "EM", "EMU", "EN", "EX", "FEN", "FEY", "HEM", "HER",
"HUT", "IDEM", "KC", "MEET", "MU", "MUD", "PEE", "PUT", "REDO",
"REED", "REF", "RUT", "SEE", "SEMI", "SET", "SEW", "SHUT", "THO",
"TOUT", "TUM", "WE", "WEE", "WEED", "WET", "WHEW"},
4 -> {"AIR", "EAR", "EEL", "EH", "EPOCH", "ER", "EX", "FEE", "FER",
"FIX", "GET", "HEAR", "HERO", "IQ", "JERK", "KEPI", "KIP", "LEA",
"LET", "LIT", "MU", "NIX", "OLD", "PEA", "PEAR", "PEG", "PET",
"PIE", "PIER", "PIX", "PSST", "REF", "SAP", "SHH", "STEP", "STIR",
"TEA", "TEAR", "TEMP", "TIE", "TIGER", "TYRO", "VET", "VEX", "WEB",
"WET"},
22 -> {"AAH", "AD", "ALKYD", "AN", "AT", "AWN", "BAA", "BAN", "BET",
"CAP", "DANK", "DAWN", "EM", "FANG", "GALE", "GEL", "HAP", "HAW",
"HEP", "IQ", "JET", "KHZ", "LAC", "LAP", "LAW", "LAWN", "LEA",
"LEAN", "LET", "LOOP", "NAB", "ODD", "OPAL", "OPEN", "OWL", "PAIL",
"PAW", "PAWN", "PEA", "PECAN", "PUNK", "RAP", "RAT", "SAP", "SAX",
"WEN"},
12 -> {"AT", "BAP", "BEEF", "BUS", "DAMP", "DUB", "DUN", "FA", "FAB",
"FAD", "FAY", "FAZE", "HUB", "HUM", "IMP", "IQ", "ME", "MEW",
"MIX", "MUD", "MY", "NAB", "NAN", "NAP", "NUN", "OAF", "OAK", "PA",
"PAPA", "PAS", "PUB", "PUP", "PUS", "RAJ", "RUN", "SANE", "SAP",
"SKY", "SURF", "TA", "TAB", "TAN", "TAP", "TUB", "UP", "VAN",
"YAP", "YE", "ZAP"},
14 -> {"AIR", "AM", "AS", "ASK", "AWL", "BIB", "BOB", "BOD", "BOP",
"COT", "COY", "DID", "DIG", "DIP", "DO", "DODO", "DOG", "FIB",
"FOX", "GIFT", "GOBS", "GOD", "GYM", "HIP", "HO", "HOB", "HOD",
"HOP", "ID", "JOB", "MOD", "MS", "NOD", "OH", "PIG", "POD", "PSST",
"RIB", "RIP", "ROAD", "TO", "TOM", "TONS", "TOP", "TOR", "VIA",
"VIP", "WAD", "WE"},
6 -> {"AS", "BOG", "CORE", "CORK", "COT", "COTE", "COZY", "CURL",
"CUT", "DO", "HAJ", "HALL", "HAM", "HAS", "HAT", "HAY", "HE",
"HOT", "HUE", "HUG", "HUH", "HUM", "HUSH", "INGOT", "JAM", "JOT",
"JUT", "LAM", "LATTE", "LAX", "LAYOUT", "LOT", "LOX", "MALL",
"MARL", "MAT", "MATTE", "MOM", "MOT", "MU", "NAN", "NEST", "NO",
"NOB", "NU", "OUT", "OW", "PARE", "POSSE", "PUNT", "RAM", "ROUT",
"RUIN", "RUM", "SATIN", "SO", "SOD", "TA", "TAT", "TOR", "TUT",
"TUX", "VAT", "WAG", "WAGE", "YAK", "YETI"},
20 -> {"BIN", "BOA", "BOB", "BOG", "BOMB", "BOY", "BUD", "BUFF",
"BUG", "BUM", "BUN", "BUS", "BY", "CHAIN", "DIN", "DON", "DUG",
"FIN", "FIR", "FUG", "FUNNY", "FUR", "FUSION", "GIG", "GIN", "GO",
"GUFF", "GULF", "GUN", "GUNNY", "HI", "HIV", "HO", "HUH", "HYMN",
"ION", "IQ", "JIMMY", "JOHN", "JULY", "LION", "LOCH", "LOG", "LUG",
"MI", "MIX", "MUNCH", "NIL", "NON", "NOR", "NU", "NUN", "PUN",
"QUA", "QUAY", "SUE", "SYNC", "UM", "VIA", "WILE", "WILY", "WIN",
"WINY", "WITS", "WOLF", "WON", "XI"}}
|
|
|
Here is my more "formal" analysis of this, assuming that the first word should be in Mma's Latin wordlist.
text = "yhql ylgl ylfl";
alpha = Alphabet[];
latinWords = WordList["KnownWords", Language -> "Latin"];
candidates = {StringReplace[text,
Thread[Rule[alpha, RotateLeft[alpha, #]]]]} & /@ Range[26];
MemberQ[latinWords, StringSplit[#][[1, 1]]] & /@ candidates;
Pick[candidates, %]
Update: Changed an old "A" to "alpha". Thanks, Luis!
|
|
|
Nice, just a corretion in the code (A -> alpha)
Thread[Rule[alpha, RotateLeft[alpha, #]]]]} & /@ Range[26];
Update: Code is already corrected in original post.
|
|
|
Thanks, Luis. I've changed it in my post. The code is based on the one in the "04Classicalciphers.nb", but in the last minute changed "A" to "alpha" since it's not recommended that variables start with an uppercase. But forgot to change it everywhere. :-)
|
|
|
You're welcome, I just notice the "A" out of place and tested the code. :-)
|
|
|
Table[ResourceFunction["CaesarCipher"]["yhql ylgl ylfl", i], {i, 1, 26}]
shows the decrypted message in item 23.
|
|
|
As Caesar encrypted with a shift of 3, shifting by 23 will decrypt
CaesarCipher["yhqlylglylfl", 23] Producing a famous quote from Caesars Gallic Wars.
|
|
|
YHQL YLGL YLFL = VENI VIDI VICI "I came, I saw, I conquered"
|
|
|
It helped to notice that it was three words of four characters that start with the same character (and a lot of "L"). It cannot be "alea iacta est" or "aut Caesar aut nihil" for that reason. :-) Though I did a brute force to confirm it.
|
|
|
Another take on this, though it might be overkill for this problem. But let's say that - for some reason - we don't want to test all the possible Caesar shifts, for example if they are too costly Then we can use the observation that the letter "l" is more frequent than the other letters:
text = "yhql ylgl ylfl";
CharacterCounts[text]
This shows that "l" is most frequent character.
<|"l" -> 5, "y" -> 3, " " -> 2, "f" -> 1, "g" -> 1, "q" -> 1, "h" -> 1|>
What will be the first substitute to test, i.e. what is the commonest character in Latin? Unfortunately, there is no letter frequency for Latin in WL:
LanguageData["Latin", "LetterFrequency"]
outputs Missing["NotAvailable"] So we have to roll our own:
latinWords = WordList["KnownWords", Language -> "Latin"];
CharacterCounts[StringJoin[latinWords]]
which outputs the following, showing that the character "i" is the most common character in Latin.
<|"i" -> 6307, "e" -> 6008, "s" -> 5359, "a" -> 5324, "u" -> 5276,
"o" -> 5189, "r" -> 5013, "t" -> 4035, "n" -> 3395, "c" -> 3240,
"l" -> 2763, "m" -> 2490, "p" -> 2220, "d" -> 1609, "b" -> 1004,
"g" -> 946, "f" -> 896, "v" -> 869, "h" -> 469, "x" -> 409,
"q" -> 363, "y" -> 97, "æ" -> 94, "j" -> 51, "C" -> 38, "A" -> 34,
"H" -> 19, "M" -> 16, "z" -> 13, "I" -> 12, "T" -> 11, "P" -> 11,
"B" -> 10, "S" -> 9, "R" -> 8, "L" -> 8, "V" -> 6, "G" -> 6,
"*" -> 5, "O" -> 4, "F" -> 4, "N" -> 3, "E" -> 3, "D" -> 3, "k" -> 3,
"Æ" -> 3, "Z" -> 2, "\[Hyphen]" -> 2, "U" -> 1, "-" -> 1, "Q" -> 1|>
Let's now use this knowledge to first test the shift that replaces an "i" with "l":
alpha = Alphabet[];
shift = LetterNumber["i"] - LetterNumber["l"];
keytable = Thread[Rule[alpha, RotateLeft[alpha, shift]]];
StringReplace["yhql ylgl ylfl", keytable]
Which happens to be the correct one:
veni vidi vici
Note: The shift found is -3 which is the same as shift 23 (26 + -3 = 23).
|
|
|
Three years of Latin in high school helped confirm my decryption and translation. Good fun!
|
|
|
please make test bigger on Zoom lecture now
|
|
|
Ahead of the presentation, I am hopeful that the explanation of RSA will include an examination of its usage in SSL, i.e., how is it employed to exchange the symmetric key?
|
|
|
This will be covered more ahead in Hybrid Cryptography lesson.
|
|
|
For anyone interested in seeing actual historical equipment, the NSA runs the National Cryptological Museum in Maryland. It has an amazing collection from ancient times through Cold War to modern times including Enigmas and they have the only surviving Bombe (the machine designed at Bletchley Park to decrypt Enigma -- the British destroyed all of theirs and had to rebuild one for their recently opened Bletchley Park museum).
|
|
|
Interesting historical perspective of cryptography from day 1 - looking forward to the next sessions!
|
|
|
Over 200 attendees joined the first session of this study group today. Thanks @Dariia Porechna for your presentation. Thanks to the attendees for remaining engaged throughout the session. Looking forward to the rest of the series.
|
|
|
Reply to this discussion
in reply to
|


